Comment ouvrir un fichier PDF en Python
Cet article va plonger dans le domaine fascinant de l'utilisation d'IronPDF for Python, en explorant comment cette puissante bibliothèque permet une manipulation transparente des PDF, permettant aux développeurs de créer, éditer et transformer des documents sans effort. Découvrez les myriades de possibilités qui vous attendent alors que vous vous lancez dans votre aventure d'édition de PDF en Python.
Comment ouvrir des fichiers PDF en Python
- Téléchargez et installez la bibliothèque IronPDF for Python.
- Utilisez l'objet
PdfDocumentpour charger les fichiers PDF existants. - Générez un PDF à partir d'une chaîne HTML en utilisant la méthode
RenderHtmlAsPdf. - Enregistrez le PDF en utilisant la méthode
SaveAs. - Ouvrez le fichier PDF dans le navigateur par défaut en utilisant
webbrowser.
1. IronPDF for Python
IronPDF est une bibliothèque Python révolutionnaire, débordante de puissance et d'une richesse de fonctionnalités qui redéfinit la façon dont les développeurs interagissent avec les fichiers PDF. En exploitant la puissance des technologies C# et .NET, IronPDF s'intègre parfaitement à Python, offrant une suite complète de fonctionnalités avancées pour créer, éditer et manipuler des documents PDF sans effort. Ses fonctionnalités vont de la génération de rapports et de formulaires PDF dynamiques et visuellement frappants à l'extraction sans effort de données précieuses à partir de fichiers PDF préexistants, en passant par la capacité de faire pivoter les pages PDF et de permettre aux utilisateurs de fusionner des fichiers PDF. IronPDF permet aux développeurs d'exploiter pleinement le potentiel de Python en matière de manipulation de PDF. Cet article se lance dans un voyage pour explorer les capacités impressionnantes d'IronPDF for Python, révélant comment cette remarquable bibliothèque simplifie les tâches liées aux PDF et élève l'expérience de développement globale, permettant la création transparente de documents de qualité professionnelle en toute simplicité. Que vous soyez un développeur chevronné ou un nouveau venu en Python, préparez-vous à être étonné par les possibilités infinies qu'IronPDF apporte sur la table.
2. Installer IronPDF for Python
Cette section discutera de la façon dont vous pouvez installer IronPDF for Python.
- Créez un nouveau projet Python sur PyCharm ou ouvrez-en un existant.
- Ouvrez le terminal dans l'environnement créé pour le projet spécifique. Cela garantit que les packages que vous installez sont isolés au projet et n'interfèrent pas avec d'autres projets ou l'environnement Python global.
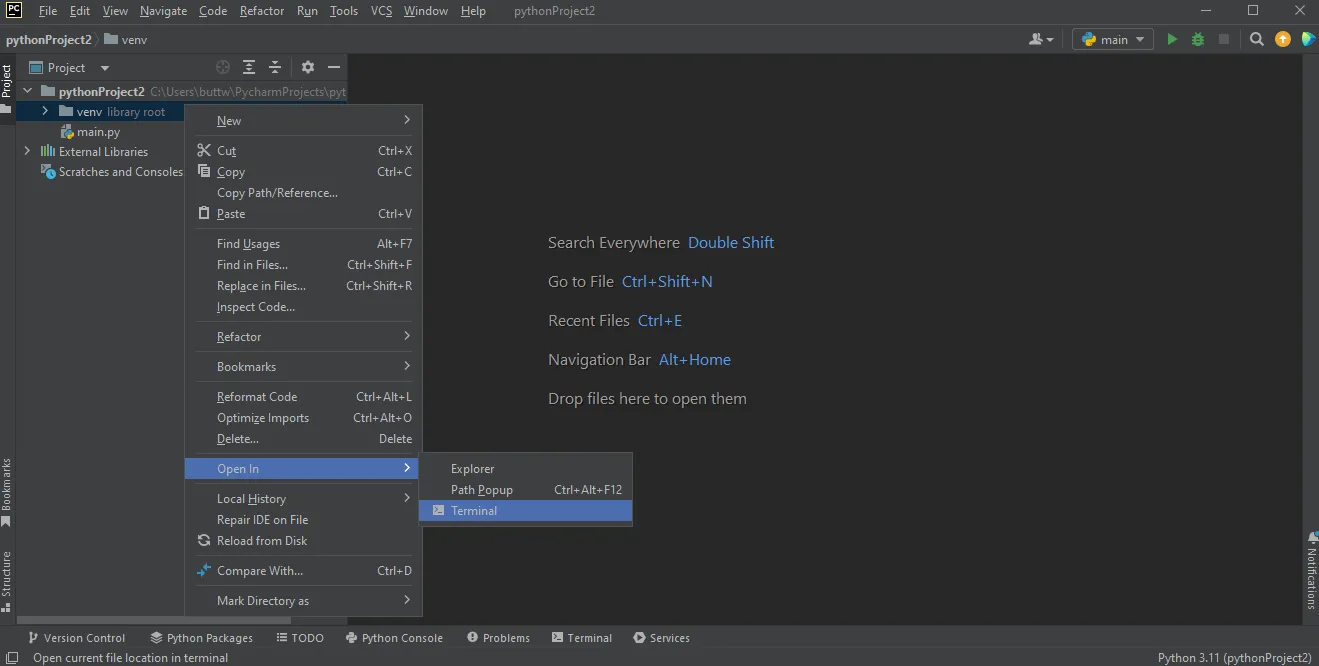 Ouvrir le terminal dans PyCharm
Ouvrir le terminal dans PyCharm
- Écrivez la commande suivante et appuyez sur Entrée pour installer IronPDF.
pip install ironpdf
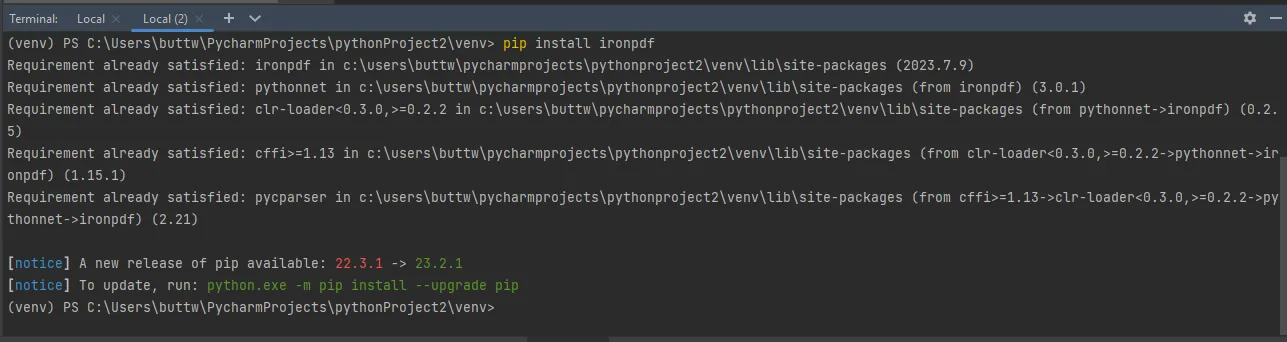 Installer le package IronPDF
Installer le package IronPDF
- Attendez quelques minutes; il téléchargera et installera IronPDF sur votre système.
Et voilà ! Vous avez maintenant installé IronPDF for Python dans votre projet PyCharm, et vous pouvez commencer à l'utiliser pour les tâches de traitement des PDF dans votre code Python. N'oubliez pas que la fonctionnalité spécifique et l'utilisation d'IronPDF dépendront de la documentation et de l'API fournies par la bibliothèque. Assurez-vous de consulter la documentation officielle d'IronPDF pour plus de détails sur l'utilisation efficace.
3. Ouvrir un fichier PDF à l'aide de la bibliothèque IronPDF for Python
Vous pouvez facilement ouvrir un document PDF avec IronPDF. Pour ce faire, vous devez d'abord créer un nouveau fichier PDF, l'enregistrer, puis l'ouvrir. IronPDF fournit un moyen simple de gérer les fichiers PDF, permettant de générer, modifier et interagir avec des documents PDF sans effort. Dans le cas où vous auriez besoin de gérer des documents protégés par mot de passe utilisateur, IronPDF fournit également les méthodes nécessaires pour gérer de tels cas.
3.1. Ouvrir un nouveau fichier PDF dans le visualiseur PDF par défaut
L'extrait de code ci-dessous explique le processus de création de fichiers PDF et de leur ouverture dans le visualiseur PDF par défaut de votre système.
from ironpdf import * # Import IronPDF for PDF rendering
import webbrowser # Import webbrowser to open files in browser
# Specify the output path for the PDF file
output_path = "C:\\Users\\buttw\\OneDrive\\Desktop\\url.pdf"
# Create a PDF renderer object using ChromePdfRenderer
renderer = ChromePdfRenderer()
# Render the PDF from a URL
pdf = renderer.RenderUrlAsPdf("https://www.google.com/")
# Save the rendered PDF to the specified path
pdf.SaveAs(output_path)
# Automatically open the PDF in the default PDF viewer
webbrowser.open(output_path)from ironpdf import * # Import IronPDF for PDF rendering
import webbrowser # Import webbrowser to open files in browser
# Specify the output path for the PDF file
output_path = "C:\\Users\\buttw\\OneDrive\\Desktop\\url.pdf"
# Create a PDF renderer object using ChromePdfRenderer
renderer = ChromePdfRenderer()
# Render the PDF from a URL
pdf = renderer.RenderUrlAsPdf("https://www.google.com/")
# Save the rendered PDF to the specified path
pdf.SaveAs(output_path)
# Automatically open the PDF in the default PDF viewer
webbrowser.open(output_path)Dans le code ci-dessus, nous importons les dépendances nécessaires : IronPDF pour la gestion des PDF et webbrowser pour ouvrir le PDF dans la visionneuse par défaut. Nous avons ensuite configuré le output_path où le PDF sera enregistré. Un objet ChromePdfRenderer est instancié pour gérer le rendu PDF. En appelant RenderUrlAsPdf, nous convertissons l'URL spécifiée en un PDF, après quoi SaveAs enregistre le PDF dans le chemin de sortie défini. Enfin, webbrowser.open est utilisé pour ouvrir automatiquement le PDF dans la visionneuse PDF par défaut.
3.1.1. Capture d'écran de sortie
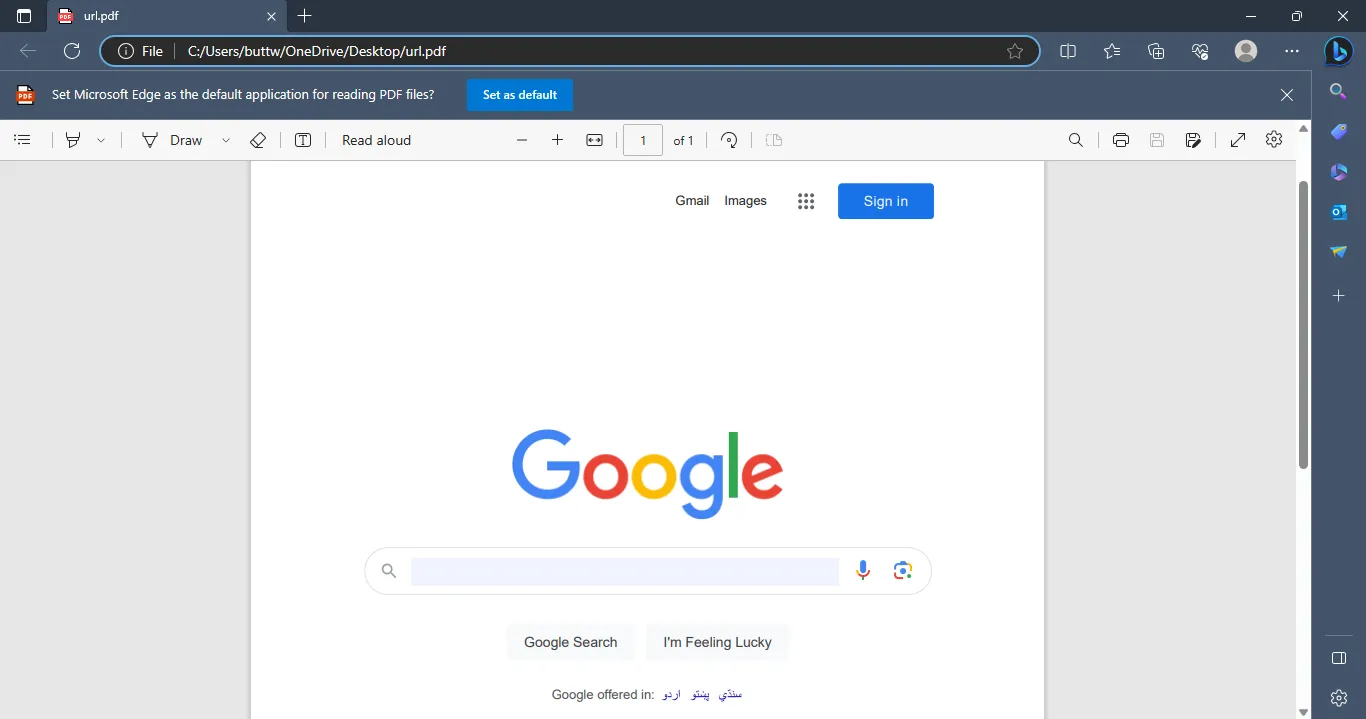 Le fichier PDF de sortie
Le fichier PDF de sortie
3.2. Ouvrir un fichier PDF dans Google Chrome
Pour ouvrir des pages PDF dans Google Chrome, vous devez répéter toutes les étapes et simplement remplacer la dernière ligne de code.
from ironpdf import * # Import IronPDF for PDF rendering
import webbrowser # Import webbrowser to open files in browser
# Specify the output path for the PDF file
output_path = "C:\\Users\\buttw\\OneDrive\\Desktop\\url.pdf"
# Create a PDF renderer object using ChromePdfRenderer
renderer = ChromePdfRenderer()
# Render the PDF from a URL
pdf = renderer.RenderUrlAsPdf("https://www.google.com/")
# Save the rendered PDF to the specified path
pdf.SaveAs(output_path)
# Register Google Chrome as a browser in webbrowser module
webbrowser.register(
"chrome",
None,
webbrowser.BackgroundBrowser(
"C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe"
),
)
# Open the PDF in Google Chrome
webbrowser.get("chrome").open(output_path)from ironpdf import * # Import IronPDF for PDF rendering
import webbrowser # Import webbrowser to open files in browser
# Specify the output path for the PDF file
output_path = "C:\\Users\\buttw\\OneDrive\\Desktop\\url.pdf"
# Create a PDF renderer object using ChromePdfRenderer
renderer = ChromePdfRenderer()
# Render the PDF from a URL
pdf = renderer.RenderUrlAsPdf("https://www.google.com/")
# Save the rendered PDF to the specified path
pdf.SaveAs(output_path)
# Register Google Chrome as a browser in webbrowser module
webbrowser.register(
"chrome",
None,
webbrowser.BackgroundBrowser(
"C:\\Program Files\\Google\\Chrome\\Application\\chrome.exe"
),
)
# Open the PDF in Google Chrome
webbrowser.get("chrome").open(output_path)Dans ce script, après avoir configuré le rendu PDF comme précédemment, nous enregistrons Google Chrome comme nouveau navigateur en utilisant webbrowser.register. Cela nous permet de spécifier explicitement Chrome lors de l'ouverture du PDF, en utilisant webbrowser.get("chrome").open(output_path) pour garantir que le fichier s'ouvre dans Chrome.
3.2.1. Capture d'écran de sortie
Comment ouvrir un fichier PDF en Python ? Figure 4 : Le fichier PDF généré. Le fichier PDF de sortie
4. Conclusion
La polyvalence et les capacités inhérentes de Python en font un excellent choix pour gérer les fichiers PDF dans diverses applications. Avec des bibliothèques comme IronPDF, les développeurs peuvent manipuler et interagir sans effort avec les documents des pages PDF, leur permettant d'extraire des informations, d'analyser des données et de générer des rapports en toute simplicité. IronPDF, étant une bibliothèque Python puissante, s'intègre parfaitement avec le langage, offrant une richesse de fonctionnalités avancées pour créer, transformer et modifier des fichiers PDF. Le processus d'installation d'IronPDF est simple, le rendant accessible à la fois pour les développeurs expérimentés et les nouveaux utilisateurs. Avec IronPDF, les développeurs peuvent ouvrir des fichiers PDF, en générer de nouveaux à partir de chaînes HTML et les enregistrer à divers endroits. De plus, il permet aux utilisateurs d'ouvrir des fichiers PDF dans des visualiseurs PDF par défaut comme Microsoft Edge ou Google Chrome. Cette bibliothèque remarquable révolutionne la façon dont les développeurs Python travaillent avec les PDF, libérant des possibilités infinies pour créer des documents de qualité professionnelle et améliorant l'expérience de développement générale. Que vous développiez des applications complexes ou des scripts simples, en faisant pivoter les pages PDF, en fusionnant des fichiers PDF, en divisant plusieurs pages ou en lisant des fichiers PDF, IronPDF vous permet d'exploiter tout le potentiel de Python dans le domaine de la manipulation des PDF, en faisant un outil indispensable pour tout développeur travaillant avec des fichiers PDF.
IronPDF pour Python est l'une des meilleures bibliothèques PDF disponibles, dans trois langages de programmation différents, et l'intérêt est que vous n'avez besoin que d'une licence pour utiliser les trois langages. Pour en savoir plus sur la conversion HTML en PDF avec IronPDF, rendez-vous à ce tutoriel Python. Le tutoriel sur la lecture de PDF en Python peut être trouvé à ce lien de tutoriel.
Questions Fréquemment Posées
Comment installer IronPDF for Python ?
Pour installer IronPDF dans votre projet Python, ouvrez votre terminal et exécutez la commande pip install ironpdf. Cela téléchargera et installera les fichiers nécessaires pour vous permettre de commencer à manipuler des PDF en Python.
Comment puis-je ouvrir un fichier PDF en using IronPDF en Python ?
Vous pouvez ouvrir un fichier PDF en using IronPDF en créant un objet PdfDocument après avoir rendu le PDF avec ChromePdfRenderer. Enregistrez le fichier en utilisant la méthode SaveAs, puis utilisez le module webbrowser pour ouvrir le PDF dans le visualiseur par défaut de votre système.
Puis-je ouvrir un PDF dans Google Chrome en using IronPDF for Python ?
Oui, vous pouvez ouvrir un PDF dans Google Chrome en enregistrant Chrome comme navigateur dans le module webbrowser et en le spécifiant lorsque vous ouvrez le fichier PDF.
Quelles sont les caractéristiques clés d'IronPDF for Python ?
IronPDF for Python offre des fonctionnalités telles que la génération de rapports PDF dynamiques, l'extraction de données à partir de PDF, la rotation de pages et la fusion de fichiers. Il fournit des outils robustes pour créer, transformer et modifier des documents PDF.
IronPDF est-il adapté aux débutants en Python ?
Oui, IronPDF est conçu pour être convivial tant pour les débutants que pour les développeurs expérimentés. Son installation simple et ses fonctionnalités complètes améliorent l'expérience de gestion des PDF en Python.
Comment puis-je convertir HTML en PDF en Python ?
Vous pouvez utiliser la méthode RenderHtmlAsPdf d'IronPDF pour convertir des chaînes HTML en PDFs. De plus, vous pouvez convertir des fichiers HTML en PDFs en utilisant la méthode RenderHtmlFileAsPdf.
IronPDF prend-il en charge la gestion des documents PDF sécurisés ?
Oui, IronPDF fournit des méthodes pour gérer les documents PDF protégés par mot de passe, permettant aux développeurs d'interagir avec des fichiers sécurisés.
Où puis-je trouver des tutoriels pour utiliser IronPDF avec Python ?
Des tutoriels pour utiliser IronPDF avec Python, y compris la conversion HTML en PDF et la lecture de PDF, peuvent être trouvés sur le site IronPDF dans la section Python.
Qu'est-ce qui fait d'IronPDF un outil puissant pour la manipulation de PDF en Python ?
IronPDF améliore la gestion des PDF en offrant des outils et des fonctionnalités avancés pour créer, modifier et transformer des fichiers PDF, permettant aux développeurs de produire des documents de qualité professionnelle en toute simplicité.
Quelles sont les langues de programmation prises en charge par IronPDF ?
IronPDF est disponible en trois langues de programmation différentes, permettant aux développeurs de travailler sur plusieurs plateformes avec une seule licence.