
Como extrair texto de um PDF em Python
Este artigo demonstrará como extrair todo o texto de arquivos PDF usando o IronPDF em Python, fornecendo o conhecimento e trechos de código Python para realizar essa tarefa de forma eficiente.
Como extrair texto de um PDF em Python
- Baixe um módulo Python para extrair texto de PDFs.
- Utilize o método
FromFilepara importar o arquivo PDF. - Extraia o texto do PDF importado com o método
ExtractText - Extraia texto de páginas específicas com o método
ExtractTextFromPage - Exiba o texto extraído no console ou em um arquivo de texto.
IronPDF - Biblioteca Python
IronPDF for Python é uma poderosa biblioteca Python para PDF que permite aos desenvolvedores extrair texto de documentos PDF. Com o IronPDF, você pode automatizar a extração de dados de conteúdo textual de arquivos PDF, facilitando o processamento e a análise das informações contidas nesses documentos.
O IronPDF oferece aos programadores Python a capacidade de manipular, extrair dados e interagir com arquivos PDF usando Python, facilitando a automação de várias tarefas relacionadas a PDFs. Seja para gerar PDFs, modificar PDFs existentes, extrair dados de conteúdo ou realizar outras operações em PDFs, o IronPDF simplifica o processo com sua API intuitiva e recursos poderosos.
Principais características
Algumas funcionalidades da biblioteca IronPDF for Python incluem:
- Criar um novo arquivo PDF do zero
- Editar arquivos PDF existentes
- Extrair texto , metadados e imagens de arquivos PDF
- Converter arquivos PDF para outros formatos
- Proteja arquivos PDF com senhas e restrições.
- Dividir e mesclar PDFs
Pré-requisitos
Antes de prosseguir com a extração de texto usando o IronPDF, certifique-se de que os seguintes pré-requisitos estejam atendidos:
- Instalação do Python: Certifique-se de que o Python esteja instalado em seu sistema. O IronPDF é compatível com as versões 3.x do Python, portanto, certifique-se de ter uma instalação do Python compatível.
-
Biblioteca IronPDF: Instale a biblioteca IronPDF usando
pip, o gerenciador de pacotes Python. Abra a interface de linha de comando e execute o seguinte comando:pip install ironpdf
Observação: o Python precisa ser adicionado à variável de ambiente PATH para que os comandos do pip funcionem.
- Ambiente de Desenvolvimento Integrado (IDE): Embora não seja estritamente necessário, o uso de um IDE pode melhorar muito sua experiência de desenvolvimento. Oferece funcionalidades como preenchimento automático de código, depuração e um fluxo de trabalho mais simplificado. Uma IDE popular para desenvolvimento em Python é o PyCharm. Você pode baixar e instalar o PyCharm no site da JetBrains : https://www.jetbrains.com/pycharm/ .
- Editor de texto: Como alternativa, se preferir trabalhar com um editor de texto leve, você pode usar qualquer editor de texto de sua escolha, como o Visual Studio Code, o Sublime Text ou o Atom. Esses editores oferecem realce de sintaxe e outros recursos úteis para o desenvolvimento em Python. Você também pode usar o aplicativo IDLE do próprio Python.
Criando um projeto Python usando o PyCharm
Após instalar o PyCharm IDE, crie um projeto Python no PyCharm seguindo os passos abaixo:
- Inicie o PyCharm: Abra o PyCharm a partir do iniciador de aplicativos do seu sistema ou do atalho na área de trabalho.
-
Criar um novo projeto: Clique em "Criar novo projeto" ou abra um projeto Python existente.
 IDE PyCharm
IDE PyCharm -
Configurar as definições do projeto: Dê um nome ao seu projeto e escolha o local onde deseja criar o diretório do projeto. Selecione o interpretador Python para o seu projeto. Em seguida, clique em "Criar".
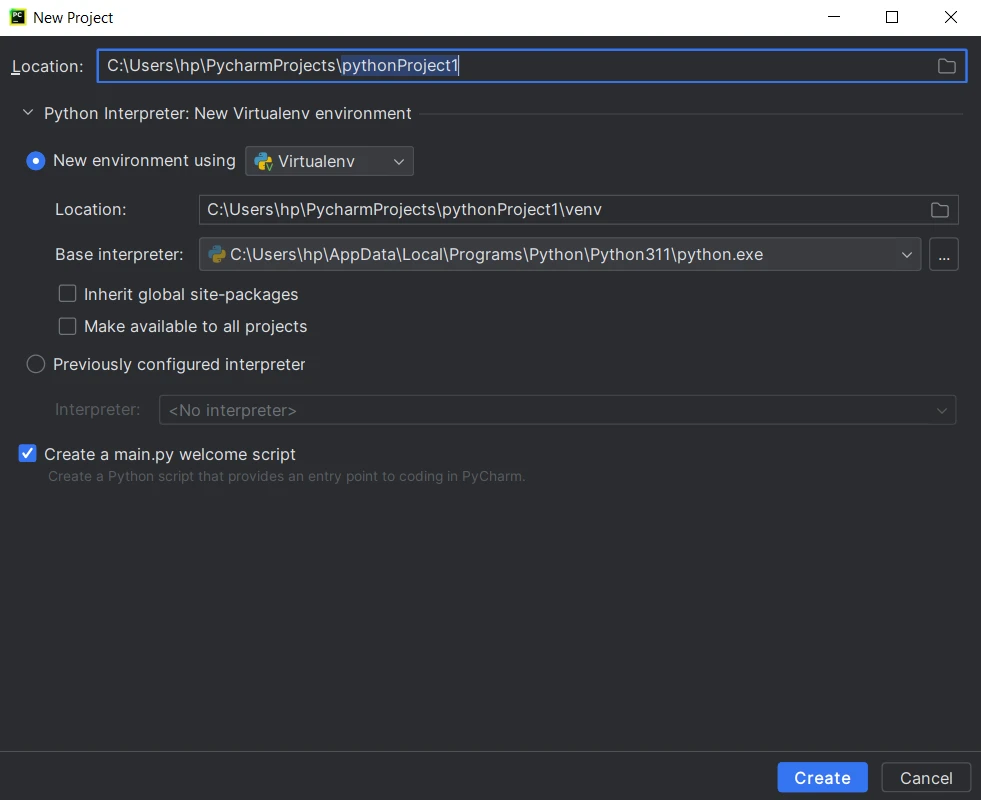 Crie um novo projeto Python no PyCharm.
Crie um novo projeto Python no PyCharm. - Criar arquivos de origem: O PyCharm criará a estrutura do projeto, incluindo um arquivo Python principal e um diretório para arquivos de origem adicionais. Comece a escrever o código e clique no botão "Executar" ou pressione Shift+F10 para executar o script.
Extraindo texto de PDF em Python usando IronPDF
Agora vamos analisar os passos envolvidos na extração de texto simples de arquivos PDF usando o IronPDF na linguagem de programação Python.
Importe as bibliotecas necessárias
Para começar, importe as bibliotecas necessárias em seu script Python. Neste caso, o exemplo de código precisa importar a biblioteca IronPDF , que fornece a funcionalidade para trabalhar com arquivos PDF.
import ironpdfimport ironpdfDefina a chave de licença.
Para extrair o texto completo de um arquivo PDF usando o IronPDF, você precisa ter uma licença do IronPDF . Aplique a licença ou a chave de avaliação usando o seguinte comando:
# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Observação: Sem uma chave de licença, a extração de dados do IronPDF fica restrita a poucos caracteres do arquivo PDF. Obtenha uma chave de licença comprando o IronPDF ou inscrevendo-se para um teste gratuito .
Carregar o documento PDF
Em seguida, carregue o arquivo PDF usando o método PdfDocument.FromFile() do IronPDF. Forneça o caminho para o arquivo PDF como argumento para este método. Isso irá carregar o arquivo PDF em um objeto PdfDocument.
pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")Arquivo de entrada
Para extrair o texto do arquivo PDF de entrada e imprimi-lo na tela, utiliza-se o seguinte documento:
 O arquivo de entrada
O arquivo de entrada
Extrair texto de arquivos PDF
Uma vez que o documento PDF é carregado, você pode extrair o conteúdo de texto usando o método ExtractText. Este método retorna o texto extraído como uma string.
text = pdf.ExtractText()text = pdf.ExtractText()Processar e utilizar o texto extraído
Agora que você extraiu o texto do PDF, pode processá-lo e utilizá-lo de acordo com suas necessidades. Você pode realizar tarefas como analisar o texto, armazená-lo em um banco de dados ou usá-lo para processamento de dados posterior.
# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted textSaída
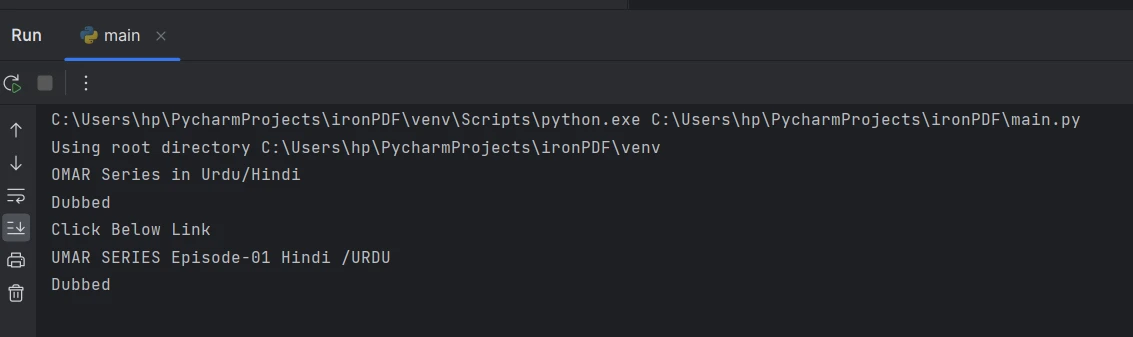 O texto extraído do console
O texto extraído do console
Extrair texto de uma página específica em um arquivo PDF
O IronPDF também fornece um método conveniente para extrair texto de páginas específicas dentro de um arquivo PDF. Esta seção irá explorar como extrair texto de uma página específica usando o método ExtractTextFromPage fornecido pelo IronPDF.
O código a seguir demonstra como extrair texto de uma página específica:
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)No código exemplo acima, pdf representa o objeto PdfDocument obtido após carregar o documento PDF. O método ExtractTextFromPage() é usado para extrair texto de uma página específica, indicada pelo índice da página passado como argumento. Neste caso, o texto é extraído da segunda página ou página número 2, que corresponde ao índice de página 1.
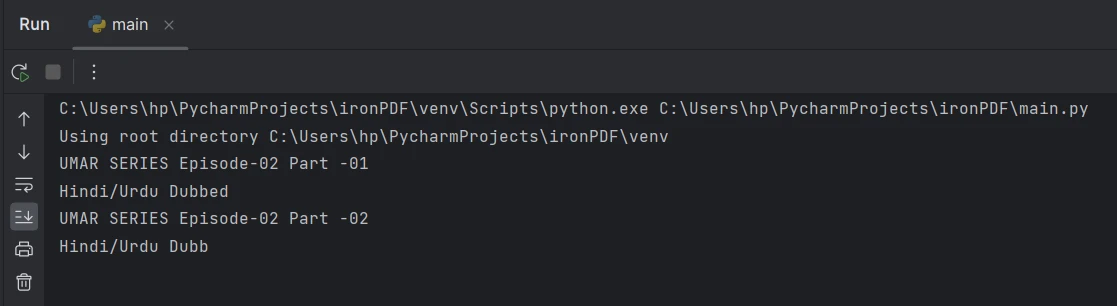 Extrair texto da página 2
Extrair texto da página 2
Conclusão
Este artigo explorou como extrair texto de arquivos PDF usando o IronPDF em Python. Abrangia os passos necessários, incluindo a importação da biblioteca requerida, o carregamento do documento PDF, a extração do conteúdo textual e o processamento do texto extraído.
Com os poderosos recursos de extração de texto do IronPDF, você pode automatizar a extração e o processamento de texto em PDFs, permitindo processar e analisar facilmente as informações textuais contidas em documentos PDF. Sua API intuitiva e amplas funcionalidades fazem dela a escolha ideal para uma vasta gama de tarefas relacionadas a PDFs no desenvolvimento em Python.
O IronPDF é gratuito para fins de desenvolvimento, mas precisa ser licenciado para uso comercial. Para utilizá-lo em modo de produção para testes, obtenha uma versão de avaliação gratuita . Baixe e instale a versão mais recente do IronPDF for Python e experimente.
Perguntas frequentes
Como posso extrair texto de um documento PDF inteiro usando Python?
É possível extrair texto de um documento PDF inteiro usando o método PdfDocument.FromFile() do IronPDF para carregar o PDF e, em seguida, chamando o método ExtractText() para recuperar o conteúdo do texto.
Qual é o processo para extrair texto de páginas específicas de um PDF em Python?
Para extrair texto de páginas específicas de um PDF, utilize o método ExtractTextFromPage() do IronPDF, que permite especificar o índice da página para recuperar o texto dessa página em particular.
Como faço para instalar a biblioteca IronPDF for Python?
Instale a biblioteca IronPDF for Python usando o gerenciador de pacotes pip executando o comando: pip install ironpdf .
Quais são os pré-requisitos para extrair texto de PDFs em Python?
Os pré-requisitos incluem ter o Python instalado no seu sistema, instalar o IronPDF via pip e usar uma IDE como o PyCharm para desenvolvimento.
Existe alguma versão gratuita da biblioteca IronPDF disponível para Python?
O IronPDF é gratuito para fins de desenvolvimento, mas você precisará de uma licença para uso comercial. Uma versão de avaliação gratuita está disponível para testar a biblioteca em modo de produção.
Preciso de uma licença para extrair o texto completo de PDFs usando o IronPDF?
Sim, é necessária uma chave de licença para extrair texto completo de PDFs usando o IronPDF. Sem uma licença, a extração fica limitada a alguns caracteres.
Quais são algumas das principais funcionalidades do IronPDF for Python?
Os principais recursos do IronPDF for Python incluem a criação e edição de PDFs, a extração de texto, metadados e imagens, a conversão de PDFs para outros formatos e a adição de recursos de segurança, como senhas.
O IronPDF for Python pode ajudar na automatização da extração de dados de PDFs?
Sim, o IronPDF oferece métodos como FromFile e ExtractText que facilitam a automatização da extração de dados de PDFs, auxiliando na análise e manipulação de dados.
Qual IDE é recomendada para usar o IronPDF em Python?
Recomenda-se o PyCharm para desenvolvimento em Python com IronPDF devido a recursos como preenchimento automático de código, ferramentas de depuração e um fluxo de trabalho simplificado.
Como o IronPDF melhora meu fluxo de trabalho no processamento de documentos PDF?
O IronPDF aprimora o fluxo de trabalho ao fornecer uma API intuitiva para extração de texto, criação e edição de PDFs, conversão de formatos e configurações de segurança, simplificando diversas tarefas relacionadas a PDFs.
















