
Como ler arquivos PDF em Python
Os arquivos PDF, ou Portable Document Format, tornaram-se um padrão universal para o compartilhamento de documentos. São amplamente utilizados devido à sua capacidade de preservar o layout e a formatação de um documento. No entanto, trabalhar com arquivos PDF usando linguagens de programação como Python pode ser um pouco desafiador. Este artigo apresenta o IronPDF, uma biblioteca Python para PDF que permite realizar diversas operações com documentos PDF.
IronPDF for Python - Biblioteca PDF
IronPDF é uma biblioteca Python avançada para PDF que facilita o trabalho com arquivos no formato PDF. Ela fornece uma API fácil de usar para diversas operações com PDFs. Você pode ler e escrever arquivos PDF, converter arquivos PDF para diferentes formatos, combinar vários arquivos PDF e muito mais. Ele também pode lidar com objetos de página, extrair texto de todas as páginas do arquivo PDF e girar páginas do PDF, entre outras funcionalidades.
Como ler arquivos PDF em Python
- Instale a biblioteca Python PDF usando o Pip.
- Importe a biblioteca Python PDF no script Python.
- Aplique a chave de licença da biblioteca PDFReader for Python.
- Carregue qualquer documento PDF fornecendo o caminho do documento.
- Leia o conteúdo do PDF no console do Python.
Leia um arquivo PDF usando o IronPDF.
A leitura de um arquivo PDF usando o IronPDF envolve várias etapas. Aqui está um guia simples para você começar:
Passo 1: Crie um ambiente virtual no Visual Studio.
Ao trabalhar com Python, é crucial criar um ambiente isolado conhecido como ambiente virtual. Este ambiente permite gerenciar dependências específicas do projeto em que você está trabalhando, sem interferir em outros projetos. Criar um ambiente virtual torna-se ainda mais simples em um Ambiente de Desenvolvimento Integrado (IDE) como o Visual Studio Code. Para isso, siga os passos abaixo:
- Abra a pasta no Visual Studio Code. Pressione Ctrl+Shift+P para abrir a Paleta de Comandos. Na Paleta de Comandos, procure por "Python: Criar Ambiente".

- Selecione a primeira opção e, em seguida, escolha "Venv" como o tipo de ambiente.

- Em seguida, selecione o interpretador Python, e o ambiente virtual será criado.

Agora você tem seu espaço de trabalho isolado pronto para seus scripts Python, garantindo que as dependências do projeto estejam confinadas a esse ambiente.
![]()
Passo 2: Instale a biblioteca IronPDF for Python.
Com o ambiente virtual configurado, você está pronto para instalar a biblioteca IronPDF for Python. Você pode instalá-lo usando o instalador de pacotes do Python, 'pip':
pip install ironpdf
Etapa 3: Instale o .NET 6.0
O IronPDF for Python requer a instalação do SDK .NET 6.0.
Faça o download e instale o SDK do .NET 6.0 no site da Microsoft .NET .
Etapa 4: Importar IronPDF
Após instalar o IronPDF com sucesso, o próximo passo é importá-lo para o seu script Python. Importar a biblioteca torna todas as suas funções e métodos disponíveis para uso em seu script. Você pode importar o IronPDF usando a seguinte linha de código:
from ironpdf import *from ironpdf import *Esta linha de código importa todos os módulos, funções e classes disponíveis na biblioteca IronPDF para o seu script.
Passo 5: Aplicar a chave de licença
Para desbloquear totalmente as funcionalidades da biblioteca IronPDF , você precisa aplicar uma chave de licença. Aplicar uma chave de licença é tão simples quanto atribuir a chave à propriedade LicenseKey da classe License. Eis como fazer:
License.LicenseKey = "License-Key-Here"License.LicenseKey = "License-Key-Here"Substitua "License-Key-Here" com sua chave de licença IronPDF real. Com a chave de licença em mãos, você está pronto para aproveitar todo o potencial da biblioteca IronPDF em seus scripts Python.
Etapa 6: Definir o caminho do log
Em seguida, configure o registro de logs para as operações do IronPDF . Ao definir um caminho de log personalizado, você pode armazenar os logs de tempo de execução gerados pela biblioteca, o que ajuda a depurar e diagnosticar problemas que possam ocorrer durante a execução. Veja como configurar:
# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.AllNeste trecho, Logger.EnableDebugging = True ativa a depuração, Logger.LogFilePath = "Custom.log" define o arquivo de log de saída como "Custom.log" e Logger.LoggingMode = Logger.LoggingModes.All garante que todos os tipos de informações de log sejam registrados.
Passo 7: Carregar documento PDF
Carregar um documento PDF com o IronPDF é tão fácil quanto chamar um método. O método PdfDocument.FromFile carrega o documento PDF do caminho fornecido em um objeto de arquivo PDF. Basta fornecer o caminho do arquivo PDF como uma string:
pdf = PdfDocument.FromFile("PDF B.pdf")pdf = PdfDocument.FromFile("PDF B.pdf")Neste código, pdf se torna um objeto PdfDocument representando o arquivo PDF especificado.
Passo 8: Leia o conteúdo do arquivo PDF
IronPDF fornece um método chamado ExtractAllText() que ajuda a extrair conteúdo de texto do documento PDF. Isso é especialmente útil quando você precisa ler e analisar o conteúdo de um arquivo PDF:
all_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleall_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleNeste exemplo, all_text conterá todo o texto do arquivo PDF do objeto pdf. Você poderá ler o conteúdo de PDFs no console.
Passo 9: Carregar o segundo arquivo PDF
Assim como você carregou o primeiro documento PDF, você também pode carregar um segundo documento PDF. Essa funcionalidade é útil quando você deseja manipular vários arquivos PDF:
pdf_2 = PdfDocument.FromFile("PDF A.pdf")pdf_2 = PdfDocument.FromFile("PDF A.pdf")Neste código, pdf_2 é outro objeto PdfDocument representando o segundo arquivo PDF.
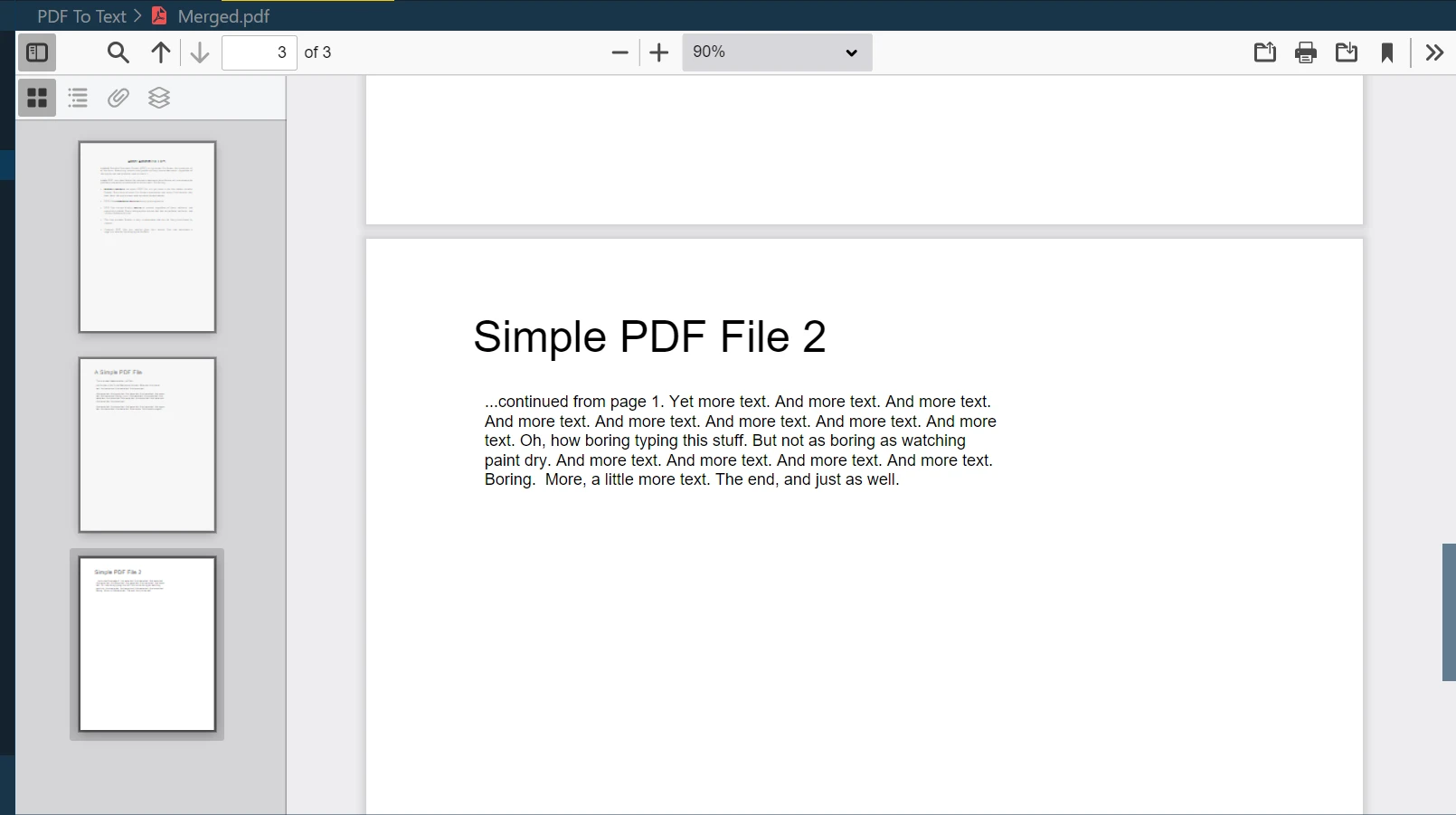
Etapa 10: Mesclar ambos os arquivos
Uma das funcionalidades poderosas do IronPDF é mesclar vários arquivos PDF em um único novo arquivo PDF. Você pode facilmente combinar dois ou mais documentos PDF usando o método PdfDocument.Merge:
merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'Neste exemplo, merged é um novo objeto PdfDocument que é o resultado da mesclagem de pdf e pdf_2. O método SaveAs então salva este documento mesclado com o nome "Merged.pdf".
Etapa 11: Dividir o primeiro PDF
O IronPDF também permite dividir um documento PDF e extrair páginas específicas para novos arquivos PDF. Isso é feito usando o método CopyPage:
page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'Aqui, page1doc é um novo objeto PdfDocument que contém a primeira página do documento pdf. Essa página é então salva como um arquivo PDF chamado "Split1.pdf".

Passo 12: Aplicar marca d'água
A marca d'água é outro recurso impressionante oferecido pelo IronPDF. Você pode adicionar uma marca d'água ao seu documento PDF com o texto ou imagem desejado. O método ApplyWatermark é usado para adicionar uma marca d'água ao PDF representado pelo objeto pdf.
pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")Neste trecho, ApplyWatermark aplica uma marca d'água vermelha com o texto "EXEMPLO" no centro meio do PDF. Então, SaveAs salva o documento com marca d'água como "Watermarked.pdf".
Compatibilidade com IronPDF
IronPDF é uma biblioteca Python versátil, compatível com uma ampla gama de versões do Python. É compatível com todas as versões modernas do Python, a partir da versão 3.6. O IronPDF não está restrito a um único sistema operacional. É independente de plataforma e, portanto, pode ser usado em diversos sistemas operacionais. Seja no Windows, Mac ou Linux, o IronPDF funciona perfeitamente em todas essas plataformas. Essa compatibilidade entre plataformas é uma grande vantagem, tornando o IronPDF a escolha ideal para desenvolvedores, independentemente de suas preferências de sistema operacional.
Conclusão
Em resumo, o IronPDF é uma excelente biblioteca Python que simplifica o trabalho com documentos PDF. Seja para mesclar vários PDFs, extrair texto, dividir arquivos PDF ou aplicar marcas d'água, o IronPDF tem a solução ideal. Sua compatibilidade com múltiplas plataformas e facilidade de uso fazem dele uma ferramenta valiosa para qualquer desenvolvedor que trabalhe com documentos PDF.
O IronPDF oferece um período de teste gratuito . Este período de teste oferece ampla oportunidade para você experimentar suas funcionalidades e avaliar se elas atendem às suas necessidades específicas. Depois de testá-lo, você pode adquirir uma licença a partir de $999.
















