Comment extraire du texte d'un PDF en Python
Cet article démontrera comment extraire tout le texte des fichiers PDF avec IronPDF en Python, vous fournissant les connaissances et les extraits de code Python pour accomplir cette tâche efficacement.
Comment extraire du texte d'un PDF en Python
- Téléchargez un module Python pour extraire du texte de PDF
- Utilisez la méthode `FromFile` pour importer le fichier PDF
- Extrayez le texte du PDF importé à l'aide de la méthode `ExtractText`
- Extraire le texte de pages spécifiques avec la méthode `ExtractTextFromPage`
- Sortir le texte extrait vers la console ou un fichier texte
IronPDF - Bibliothèque Python
IronPDF pour Python est une puissante bibliothèque PDF pour Python qui permet aux développeurs d'extraire du texte de documents PDF. Avec IronPDF, vous pouvez automatiser la partie extraction de données du contenu textuel des fichiers PDF, facilitant le traitement et l'analyse des informations contenues dans les documents PDF.
IronPDF offre aux programmeurs Python la possibilité de manipuler, extraire des données et interagir avec les fichiers PDF en utilisant Python, facilitant ainsi l'automatisation de diverses tâches liées aux PDF. Que vous ayez besoin de générer des PDFs, modifier des PDFs existants, extraire des données de contenu ou effectuer d'autres opérations PDF, IronPDF simplifie le processus avec son API intuitive et ses puissantes capacités.
Fonctionnalités clés
Certaines fonctionnalités de la bibliothèque IronPDF for Python incluent :
- Créer un nouveau fichier PDF à partir de zéro
- Édition de fichiers PDF existants
- Extraire du texte, les métadonnées et les images des fichiers PDF
- Convertir des fichiers PDF dans d'autres formats
- Sécuriser les fichiers PDF avec des mots de passe et des restrictions
- Diviser et fusionner des PDFs
Prérequis
Avant de procéder à l'extraction de texte avec IronPDF, assurez-vous que les prérequis suivants sont en place :
- Installation de Python : assurez-vous d'avoir Python installé sur votre système. IronPDF est compatible avec les versions Python 3.x, alors assurez-vous d'avoir une installation Python compatible.
-
Bibliothèque IronPDF : Installez la bibliothèque IronPDF en utilisant
pip, le Package Manager Python. Ouvrez votre interface de ligne de commande et exécutez la commande suivante :pip install ironpdfpip install ironpdfSHELLNote : Python doit être ajouté à la variable d'environnement PATH afin d'utiliser les commandes pip.
- Environnement de développement intégré (IDE) : Bien que non strictement nécessaire, l'utilisation d'un IDE peut grandement améliorer votre expérience de développement. Il offre des fonctionnalités comme l'autocomplétion de code, le débogage et un flux de travail plus rationalisé. Un IDE populaire pour le développement Python est PyCharm. Vous pouvez télécharger et installer PyCharm depuis le site de JetBrains https://www.jetbrains.com/pycharm/.
- Éditeur de texte : Sinon, si vous préférez travailler avec un éditeur de texte léger, vous pouvez utiliser n'importe quel éditeur de texte de votre choix, tel que Visual Studio Code, Sublime Text ou Atom. Ces éditeurs offrent la coloration syntaxique et d'autres fonctionnalités utiles pour le développement Python. Vous pouvez également utiliser l'application IDLE propre à Python.
Création d'un Projet Python en utilisant PyCharm
Après avoir installé PyCharm IDE, créez un projet Python PyCharm en suivant les étapes ci-dessous :
- Lancer PyCharm : Ouvrez PyCharm depuis le lanceur d'application de votre système ou depuis le raccourci du bureau.
-
Créer un Nouveau Projet : Cliquez sur "Create New Project" ou ouvrez un projet Python existant.
 PyCharm IDE
PyCharm IDE -
Configurer les Paramètres de Projet : Fournissez un nom à votre projet et choisissez l'emplacement pour créer le répertoire du projet. Sélectionnez l'interpréteur Python pour votre projet. Puis cliquez sur "Create".
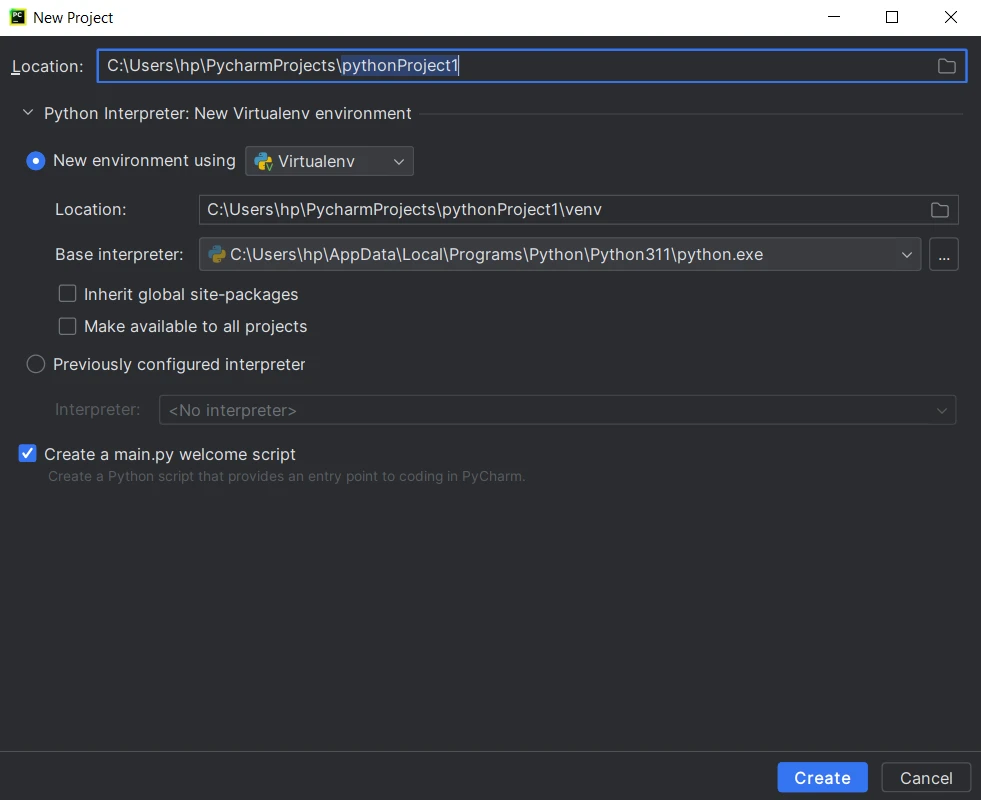 Créer un nouveau projet Python dans Pycharm
Créer un nouveau projet Python dans Pycharm - Créer des Fichiers Source : PyCharm créera la structure du projet, y compris un fichier Python principal et un répertoire pour les fichiers sources additionnels. Commencez à écrire du code et cliquez sur le bouton d'exécution ou appuyez sur Shift+F10 pour exécuter le script.
Extraire du Texte d'un PDF en Python avec IronPDF
Voyons maintenant les étapes impliquées dans l'extraction de texte brut à partir de fichiers PDF en utilisant le langage de programmation Python avec IronPDF.
Importer les Bibliothèques Nécessaires
Pour commencer, importez les bibliothèques nécessaires dans votre script Python. Dans ce cas, l'exemple de code doit importer la bibliothèque IronPDF, qui fournit les fonctionnalités pour travailler avec les fichiers PDF.
import ironpdfimport ironpdfDéfinir la Clé de Licence
Afin d'extraire tout le texte d'un fichier PDF avec IronPDF, vous devez posséder une licence IronPDF. Appliquez la clé de licence ou d'essai en utilisant la commande suivante :
# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Note : Sans clé de licence, l'extraction de données avec IronPDF est limitée à quelques caractères seulement à partir du fichier d'extension PDF. Obtenez une clé de licence en achetant IronPDF ou en vous inscrivant pour un essai gratuit.
Charger le Document PDF
Ensuite, chargez le fichier PDF en utilisant la méthode PdfDocument.FromFile() d' IronPDF. Fournissez le chemin du fichier PDF comme argument de cette méthode. Cela chargera le fichier PDF dans un objet PdfDocument.
pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")Fichier d'Entrée
Pour extraire le texte du fichier PDF d'entrée et l'imprimer à l'écran, le document suivant est utilisé :
 Le fichier d'entrée
Le fichier d'entrée
Extraire le Texte à partir des Fichiers PDF
Une fois le document PDF chargé, vous pouvez extraire le contenu textuel en utilisant la méthode ExtractText. Cette méthode retourne le texte extrait sous forme de chaîne de caractères.
text = pdf.ExtractText()text = pdf.ExtractText()Traiter et Utiliser le Texte Extrait
Maintenant que vous avez extrait le texte du PDF, vous pouvez le traiter et l'utiliser selon vos besoins. Vous pouvez effectuer des tâches comme analyser le texte, le stocker dans une base de données, ou l'utiliser pour un traitement ultérieur des données.
# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted textSortie
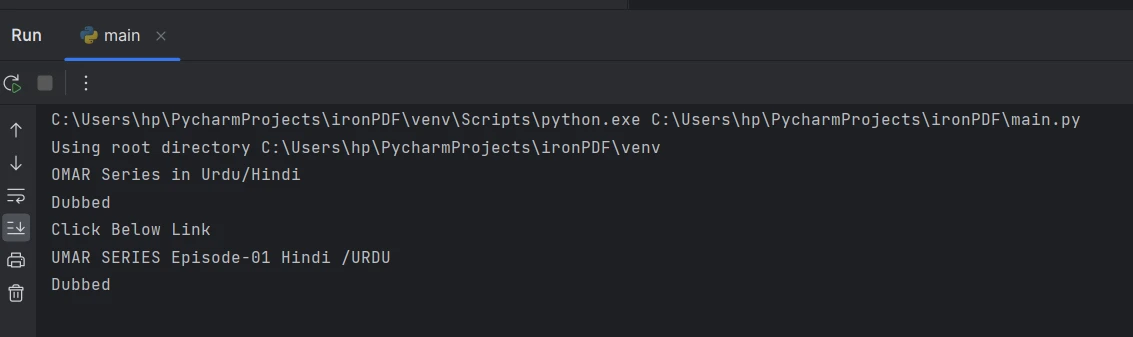 Le texte extrait de la console
Le texte extrait de la console
Extraire le Texte d'une Page Spécifique du Fichier PDF
IronPDF propose également une méthode pratique pour extraire du texte de pages spécifiques d'un fichier PDF. Cette section explique comment extraire du texte d'une page spécifique à l'aide de la méthode ExtractTextFromPage fournie par IronPDF.
Le code suivant démontre comment extraire le texte d'une page spécifique :
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)Dans l'exemple de code ci-dessus, pdf représente l'objet PdfDocument obtenu après le chargement du document PDF. La méthode ExtractTextFromPage() est utilisée pour extraire du texte d'une page spécifique, indiquée par l'index de page passé en argument. Dans ce cas, le texte est extrait de la deuxième page ou numéro de page 2, qui correspond à l'index de page 1.
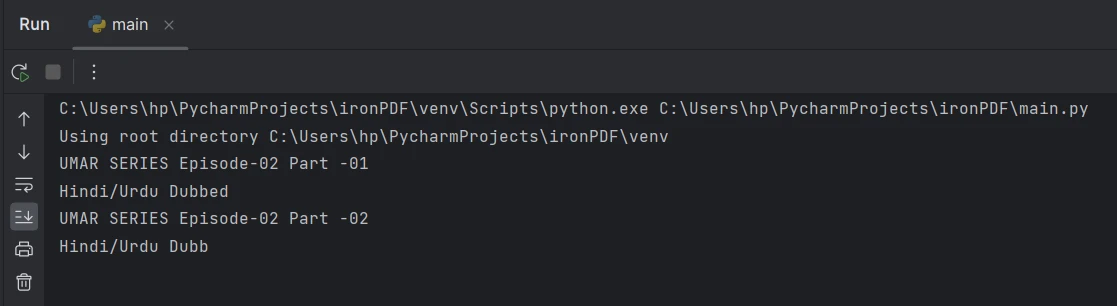 Extraire le texte de la page 2
Extraire le texte de la page 2
Conclusion
Cet article a exploré comment extraire du texte de fichiers PDF avec IronPDF en Python. Il a couvert les étapes nécessaires, y compris l'importation de la bibliothèque requise, le chargement du document PDF, l'extraction du contenu texte et le traitement du texte extrait.
Avec les puissantes capacités d'extraction de texte d'IronPDF, vous pouvez automatiser l'extraction et le traitement ultérieur du texte des PDFs, vous permettant de traiter et analyser facilement les informations textuelles contenues dans les documents PDF. Son API intuitive et ses capacités étendues en font un choix idéal pour un large éventail de tâches liées aux PDF dans le développement Python.
IronPDF est gratuit pour le développement, mais il doit être licencié pour un usage commercial. Pour l'utiliser en mode production pour les tests, obtenez un essai gratuit. Téléchargez et installez la dernière version de IronPDF pour Python et essayez-le.
Questions Fréquemment Posées
Comment puis-je extraire du texte de l'ensemble d'un document PDF en utilisant Python ?
Vous pouvez extraire le texte de l'ensemble d'un document PDF en utilisant la méthode PdfDocument.FromFile() d'IronPDF pour charger le PDF, puis en appelant la méthode ExtractText() pour récupérer le contenu textuel.
Quel est le processus pour extraire du texte de pages spécifiques d'un PDF en Python ?
Pour extraire du texte de pages spécifiques d'un PDF, utilisez la méthode ExtractTextFromPage() d'IronPDF, qui vous permet de spécifier l'index de la page pour récupérer le texte de cette page particulière.
Comment puis-je installer la bibliothèque IronPDF for Python ?
Installez la bibliothèque IronPDF for Python en utilisant le Package Manager pip en exécutant la commande : pip install ironpdf.
Quelles sont les conditions préalables pour extraire du texte des PDF en Python ?
Les conditions préalables incluent l'installation de Python sur votre système, l'installation d'IronPDF via pip, et l'utilisation d'un IDE comme PyCharm pour le développement.
Existe-t-il une version gratuite de la bibliothèque IronPDF disponible pour Python ?
IronPDF est gratuit à des fins de développement, mais vous aurez besoin d'une licence pour un usage commercial. Un essai gratuit est disponible pour tester la bibliothèque en mode production.
Ai-je besoin d'une licence pour extraire le texte complet des PDF en using IronPDF ?
Oui, une clé de licence est requise pour extraire complètement du texte des PDFs en using IronPDF. Sans licence, l'extraction est limitée à quelques caractères.
Quelles sont les caractéristiques clés d'IronPDF for Python ?
Les fonctionnalités clés d'IronPDF for Python incluent la création et l'édition de PDF, l'extraction de texte, de métadonnées et d'images, la conversion de PDFs vers d'autres formats et l'ajout de fonctionnalités de sécurité comme des mots de passe.
IronPDF for Python peut-il aider à automatiser l'extraction de données PDF ?
Oui, IronPDF propose des méthodes comme FromFile et ExtractText qui facilitent l'automatisation de l'extraction de données PDF, aidant à l'analyse et à la manipulation de données.
Quel IDE est recommandé pour utiliser IronPDF en Python ?
PyCharm est recommandé pour le développement Python avec IronPDF en raison de ses fonctionnalités telles que la complétion de code, les outils de débogage et un flux de travail rationalisé.
Comment IronPDF améliore-t-il mon flux de travail dans le traitement des documents PDF ?
IronPDF améliore le flux de travail en offrant une API intuitive pour l'extraction de texte, la création et la modification de PDF, la conversion de formats et les paramètres de sécurité, rationalisant diverses tâches liées aux PDF.