
Python'da Tarayıcı PDF'den Metin Çıkarma
Özellikle taranmış olan PDF dosyalarından metin çıkarmak zorlayıcı olabilir. Ancak, doğru araçlar ve tekniklerle bu süreç basitleştirilebilir. Bu eğitici rehber, taranan bir PDF dosyasından metin çıkarmak için bir Python kütüphanesi olan IronPDF'i kullanmayı gösterecektir. Bu makale, ortamınızı kurmanın, optik karakter tanıma (OCR) uygulamanın ve etkili metin çıkarmanın nasıl yapılacağını ele alacaktır.
1. IronPDF'e Giriş
 Python PDF Kütüphanesi
Python PDF Kütüphanesi
IronPDF, Python ortamında PDF işleme ve yönetimi için tasarlanmış çok yönlü ve güçlü bir kütüphanedir. Python uygulamaları ile sorunsuz bir şekilde birleşebilme kabiliyeti ile tanınan IronPDF, temel PDF okuma ve yazma işlemlerinin ötesinde çok çeşitli işlevler sunmaktadır. HTML'den PDF'ye dönüştürme, web sayfalarından veya ham HTML kodlarından PDF belgeleri oluşturma ve mevcut PDF dosyalarını düzenleme yeteneği ile dikkat çekmektedir.
Ayrıca, Optik Karakter Tanıma (OCR) özelliği, özellikle taranan PDF belgelerinden metin çıkarmak için çok uygundur. Geliştiricilerin çeşitli PDF ile ilgili görevlerle uğraşırken tercih ettiği bir araçtır. PDF dosyalarından veri çıkarmak, oluşturmak veya değiştirmek için olsun, IronPDF, Python geliştiricilerinin çeşitli uygulamalarında ihtiyaçlarına yönelik sağlam ve güvenilir bir çözümdür.
2. Gereksinimler
PDF'lerden metin çıkarma işlemine başlamadan önce, bazı gereksinimlerin ve gerekli kütüphanelerin yerinde olduğundan emin olmak önemlidir. Bu, ilerledikçe sorunsuz ve etkili bir iş akışı sağlayacaktır.
- Python Ortamı: Bilgisayar sisteminize Python kurulu olduğundan emin olun. Python, çok yönlü bir programlama dilidir ve geniş kütüphane desteği ile metin çıkarma gibi görevler için idealdir. Python'u henüz yüklemediyseniz, resmi Python websitesinden bilgisayarınıza indirin. İşletim sisteminizle uyumlu bir Python sürümü indirdiğinizden emin olun.
- .NET 6.0 SDK Kurulumu: IronPDF for Python, .NET 6.0 üzerine inşa edilmiş olan IronPDF .NET kütüphanesini kullandığından dolayı, sisteminizde .NET 6.0 SDK yüklü olmalıdır. Bu SDK, IronPDF kütüphanesinin doğru çalışabilmesi için gerekli çalışma zamanını ve kütüphaneleri sağlar. .NET 6.0 SDK'yı resmi Microsoft .NET web sitesinden indirip kurabilirsiniz.
- IronPDF for Python Kütüphanesi: IronPDF, Python'da PDF belgeleri ile çalışmak için sağlam bir kütüphanedir. Sadece metin çıkarımını kolaylaştırmakla kalmaz, aynı zamanda PDF oluşturma, düzenleme ve dönüştürme gibi işlevsellikler de sunar.
- Tarayıcı PDF Belgesi: Metin çıkarmak için taranmış bir PDF belgesine sahip olun. Bu belge ideal olarak net ve okunabilir olmalıdır, çünkü taranan PDF'nin kalitesi, OCR ve çıkarılan metnin doğruluğunu önemli ölçüde etkileyebilir.
- Temel Python Anlayışı: Python programlamanın temel bir anlayışı faydalı olacaktır. Değişkenler, döngüler ve temel dosya işlemleri gibi kavramlara aşina olmak, kodu anlamanızı ve metin çıkarma sürecinde daha etkili olmanızı sağlayacaktır.
- Uygun Bir Geliştirme Ortamı: Kesinlikle gerekli olmamakla birlikte, Visual Studio Code, PyCharm veya Jupyter Notebook gibi bir geliştirme ortamına sahip olmak, kodlama deneyimini daha yönetilebilir hale getirebilir. Bu ortamlar, Python betiğiyle çalışırken aşırı derecede yararlı olan sözdizimi vurgulama, kod tamamlama ve hata ayıklama araçları gibi özellikler sunar.
Bu gereksinimlerle, IronPDF for Python kütüphanesi kullanarak taranmış PDF belgelerinden metin çıkarmak için iyi bir şekilde hazırlıklısınız. Sonraki adımlar, IronPDF'i kurma, PDF belgenizi yükleme, OCR uygulama, metin çıkarma ve spesifik ihtiyaçlarınız için çıkarılan verileri kullanma süreçlerini gösterecektir.
3. Tarama PDF'den Metin Çıkarmak için Adım Adım Kılavuz
Adım 1: IronPDF'i Yükleyin
İlk önce, Python ortamınıza IronPDF Python kütüphanesini yüklemelisiniz. Bu genellikle Python'un paket yöneticisi pip kullanılarak yapılır. Komut satırı arayüzünüzü açın ve aşağıdaki komutu çalıştırın:
pip install ironpdf
 IronPDF paketini kurun
IronPDF paketini kurun
Adım 2: IronPDF'i İçe Aktarın
Kurulumdan sonra, IronPDF kütüphanesini Python betiğinize içe aktarın. Bu adım, IronPDF tarafından sağlanan işlevlere erişmek için önemlidir:
import ironpdfimport ironpdfIronPDF'i içe aktararak, artık betiğinizdeki sınıf ve yöntemlerini kullanabilirsiniz.
Adım 3: Lisans Anahtarınızı Uygulayın
IronPDF, tam işlevsellik için bir lisans anahtarı gerektirir. Eğer bir lisans satın aldıysanız, lisans anahtarınızı şu şekilde uygulayın:
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE""YOUR-LICENSE-KEY-HERE" ifadesini gerçek IronPDF lisans anahtarınızla değiştirin. Bu adım, IronPDF'in tüm özelliklerini herhangi bir sınırlama olmaksızın açmak için gereklidir.
Adım 4: Tarayıcı PDF Dosyasını Yükleyin
Metin çıkarmak için, önce PDF belgesini betiğinize yükleyin:
pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")Burada, "scannedpdf.pdf" ifadesi işlemeyi düşündüğünüz PDF belgesinin gerçek dosya yolu ile değiştirilmelidir. Bu komut, PDF dosyasını okur ve metin çıkarmaya hazır hale getirir.
Adım 5: PDF Dosyasından Metin Çıkar
PDF yüklendikten sonra, IronPDF'nin ExtractAllText() yöntemini kullanarak, aşağıdaki kodda gösterildiği gibi metni çıkarabilirsiniz:
text = pdf.ExtractAllText()text = pdf.ExtractAllText()Bu kod satırı, tüm PDF belgesini işler ve metin içeriğini çıkararak text değişkenine kaydeder.
Adım 6: Çıkarılan Metni İşleyin ve Kullanın
Çıkarmadan sonra, metin verileri text değişkeninde kullanılabilir durumdadır. Bu metni konsola yazdırabilir veya ihtiyaçlarınıza göre daha fazla işleyebilirsiniz:
print(text)
# Additional code here to process or utilize the extracted textprint(text)
# Additional code here to process or utilize the extracted textBu adım, çıkarılan metni bir dosyaya kaydetme, metin verileri analizi yapma veya bunları bir veritabanı veya web uygulamasına entegre etme gibi çeşitli işlemleri içerebilir. Yukarıdaki kodun çıktısını burada görebilirsiniz.
ÇIKTı Metin
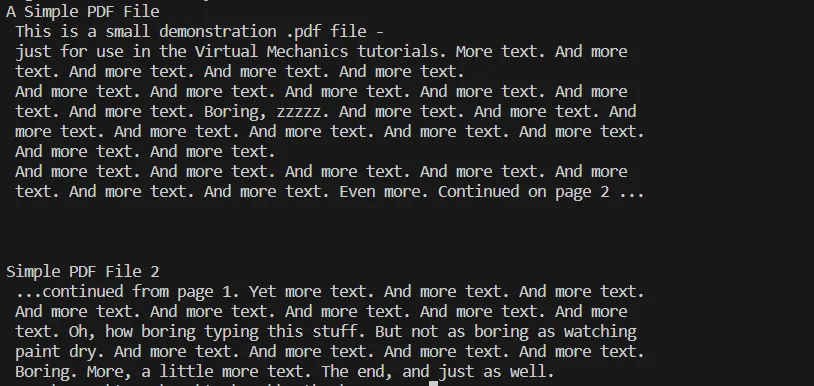 PDF dosyasından metin çıkarma sürecinin konsol çıktısı
PDF dosyasından metin çıkarma sürecinin konsol çıktısı
Adım 7: Ek İşlemler (İsteğe Bağlı)
IronPDF'in yetenekleri metin çıkarmanın ötesine geçer. Projenizin gereksinimlerine bağlı olarak, PDF'leri düzenleme, farklı formatlara dönüştürme veya HTML'den PDF üretme gibi ek özellikleri keşfedebilirsiniz.
4. İleri Teknikler
4.1 Metin Olmayan Öğeleri Ele Alma
Taranmış PDF'ler genellikle resimler veya grafikler gibi metin olmayan öğeler içerir. OCR metin üzerine odaklanırken, bu öğeleri farklı bir şekilde ele almak isteyebilirsiniz. Metin olmayan içerikleri işlemek veya görmezden gelmek için ek Python kütüphanelerine ihtiyaç duyabilirsiniz.
4.2 OCR Doğruluğunu Artırma
Metin çıkarma doğruluğu, taranmış belgelerin kalitesine bağlı olarak değişebilir. OCR sonuçlarını iyileştirmek için taranan PDF'nizin yüksek kaliteli ve metnin olabildiğince net olduğundan emin olun.
4.3 Diğer Formatlara Dönüştürme
PDF'den metin çıkardıktan sonra, bu metni CSV, JSON veya XML gibi diğer formatlara dönüştürmek isteyebilirsiniz. IronPDF, bu tür dönüşümleri sağlar ve size esnek veri işleme seçenekleri sunar.
5. Sık Karşılaşılan Sorunların Çözümü
OCR ve metin çıkarma ile çalışırken şu tür sorunlarla karşılaşabilirsiniz:
- Düşük kaliteli taramalar nedeniyle düşük OCR doğruluğu.
- Bazı karakterlerin OCR tarafından tanınamaması nedeniyle eksik metin.
- Büyük PDF dosyalarını yüklerken hatalar.
Bu sorunları çözmek için taralı PDF dosyalarınızın net ve yüksek kaliteli olduğundan emin olun, büyük dosyaları daha küçük parçalara ayırmayı düşünün ve IronPDF kütüphanenizin güncel olduğundan emin olun.
Sonuç
Tarayıcı PDF dosyasından metin çıkarmak, IronPDF Python kütüphanesini kullanarak sorunsuzca gerçekleştirilebilir. Bu öğreticide açıklanan adımlarla, aranabilir olmayan bir taranan belgeyi hızlı ve kolayca işlenebilir ve analiz edilebilir metin açısından zengin bir formata dönüştürebilirsiniz. Her PDF sayfasını dikkatlice ele almayı ve taranmış PDF'nizi aranabilir bir PDF dosyasına dönüştürmek için OCR uygulamayı unutmayın. Çıkardığınız metin ile, veri manipülasyonu ve kullanımı için geniş imkanlar bulunmaktadır; bu da yenilikçi çözümler ve verimli iş akışları için yolu açar.
Özetlemek gerekirse, bu makale IronPDF'in kurulumu ve ayarlanması, PDF dosyalarının yüklenmesi, bir taranmış PDF'yi aranabilir hale getirmek için OCR teknolojisinin uygulanması, gerçek metin çıkarma süreci ve birden fazla PDF sayfasının ele alınmasını kapsadı. Ayrıca ileri tekniklere değinildi ve sık karşılaşılan sorunların çözümü ele alındı. Bu bilgi ile Python kullanarak PDF belgelerinden metin verisi çıkarabilirsiniz.
IronPDF, PDF manipülasyonu ve metin çıkarım yeteneklerini değerlendirmeye olanak tanıyan ücretsiz bir deneme sunar. Denemeden sonra, ücretli lisans $999 ile başlar, profesyonel ve ticari kullanım için kapsamlı bir özellik seti sunar. IronPDF, geliştirme için ücretsizdir ve geliştiricilerin uygulama geliştirme aşamasında işlevselliklerini bütünleştirmeleri ve test etmelerine olanak tanır.
Sıkça Sorulan Sorular
Python kullanarak taranmış PDF'lerden metin çıkarmak için ortamımı nasıl ayarlarım?
Ortamınızı ayarlamak için, .NET 6.0 SDK'sını ve IronPDF kütüphanesini Python'un paket yöneticisi ile pip install ironpdf kullanarak kurun. Bir Python ortamına ve Visual Studio Code veya PyCharm gibi uygun bir geliştirme ortamına sahip olun.
Optik Karakter Tanıma (OCR) nedir ve Python'da nasıl uygulanır?
Optik Karakter Tanıma (OCR), taranan kağıt belgeler veya PDF'ler gibi farklı türlerdeki belgeleri düzenlenebilir ve arama yapılabilir verilere dönüştürmek için kullanılan bir teknolojidir. Python'da, IronPDF kullanarak bir taranmış PDF'yi yükleyip kütüphanenin OCR işlevlerini kullanarak metin çıkarımı uygulayabilirsiniz.
Taralı PDF'lerden nasıl en iyi şekilde doğru metin çıkarabilirim?
Doğru metin çıkarımını sağlamak için, yüksek kaliteli taranmış PDF'ler kullanın, çünkü OCR doğruluğu daha net ve daha iyi kalitedeki taramalarla artar. IronPDF ile metin çıkarmak için OCR uygulayabilir ve gerektiği şekilde işleyebilirsiniz.
IronPDF kullanarak bir taranmış PDF'den metin çıkarmak için hangi adımlar yer alıyor?
Adımlar arasında IronPDF'nin kurulması, kütüphanenin içe aktarılması, lisans anahtarının uygulanması, taranmış PDF'nizin yüklenmesi, OCR uygulanması ve metni çıkarmak için ExtractAllText() yönteminin kullanılması yer alır.
Çıkarılan metni CSV, JSON veya XML gibi formatlara dönüştürebilir miyim?
Evet, taranmış bir PDF'den metin çıkarıldıktan sonra, veri analizi veya veri manipülasyonu için daha ileri analiz yapmak amacıyla CSV, JSON veya XML gibi çeşitli formatlara dönüştürebilirsiniz.
Metin çıkarma başarısız olursa, yaygın sorun giderme adımları nelerdir?
Metin çıkarma başarısız olursa, taranan PDF'nin kalitesini kontrol edin. IronPDF'nin doğru bir şekilde yüklendiğinden ve geliştirme ortamınızın düzgün kurulduğundan emin olun. Ayrıca, doğru yöntemler ve OCR işlevlerinin kullanıldığını doğrulayın.
IronPDF için deneme sürümü mevcut mu?
Evet, IronPDF, kullanıcıların yeteneklerini test etmeleri için ücretsiz bir deneme sürümü sunar. Deneme süresinin ardından tam işlevsellik için ücretli bir lisans gereklidir.
















