
Comment lire des fichiers PDF en Python
Les fichiers PDF, ou fichiers au format Portable Document, sont devenus une norme universelle pour le partage de documents. Ils sont largement utilisés pour leur capacité à préserver la mise en page et le formatage d'un document. Cependant, travailler avec des fichiers PDF en utilisant des langages de programmation comme Python peut être un peu difficile. Cet article présente IronPDF, une bibliothèque PDF pour Python qui nous permet d'effectuer diverses opérations avec des documents PDF.
IronPDF pour la bibliothèque PDF Python
IronPDF est une bibliothèque PDF avancée pour Python qui facilite le travail avec des fichiers au format PDF. Elle fournit une API facile à utiliser pour diverses opérations PDF. Vous pouvez lire et écrire des fichiers PDF, convertir des fichiers PDF en différents formats, combiner plusieurs fichiers PDF, et bien plus encore. Elle peut également gérer les objets de page, extraire le texte de toutes les pages du fichier PDF, et tourner les pages PDF, entre autres fonctionnalités.
Comment lire des fichiers PDF en Python
- Installez la bibliothèque PDF pour Python en utilisant Pip.
- Importez la bibliothèque PDF pour Python dans le script Python.
- Appliquez la clé de licence de la bibliothèque PDFReader pour Python.
- Chargez n'importe quel document PDF en fournissant le chemin d'accès du document.
- Lisez le contenu du PDF sur la console Python.
Lire un fichier PDF avec IronPDF
Lire un fichier PDF avec IronPDF implique plusieurs étapes. Voici un guide simple pour vous aider à démarrer :
Étape 1 : créer un environnement virtuel dans Visual Studio
Lorsque vous travaillez avec Python, il est crucial de créer un environnement isolé appelé environnement virtuel. Cet environnement vous permet de gérer les dépendances spécifiques au projet sur lequel vous travaillez sans interférer avec d'autres projets. Créer un environnement virtuel devient encore plus simple dans un environnement de développement intégré (IDE) comme Visual Studio Code. Pour ce faire, suivez les étapes ci-dessous :
-
Ouvrez le dossier dans Visual Studio Code. Appuyez sur Ctrl+Shift+P pour ouvrir la Palette de Commandes. Dans la Palette de Commandes, recherchez "Python : Create Environment".

-
Sélectionnez la première option, puis choisissez "Venv" comme type d'environnement.

-
Après cela, sélectionnez l'interpréteur Python, et il commencera à créer l'environnement virtuel.

Vous avez maintenant votre espace de travail isolé prêt pour vos scripts Python, assurant que les dépendances du projet soient limitées à cet environnement.
![]()
Étape 2 : installer IronPDF pour Python
Avec l'environnement virtuel configuré, vous êtes prêt à installer la bibliothèque IronPDF for Python. Vous pouvez l'installer en utilisant l'installateur de paquets Python 'pip' :
pip install ironpdfpip install ironpdfÉtape 3 : installer .NET 6.0
IronPDF for Python nécessite l'installation du SDK .NET 6.0.
Veuillez télécharger et installer le SDK .NET 6.0 depuis le site Web Microsoft .NET.
Étape 4 : importer IronPDF
Après avoir installé avec succès IronPDF, l'étape suivante consiste à l'importer dans votre script Python. L'importation de la bibliothèque rend toutes ses fonctions et méthodes disponibles pour l'utilisation dans votre script. Vous pouvez importer IronPDF en utilisant la ligne de code suivante :
from ironpdf import *from ironpdf import *Cette ligne de code importe tous les modules, fonctions et classes disponibles dans la bibliothèque IronPDF dans votre script.
Étape 5 : appliquer la clé de licence
Pour débloquer complètement les capacités de la bibliothèque IronPDF, vous devez appliquer une clé de licence. L'application d'une clé de licence est aussi simple que d'attribuer la clé à la propriété LicenseKey de la classe License. Voici comment faire :
License.LicenseKey = "License-Key-Here"License.LicenseKey = "License-Key-Here"Remplacez "License-Key-Here" par votre clé de licence IronPDF réelle. Avec la clé de licence en place, vous êtes maintenant prêt à exploiter tout le potentiel de la bibliothèque IronPDF dans vos scripts Python.
Étape 6 : définir le chemin du journal
Ensuite, configurez l'enregistrement des opérations IronPDF. En définissant un chemin de journal personnalisé, vous pouvez stocker les logs d'exécution que la bibliothèque génère, vous aidant à déboguer et diagnostiquer les problèmes qui pourraient survenir pendant l'exécution. Voici comment le configurer :
# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.AllDans cet extrait, Logger.EnableDebugging = True active le débogage, Logger.LogFilePath = "Custom.log" définit le fichier journal de sortie sur " Custom.log ", et Logger.LoggingMode = Logger.LoggingModes.All garantit que tous les types d'informations de journalisation sont enregistrés.
Étape 7 : charger le document PDF
Charger un document PDF avec IronPDF est aussi simple que d'appeler une méthode. La méthode PdfDocument.FromFile charge le document PDF à partir du chemin donné dans un objet fichier PDF. Vous devez simplement fournir le chemin du fichier PDF sous forme de chaîne de caractères :
pdf = PdfDocument.FromFile("PDF B.pdf")pdf = PdfDocument.FromFile("PDF B.pdf")Dans ce code, pdf devient un objet PdfDocument représentant le fichier PDF spécifié.
Étape 8 : lire le contenu du fichier PDF
IronPDF fournit une méthode appelée ExtractAllText() qui permet d' extraire le contenu textuel du document PDF . Cela est particulièrement utile lorsque vous avez besoin de lire et d'analyser le contenu d'un fichier PDF :
all_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleall_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleDans cet exemple, all_text contiendra tout le texte du fichier PDF de l'objet pdf. Vous pourrez lire le contenu du PDF sur la console.
Étape 9 : charger le deuxième fichier PDF
Tout comme vous avez chargé le premier document PDF, vous pouvez également charger un deuxième document PDF. Cette fonctionnalité est utile lorsque vous voulez manipuler plusieurs fichiers PDF :
pdf_2 = PdfDocument.FromFile("PDF A.pdf")pdf_2 = PdfDocument.FromFile("PDF A.pdf")Dans ce code, pdf_2 est un autre objet PdfDocument représentant le deuxième fichier PDF.
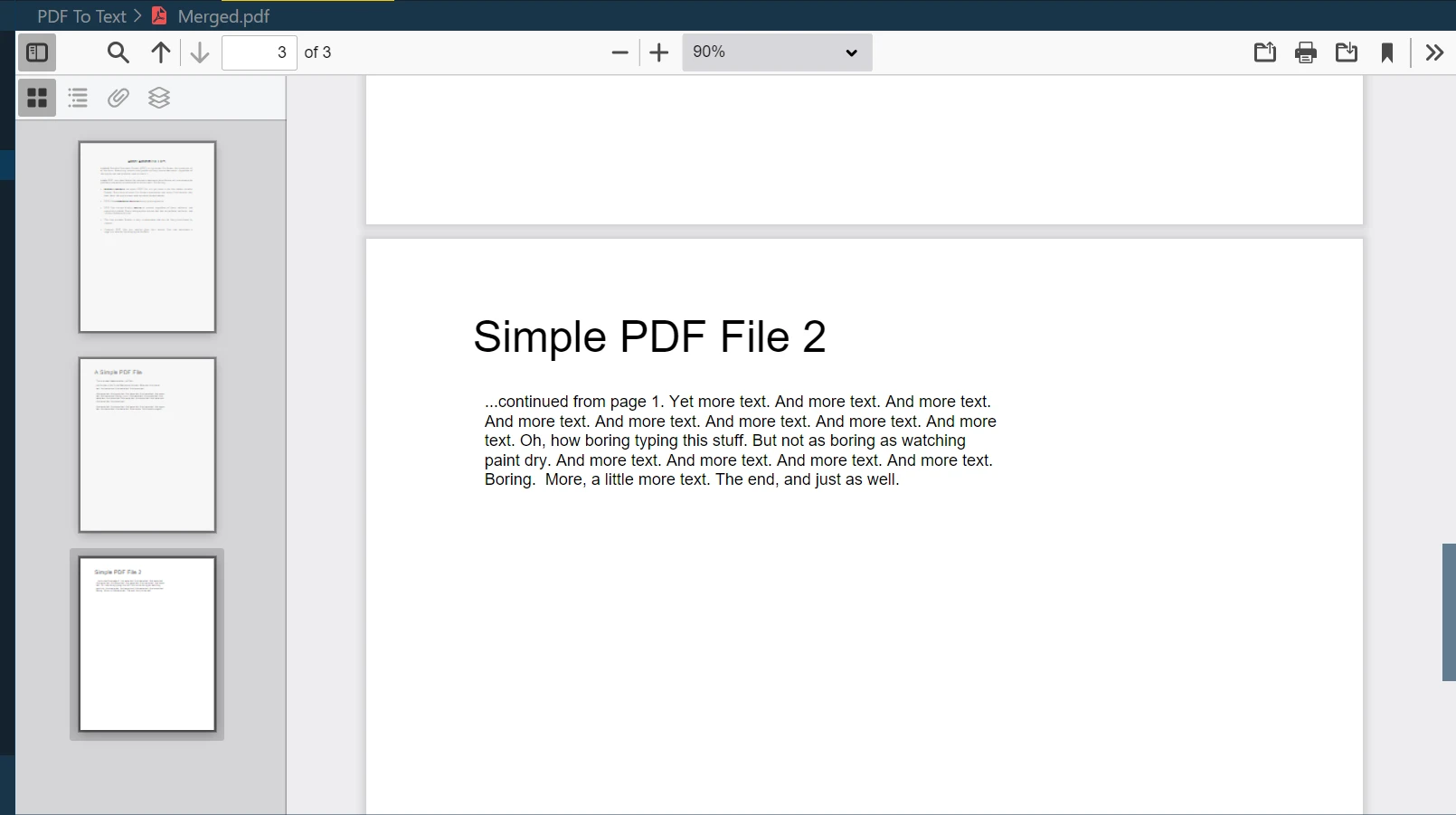
Étape 10 : fusionner les deux fichiers
L'une des fonctionnalités puissantes d' IronPDF est la fusion de plusieurs fichiers PDF en un seul. Vous pouvez facilement combiner deux documents PDF ou plus grâce à la méthode PdfDocument.Merge :
merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'Dans cet exemple, merged est un nouvel objet PdfDocument qui est le résultat de la fusion de pdf et pdf_2. La méthode SaveAs enregistre ensuite ce document fusionné sous le nom " Merged.pdf ".
Étape 11 : diviser le premier PDF
IronPDF vous permet également de diviser un document PDF et d'extraire des pages spécifiques dans de nouveaux fichiers PDF. Cela se fait en utilisant la méthode CopyPage :
page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'Ici, page1doc est un nouvel objet PdfDocument qui contient la première page du document pdf. Cette page est ensuite enregistrée en tant que fichier PDF de sortie nommé "Split1.pdf".

Étape 12 : appliquer un filigrane
Appliquer un filigrane est une autre fonctionnalité impressionnante offerte par IronPDF. Vous pouvez ajouter un filigrane à votre document PDF avec le texte ou l'image de votre choix. La méthode ApplyWatermark est utilisée pour ajouter un filigrane au PDF représenté par l'objet pdf.
pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")Dans cet extrait, ApplyWatermark applique un filigrane rouge avec le texte " SAMPLE " au centre du PDF. Ensuite, SaveAs enregistre le document filigrané sous le nom " Watermarked.pdf ".
Compatibilité d'IronPDF
IronPDF est une bibliothèque Python polyvalente compatible avec une large gamme de versions Python. Elle prend en charge toutes les versions modernes de Python à partir de Python 3.6. IronPDF n'est pas limité à un seul système d'exploitation. Elle est indépendante de la plateforme, et donc, peut être utilisée sur une variété de systèmes d'exploitation. Que ce soit Windows, Mac ou Linux, IronPDF fonctionne de manière fluide sur ces plateformes. Cette compatibilité multiplateforme est un énorme avantage, faisant d'IronPDF un choix incontournable pour les développeurs quelle que soit leur préférence en matière de système d'exploitation.
Conclusion
En conclusion, IronPDF est une excellente bibliothèque Python qui simplifie la gestion des documents PDF. Que vous ayez besoin de fusionner plusieurs PDFs, extraire du texte, diviser des fichiers PDF ou appliquer des filigranes, IronPDF est là pour vous. Sa compatibilité avec plusieurs plateformes et sa facilité d'utilisation en font un outil précieux pour tout développeur travaillant avec des documents PDF.
IronPDF offre un essai gratuit. Cette période d'essai vous donne amplement l'occasion d'expérimenter ses fonctionnalités et d'évaluer son adéquation à vos besoins spécifiques. Une fois que vous l'aurez testé, vous pourrez acheter une licence à partir de $999.
















