
How to Read PDF Files in Python
PDFs, or Portable Document Format files, have become a universal standard for sharing documents. They are used widely for their ability to preserve the layout and formatting of a document. However, working with PDF files using programming languages like Python can be a bit of a challenge. This article introduces IronPDF, a Python PDF library that allows us to perform various operations with PDF documents.
IronPDF for Python PDF Library
IronPDF is an advanced Python PDF library that facilitates working with PDF format files. It provides an easy-to-use API for various PDF operations. You can read and write PDF files, convert PDF files to different formats, combine multiple PDF files, and much more. It can also deal with page objects, extract text from all the pages of the PDF file, and rotate PDF pages, among other functionalities.
How to Read PDF Files in Python
- Install the Python PDF Library using Pip.
- Import the Python PDF Library in the Python Script.
- Apply the License Key of the PDFReader Python Library.
- Load any PDF Document by providing the path of the document.
- Read PDF Content on the Python Console.
Read a PDF File using IronPDF
Reading a PDF file using IronPDF involves several steps. Here is a simple guide to get you started:
Step 1 Create a virtual environment in Visual Studio
When working with Python, it's crucial to create an isolated environment known as a virtual environment. This environment allows you to manage dependencies specific to the project you're working on without interfering with other projects. Creating a virtual environment becomes even more straightforward in an Integrated Development Environment (IDE) like Visual Studio Code. To do this, follow the steps below:
Open the folder in Visual Studio Code. Press Ctrl+Shift+P to open the Command Palette. In the Command Palette, search for "Python: Create Environment."

Select the first option, and then choose "Venv" as the environment type.

After that, select the Python interpreter, and it will start creating the virtual environment.

Now you have your isolated workspace ready for your Python scripts, ensuring the project dependencies are confined within this environment.
![]()
Step 2 Install IronPDF for Python library
With the virtual environment set up, you're ready to install the IronPDF for Python library. You can install it using the Python package installer 'pip':
pip install ironpdf
Step 3 Install .NET 6.0
IronPDF for Python requires the .NET 6.0 SDK to be installed.
Please download and install the .NET 6.0 SDK from the Microsoft .NET Website.
Step 4 Import IronPDF
After successfully installing IronPDF, the next step is to import it into your Python script. Importing the library makes all its functions and methods available for use in your script. You can import IronPDF using the following line of code:
from ironpdf import *from ironpdf import *This line of code imports all the modules, functions, and classes available in the IronPDF library into your script.
Step 5 Apply License Key
To fully unlock the capabilities of the IronPDF library, you need to apply a license key. Applying a license key is as simple as assigning the key to the LicenseKey property of the License class. Here is how to do it:
License.LicenseKey = "License-Key-Here"License.LicenseKey = "License-Key-Here"Replace "License-Key-Here" with your actual IronPDF license key. With the license key in place, you are now ready to harness the full potential of the IronPDF library in your Python scripts.
Step 6 Set Log Path
Next, set up logging for IronPDF operations. By setting a custom log path, you can store the runtime logs that the library generates, helping you debug and diagnose issues that might occur during execution. Here's how to set it up:
# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.AllIn this snippet, Logger.EnableDebugging = True turns on debugging, Logger.LogFilePath = "Custom.log" sets the output log file to "Custom.log", and Logger.LoggingMode = Logger.LoggingModes.All ensures that all types of log information are recorded.
Step 7 Load PDF document
Loading a PDF document with IronPDF is as easy as calling a method. The PdfDocument.FromFile method loads the PDF document from the given path into a PDF file object. You just need to provide the path of the PDF file as a string:
pdf = PdfDocument.FromFile("PDF B.pdf")pdf = PdfDocument.FromFile("PDF B.pdf")In this code, pdf becomes a PdfDocument object representing the specified PDF file.
Step 8 Read PDF File content
IronPDF provides a method called ExtractAllText() that helps for extracting text content from the PDF document. This is especially handy when you need to read and analyze the contents of a PDF file:
all_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleall_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleIn this example, all_text will hold all PDF file text from the pdf object. You'll be able to read PDF content on the console.
Step 9 Load Second PDF File
Just like you loaded the first PDF document, you can also load a second PDF document. This feature is helpful when you want to manipulate multiple PDF files:
pdf_2 = PdfDocument.FromFile("PDF A.pdf")pdf_2 = PdfDocument.FromFile("PDF A.pdf")In this code, pdf_2 is another PdfDocument object representing the second PDF file.
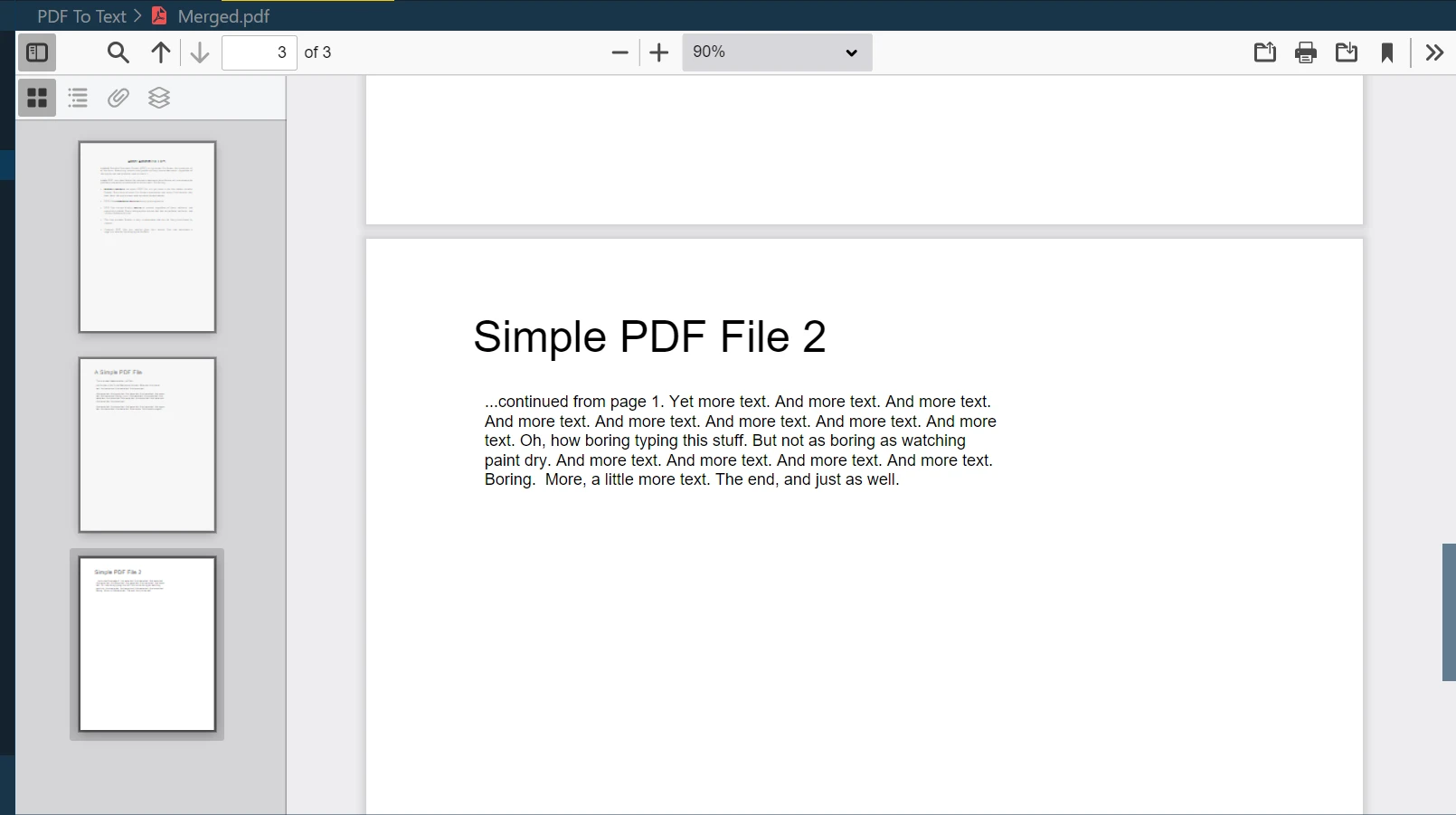
Step 10 Merge Both files
One of the powerful functionalities of IronPDF is merging multiple PDF files into a single new PDF file. You can easily combine two or more PDF documents using the PdfDocument.Merge method:
merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'In this example, merged is a new PdfDocument object that is the result of merging pdf and pdf_2. The SaveAs method then saves this merged document with the name "Merged.pdf".
Step 11 Split First PDF
IronPDF also allows you to split a PDF document and extract specific pages into new PDF files. This is done using the CopyPage method:
page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'Here, page1doc is a new PdfDocument object that contains the first page of the pdf document. This page is then saved as an output PDF named "Split1.pdf".

Step 12 Apply Watermark
Watermarking is another impressive feature offered by IronPDF. You can watermark your PDF document with your desired text or image. The ApplyWatermark method is used to add a watermark to the PDF represented by the pdf object.
pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")In this snippet, ApplyWatermark applies a red watermark with the text "SAMPLE" to the middle center of the PDF. Then, SaveAs saves the watermarked document as "Watermarked.pdf".
IronPDF Compatibility
IronPDF is a versatile Python library compatible with a wide range of Python versions. It supports all modern Python versions from Python 3.6 onwards. IronPDF isn't restricted to a single operating system. It is platform-independent, and hence, can be used on a variety of operating systems. Be it Windows, Mac, or Linux, IronPDF works seamlessly across these platforms. This cross-platform compatibility is a huge advantage, making IronPDF a go-to choice for developers irrespective of their operating system preferences.
Conclusion
In conclusion, IronPDF is an excellent Python library that simplifies dealing with PDF documents. Whether you need to merge multiple PDFs, extract text, split PDF files, or apply watermarks, IronPDF has got you covered. Its compatibility with multiple platforms and ease of use make it a valuable tool for any developer working with PDF documents.
IronPDF offers a free trial. This trial period gives you ample opportunity to experiment with its functionalities and evaluate its fit for your specific needs. Once you've tested it out, you can purchase a license starting from $999.
















