
Wie man Text aus PDF in Python extrahiert
Dieser Artikel zeigt Ihnen, wie Sie mit IronPDF in Python den gesamten Text aus PDF-Dateien extrahieren können. Er liefert Ihnen das nötige Wissen und Python-Codebeispiele, um diese Aufgabe effizient zu erledigen.
Wie man Text aus PDF in Python extrahiert
- Herunterladen eines Python-Moduls zur Extraktion von Text aus PDF
- Verwenden Sie die Methode `FromFile`, um die PDF-Datei zu importieren
- Extrahieren von Text aus der importierten PDF-Datei mit der Methode `ExtractText`
- Extrahieren von Text aus bestimmten Seiten mit der Methode `ExtractTextFromPage`
- Geben Sie den extrahierten Text auf der Konsole oder in einer Textdatei aus
IronPDF - Python-Bibliothek
IronPDF für Python ist eine leistungsstarke Python-PDF-Bibliothek, die es Entwicklern ermöglicht, Text aus PDF-Dokumenten zu extrahieren. Mit IronPDF können Sie die Datenextraktion von Textinhalten aus PDF-Dateien automatisieren, was die Verarbeitung und Analyse der in PDF-Dokumenten enthaltenen Informationen erleichtert.
IronPDF bietet Python-Programmierern die Möglichkeit, PDF-Dateien mit Python zu bearbeiten, Daten daraus zu extrahieren und mit ihnen zu interagieren, wodurch die Automatisierung verschiedener PDF-bezogener Aufgaben erleichtert wird. Egal ob Sie PDFs generieren, bestehende PDFs bearbeiten, Daten aus Inhalten extrahieren oder andere PDF-Operationen durchführen müssen, IronPDF vereinfacht den Prozess mit seiner intuitiven API und seinen leistungsstarken Funktionen.
Wichtige Merkmale
Zu den Funktionen der IronPDF-Bibliothek für Python gehören unter anderem:
- Erstellen Sie eine neue PDF-Datei von Grund auf.
- Bearbeiten vorhandener PDF-Dateien
- Extrahieren von Text , Metadaten und Bildern aus PDF-Dateien
- Konvertierung von PDF-Dateien in andere Formate
- PDF-Dateien mit Passwörtern und Beschränkungen schützen
- PDFs teilen und zusammenführen
Voraussetzungen
Bevor Sie mit der Textextraktion mithilfe von IronPDF fortfahren, stellen Sie sicher, dass die folgenden Voraussetzungen erfüllt sind:
- Python-Installation: Stellen Sie sicher, dass Python auf Ihrem System installiert ist. IronPDF ist mit Python 3.x-Versionen kompatibel. Stellen Sie daher sicher, dass Sie über eine kompatible Python-Installation verfügen.
-
IronPDF -Bibliothek: Installieren Sie die IronPDF Bibliothek mit
pip, dem Python-Paketmanager. Öffnen Sie Ihre Befehlszeilenschnittstelle und führen Sie folgenden Befehl aus:pip install ironpdfpip install ironpdfSHELLHinweis: Um pip-Befehle verwenden zu können, muss Python zur Umgebungsvariablen PATH hinzugefügt werden.
- Integrierte Entwicklungsumgebung (IDE): Die Verwendung einer IDE ist zwar nicht unbedingt notwendig, kann aber Ihr Entwicklungserlebnis erheblich verbessern. Es bietet Funktionen wie Codevervollständigung, Debugging und einen optimierten Arbeitsablauf. Eine beliebte IDE für die Python-Entwicklung ist PyCharm. Sie können PyCharm von der JetBrains-Website herunterladen und installieren : https://www.jetbrains.com/pycharm/ .
- Texteditor: Alternativ können Sie, wenn Sie lieber mit einem schlanken Texteditor arbeiten möchten, einen beliebigen Texteditor Ihrer Wahl verwenden, wie z. B. Visual Studio Code, Sublime Text oder Atom. Diese Editoren bieten Syntaxhervorhebung und andere nützliche Funktionen für die Python-Entwicklung. Alternativ können Sie auch die IDLE-Anwendung von Python verwenden.
Erstellen eines Python-Projekts mit PyCharm
Nach der Installation der PyCharm IDE erstellen Sie ein PyCharm Python-Projekt, indem Sie die folgenden Schritte ausführen:
- Starten Sie PyCharm: Öffnen Sie PyCharm über den Anwendungsstarter Ihres Systems oder die Desktopverknüpfung.
-
Neues Projekt erstellen: Klicken Sie auf "Neues Projekt erstellen" oder öffnen Sie ein bestehendes Python-Projekt.
 PyCharm IDE
PyCharm IDE -
Projekteinstellungen konfigurieren: Geben Sie Ihrem Projekt einen Namen und wählen Sie den Speicherort für das Projektverzeichnis. Wählen Sie den Python-Interpreter für Ihr Projekt aus. Klicken Sie anschließend auf "Erstellen".
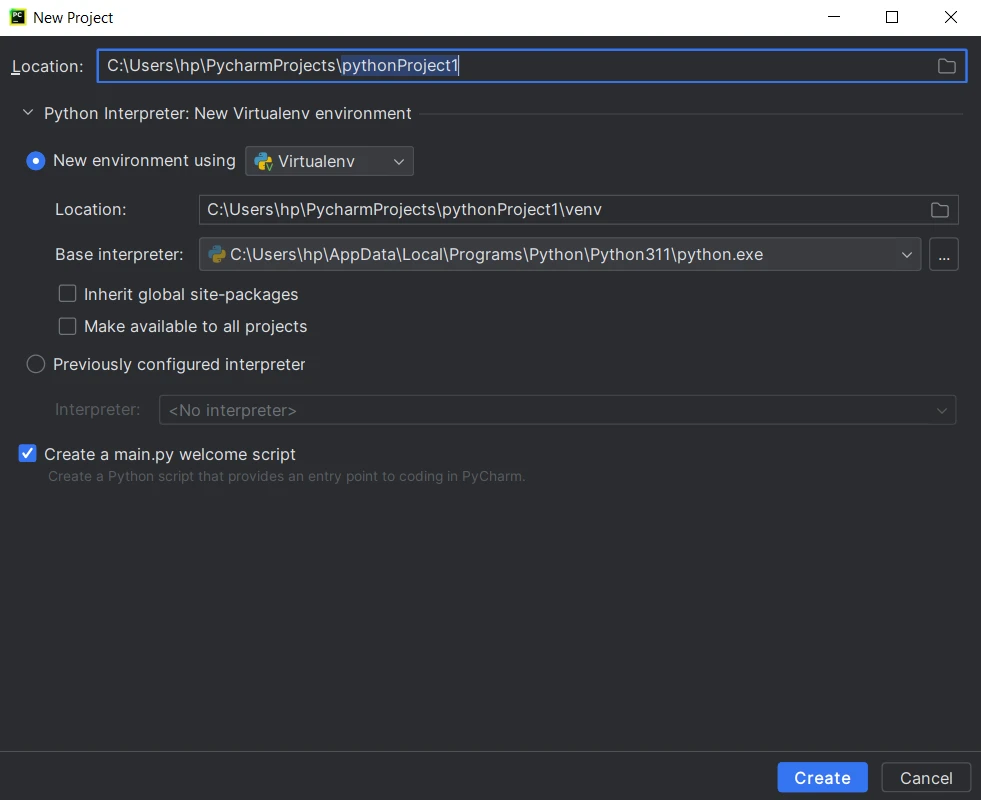 Erstelle ein neues Python-Projekt in PyCharm
Erstelle ein neues Python-Projekt in PyCharm - Quelldateien erstellen: PyCharm erstellt die Projektstruktur, einschließlich einer Haupt-Python-Datei und eines Verzeichnisses für zusätzliche Quelldateien. Beginnen Sie mit dem Schreiben des Codes und klicken Sie auf die Schaltfläche "Ausführen" oder drücken Sie Shift+F10, um das Skript auszuführen.
Textextraktion aus PDFs in Python mit IronPDF
Nun wollen wir uns die einzelnen Schritte ansehen, die zum Extrahieren von Klartext aus PDF-Dateien mit IronPDF in der Programmiersprache Python erforderlich sind.
Importieren Sie die erforderlichen Bibliotheken
Importieren Sie zunächst die benötigten Bibliotheken in Ihr Python-Skript. In diesem Fall muss der Code die IronPDF -Bibliothek importieren, die die Funktionalität für die Arbeit mit PDF-Dateien bereitstellt.
import ironpdfimport ironpdfLizenzschlüssel festlegen
Um mit IronPDF den Volltext aus einer PDF-Datei zu extrahieren, benötigen Sie eine IronPDF-Lizenz. Wenden Sie den Lizenz- oder Testschlüssel mit folgendem Befehl an:
# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Hinweis: Ohne Lizenzschlüssel kann IronPDF nur wenige Zeichen aus der PDF-Datei extrahieren. Sie erhalten einen Lizenzschlüssel beim Kauf von IronPDF oder durch die Anmeldung zu einer kostenlosen Testversion .
Laden Sie das PDF-Dokument
Laden Sie anschließend die PDF-Datei mit der Methode PdfDocument.FromFile() von IronPDF. Geben Sie den Pfad zur PDF-Datei als Argument für diese Methode an. Dadurch wird die PDF-Datei in ein PdfDocument-Objekt geladen.
pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")Eingabedatei
Um Text aus der eingegebenen PDF-Datei zu extrahieren und auf dem Bildschirm auszugeben, wird folgendes Dokument verwendet:
 Die Eingabedatei
Die Eingabedatei
Text aus PDF-Dateien extrahieren
Sobald das PDF-Dokument geladen ist, können Sie den Textinhalt mit der Methode ExtractText extrahieren. Diese Methode gibt den extrahierten Text als Zeichenkette zurück.
text = pdf.ExtractText()text = pdf.ExtractText()Verarbeiten und Nutzen des extrahierten Texts
Nachdem Sie den Text aus der PDF-Datei extrahiert haben, können Sie ihn nun entsprechend Ihren Anforderungen verarbeiten und nutzen. Sie können Aufgaben wie das Parsen des Textes, das Analysieren, das Speichern in einer Datenbank oder die Verwendung für die weitere Datenverarbeitung durchführen.
# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted textAusgabe
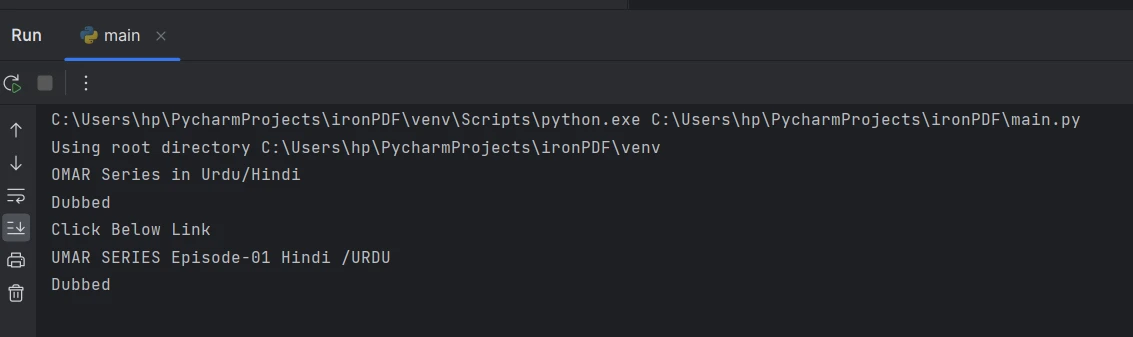 Der aus der Konsole extrahierte Text
Der aus der Konsole extrahierte Text
Text von einer bestimmten Seite in einer PDF-Datei extrahieren
IronPDF bietet außerdem eine komfortable Methode zum Extrahieren von Text aus bestimmten Seiten einer PDF-Datei. In diesem Abschnitt wird erläutert, wie Sie mithilfe der von IronPDF bereitgestellten Methode ExtractTextFromPage Text aus einer bestimmten Seite extrahieren.
Der folgende Code veranschaulicht, wie man Text von einer bestimmten Seite extrahiert:
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)Im obigen Beispielcode repräsentiert pdf das PdfDocument-Objekt, das nach dem Laden des PDF-Dokuments erhalten wird. Die Methode ExtractTextFromPage() dient dazu, Text von einer bestimmten Seite zu extrahieren, die durch den als Argument übergebenen Seitenindex angegeben wird. In diesem Fall wird der Text von der zweiten Seite bzw. der Seitenzahl 2 entnommen, was dem Seitenindex 1 entspricht.
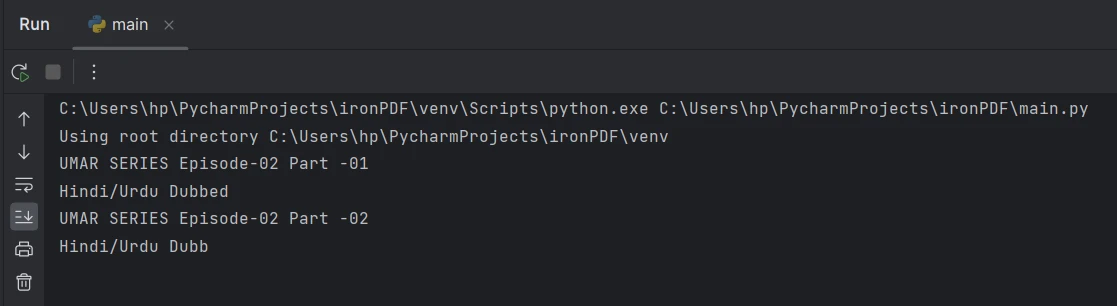 Text von Seite 2 extrahieren
Text von Seite 2 extrahieren
Abschluss
Dieser Artikel untersuchte, wie man mit IronPDF in Python Text aus PDF-Dateien extrahieren kann. Es umfasste die notwendigen Schritte, einschließlich des Importierens der benötigten Bibliothek, des Ladens des PDF-Dokuments, des Extrahierens des Textinhalts und der Verarbeitung des extrahierten Textes.
Mit den leistungsstarken Textextraktionsfunktionen von IronPDF können Sie die Extraktion und Weiterverarbeitung von Text aus PDFs automatisieren und so die Textinformationen in PDF-Dokumenten einfach verarbeiten und analysieren. Dank seiner intuitiven API und umfangreichen Funktionen ist es die ideale Wahl für eine breite Palette von PDF-bezogenen Aufgaben in der Python-Entwicklung.
IronPDF ist für Entwicklungszwecke kostenlos, für die kommerzielle Nutzung ist jedoch eine Lizenz erforderlich. Um es im Produktionsmodus zu Testzwecken zu nutzen, fordern Sie eine kostenlose Testversion an. Laden Sie die neueste Version von IronPDF für Python herunter, installieren Sie sie und probieren Sie sie aus.
Häufig gestellte Fragen
Wie kann ich Text aus einem gesamten PDF-Dokument mit Python extrahieren?
Sie können Text aus einem gesamten PDF-Dokument extrahieren, indem Sie die Methode PdfDocument.FromFile() von IronPDF verwenden, um das PDF zu laden, und dann die Methode ExtractText() aufrufen, um den Textinhalt abzurufen.
Was ist der Prozess zum Extrahieren von Text aus bestimmten Seiten eines PDFs in Python?
Um Text aus bestimmten Seiten eines PDFs zu extrahieren, verwenden Sie die Methode ExtractTextFromPage() von IronPDF, mit der Sie den Seitenindex angeben können, um den Text von dieser bestimmten Seite abzurufen.
Wie installiere ich die IronPDF-Bibliothek für Python?
Installieren Sie die IronPDF-Bibliothek für Python mit dem Paketmanager pip, indem Sie den Befehl ausführen: pip install ironpdf.
Was sind die Voraussetzungen, um Text aus PDFs in Python zu extrahieren?
Zu den Voraussetzungen gehört, dass Python auf Ihrem System installiert ist, IronPDF über pip installiert wird und eine IDE wie PyCharm für die Entwicklung verwendet wird.
Gibt es eine kostenlose Version der IronPDF-Bibliothek für Python?
IronPDF ist zu Entwicklungszwecken kostenlos, aber für die kommerzielle Nutzung benötigen Sie eine Lizenz. Eine kostenlose Testversion steht zur Verfügung, um die Bibliothek im Produktionsmodus zu testen.
Benötige ich eine Lizenz, um vollständigen Text aus PDFs mit IronPDF zu extrahieren?
Ja, ein Lizenzschlüssel ist erforderlich, um Text vollständig aus PDFs mit IronPDF zu extrahieren. Ohne Lizenz ist die Extraktion auf wenige Zeichen beschränkt.
Was sind einige Hauptmerkmale von IronPDF for Python?
Zu den Hauptfunktionen von IronPDF for Python gehören das Erstellen und Bearbeiten von PDFs, das Extrahieren von Text, Metadaten und Bildern, das Konvertieren von PDFs in andere Formate und das Hinzufügen von Sicherheitsfunktionen wie Passwörter.
Kann IronPDF for Python bei der Automatisierung der PDF-Datenextraktion helfen?
Ja, IronPDF bietet Methoden wie FromFile und ExtractText, die die Automatisierung der PDF-Datenextraktion erleichtern und bei der Datenanalyse und -manipulation unterstützen.
Welche IDE wird für die Verwendung von IronPDF in Python empfohlen?
PyCharm wird für die Python-Entwicklung mit IronPDF empfohlen aufgrund seiner Funktionen wie Codevervollständigung, Debugging-Tools und einem optimierten Arbeitsablauf.
Wie verbessert IronPDF meinen Arbeitsablauf bei der Verarbeitung von PDF-Dokumenten?
IronPDF verbessert den Arbeitsablauf durch eine intuitive API für Textextraktion, PDF-Erstellung und -Bearbeitung, Formatkonvertierung und Sicherheitseinstellungen und rationalisiert verschiedene PDF-bezogene Aufgaben.
















