Comment visualiser un fichier PDF en Python
Cet article explorera comment visualiser des fichiers PDF en Python en utilisant la bibliothèque IronPDF.
IronPDF - Bibliothèque Python
IronPDF est une bibliothèque Python puissante qui permet aux développeurs de travailler avec des fichiers PDF de manière programmatique. Avec IronPDF, vous pouvez facilement générer, manipuler et extraire des données de documents PDF, ce qui en fait un outil polyvalent pour diverses tâches liées aux PDF. Que vous ayez besoin de créer des PDFs à partir de zéro, de modifier des PDFs existants ou d'extraire du contenu de PDFs, IronPDF offre un ensemble complet de fonctionnalités pour simplifier votre flux de travail.
Certaines fonctionnalités de la bibliothèque IronPDF for Python incluent :
- Créer un nouveau fichier PDF à partir de zéro, en utilisant HTML ou une URL
- Modifier des fichiers PDF existants
- Faire pivoter les pages PDF
- Extraire du texte, les métadonnées et les images des fichiers PDF
- Convertir des fichiers PDF en d'autres formats
- Sécuriser les fichiers PDF avec des mots de passe et des restrictions
- Diviser et fusionner des PDFs
Note : IronPDF produit un fichier de données PDF avec filigrane. Pour supprimer le filigrane, vous devez licencier IronPDF. Si vous souhaitez utiliser une version licenciée d'IronPDF, visitez le site web d'IronPDF pour obtenir une clé de licence.
Prérequis
Avant de travailler avec IronPDF en Python, il y a quelques prérequis :
- Installation de Python : assurez-vous d'avoir Python installé sur votre système. IronPDF est compatible avec les versions Python 3.x, assurez-vous donc d'avoir une installation de Python compatible.
-
Bibliothèque IronPDF : Installez la bibliothèque IronPDF pour accéder à ses fonctionnalités. Vous pouvez l'installer en utilisant le Package Manager Python (pip) en exécutant la commande suivante dans votre interface de ligne de commande :
pip install ironpdfpip install ironpdfSHELL -
Bibliothèque Tkinter : Tkinter est la boîte à outils GUI standard pour Python. Il est utilisé pour créer l'interface graphique utilisateur pour le visualiseur PDF dans le morceau de code fourni. Tkinter est généralement préinstallé avec Python, mais si vous rencontrez des problèmes, vous pouvez l'installer en utilisant le Package Manager :
pip install tkinterpip install tkinterSHELL -
Bibliothèque Pillow : La bibliothèque Pillow est une version dérivée de la bibliothèque d'imagerie Python (PIL) et fournit des capacités de traitement d'images supplémentaires. Elle est utilisée dans le morceau de code pour charger et afficher les images extraites du PDF. Installez Pillow en utilisant le Package Manager :
pip install pillowpip install pillowSHELL - Environnement de développement intégré (IDE) : L'utilisation d'un IDE pour gérer des projets Python peut grandement améliorer votre expérience de développement. Il offre des fonctionnalités comme l'autocomplétion de code, le débogage et un flux de travail plus rationalisé. Un IDE populaire pour le développement Python est PyCharm. Vous pouvez télécharger et installer PyCharm depuis le site web de JetBrains (https://www.jetbrains.com/pycharm/).
- Éditeur de texte : Sinon, si vous préférez travailler avec un éditeur de texte léger, vous pouvez utiliser n'importe quel éditeur de texte de votre choix, tel que Visual Studio Code, Sublime Text ou Atom. Ces éditeurs offrent la coloration syntaxique et d'autres fonctionnalités utiles pour le développement Python. Vous pouvez également utiliser l'Application IDE propre à Python pour créer des scripts Python.
Créer un projet de visualiseur PDF en utilisant PyCharm
Après avoir installé l'IDE PyCharm, créez un projet Python PyCharm en suivant les étapes ci-dessous :
- Lancer PyCharm : Ouvrez PyCharm depuis le lanceur d'application de votre système ou depuis le raccourci du bureau.
-
Créer un Nouveau Projet : Cliquez sur "Create New Project" ou ouvrez un projet Python existant.
 PyCharm IDE
PyCharm IDE -
Configurer les Paramètres de Projet : Fournissez un nom à votre projet et choisissez l'emplacement pour créer le répertoire du projet. Sélectionnez l'interpréteur Python pour votre projet. Puis cliquez sur "Create".
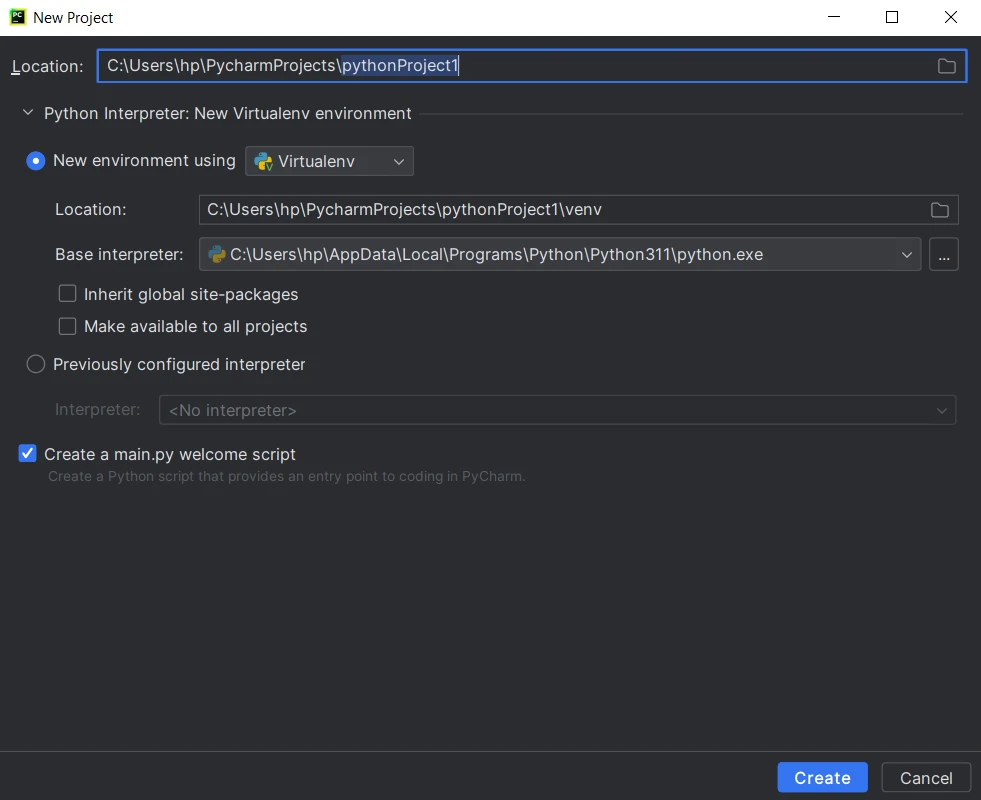 Créer un nouveau projet Python
Créer un nouveau projet Python - Créer des Fichiers Source : PyCharm créera la structure du projet, y compris un fichier Python principal et un répertoire pour les fichiers sources additionnels. Commencez à écrire du code et cliquez sur le bouton d'exécution ou appuyez sur Shift+F10 pour exécuter le script.
Étapes pour visualiser des fichiers PDF en Python avec IronPDF
Importer les bibliothèques requises
Pour commencer, importez les bibliothèques nécessaires. Dans ce cas, les bibliothèques os, shutil, ironpdf, tkinter et PIL seront nécessaires. Les bibliothèques os et shutil sont utilisées pour les opérations sur les fichiers et les dossiers, ironpdf est la bibliothèque pour travailler avec les fichiers PDF, tkinter est utilisée pour créer l'interface utilisateur graphique (GUI), et PIL est utilisé pour la manipulation d'images.
import os
import shutil
import ironpdf
from tkinter import *
from PIL import Image, ImageTkimport os
import shutil
import ironpdf
from tkinter import *
from PIL import Image, ImageTkConvertir le document PDF en images
Ensuite, définissez une fonction appelée convert_pdf_to_images. Cette fonction prend le chemin du fichier PDF en entrée. À l'intérieur de la fonction, la bibliothèque IronPDF est utilisée pour charger le document PDF à partir du fichier. Ensuite, spécifiez un chemin de dossier pour stocker les fichiers d'images extraits. La méthode pdf.RasterizeToImageFiles d'IronPDF est utilisée pour convertir chaque page PDF du PDF en un fichier image et l'enregistrer dans le dossier spécifié. Une liste est utilisée pour stocker les chemins des images. L'exemple de code complet est le suivant :
def convert_pdf_to_images(pdf_file):
"""Convert each page of a PDF file to an image."""
pdf = ironpdf.PdfDocument.FromFile(pdf_file)
# Extract all pages to a folder as image files
folder_path = "images"
pdf.RasterizeToImageFiles(os.path.join(folder_path, "*.png"))
# List to store the image paths
image_paths = []
# Get the list of image files in the folder
for filename in os.listdir(folder_path):
if filename.lower().endswith((".png", ".jpg", ".jpeg", ".gif")):
image_paths.append(os.path.join(folder_path, filename))
return image_pathsdef convert_pdf_to_images(pdf_file):
"""Convert each page of a PDF file to an image."""
pdf = ironpdf.PdfDocument.FromFile(pdf_file)
# Extract all pages to a folder as image files
folder_path = "images"
pdf.RasterizeToImageFiles(os.path.join(folder_path, "*.png"))
# List to store the image paths
image_paths = []
# Get the list of image files in the folder
for filename in os.listdir(folder_path):
if filename.lower().endswith((".png", ".jpg", ".jpeg", ".gif")):
image_paths.append(os.path.join(folder_path, filename))
return image_pathsPour extraire le texte des documents PDF, visitez cette page d'exemples de code.
Gérer la fermeture de la fenêtre
Pour nettoyer les fichiers image extraits lorsque la fenêtre de l'application est fermée, définissez une fonction on_closing. Dans cette fonction, utilisez la méthode shutil.rmtree() pour supprimer l'intégralité du dossier images. Ensuite, définissez cette fonction comme le protocole à exécuter lorsque la fenêtre est fermée. Le code suivant aide à réaliser la tâche :
def on_closing():
"""Handle the window closing event by cleaning up the images."""
# Delete the images in the 'images' folder
shutil.rmtree("images")
window.destroy()
window.protocol("WM_DELETE_WINDOW", on_closing)def on_closing():
"""Handle the window closing event by cleaning up the images."""
# Delete the images in the 'images' folder
shutil.rmtree("images")
window.destroy()
window.protocol("WM_DELETE_WINDOW", on_closing)Créer la fenêtre GUI
Maintenant, créons la fenêtre principale de l'interface graphique en utilisant le constructeur Tk(), définissons le titre de la fenêtre sur " Visionneuse d'images " et définissons la fonction on_closing() comme protocole pour gérer la fermeture de la fenêtre.
window = Tk()
window.title("Image Viewer")
window.protocol("WM_DELETE_WINDOW", on_closing)window = Tk()
window.title("Image Viewer")
window.protocol("WM_DELETE_WINDOW", on_closing)Créer un canevas défilable
Pour afficher les images et activer le défilement, créez un widget Canvas. Le widget Canvas est configuré pour remplir l'espace disponible et s'étendre dans les deux directions à l'aide de pack(side=LEFT, fill=BOTH, expand=True). De plus, créez un widget Scrollbar et configurez-le pour contrôler le défilement vertical de toutes les pages et du canevas.
canvas = Canvas(window)
canvas.pack(side=LEFT, fill=BOTH, expand=True)
scrollbar = Scrollbar(window, command=canvas.yview)
scrollbar.pack(side=RIGHT, fill=Y)
canvas.configure(yscrollcommand=scrollbar.set)
# Update the scrollregion to encompass the entire canvas
canvas.bind("<Configure>", lambda e: canvas.configure(
scrollregion=canvas.bbox("all")))
# Configure the vertical scrolling using mouse wheel
canvas.bind_all("<MouseWheel>", lambda e: canvas.yview_scroll(
int(-1*(e.delta/120)), "units"))canvas = Canvas(window)
canvas.pack(side=LEFT, fill=BOTH, expand=True)
scrollbar = Scrollbar(window, command=canvas.yview)
scrollbar.pack(side=RIGHT, fill=Y)
canvas.configure(yscrollcommand=scrollbar.set)
# Update the scrollregion to encompass the entire canvas
canvas.bind("<Configure>", lambda e: canvas.configure(
scrollregion=canvas.bbox("all")))
# Configure the vertical scrolling using mouse wheel
canvas.bind_all("<MouseWheel>", lambda e: canvas.yview_scroll(
int(-1*(e.delta/120)), "units"))Créer un cadre pour les images
Ensuite, créez un widget Frame à l'intérieur du canevas pour contenir les images en utilisant create_window() pour placer le cadre dans le canevas. Les coordonnées (0, 0) et le paramètre anchor='nw' garantissent que le cadre commence dans le coin supérieur gauche du canevas.
frame = Frame(canvas)
canvas.create_window((0, 0), window=frame, anchor="nw")frame = Frame(canvas)
canvas.create_window((0, 0), window=frame, anchor="nw")Convertir le fichier PDF en images et les afficher
L'étape suivante consiste à appeler la fonction convert_pdf_to_images() avec le chemin d'accès du fichier PDF d'entrée. Cette fonction extrait les pages du PDF sous forme d'images et renvoie une liste de chemins d'accès à ces images. En itérant sur les chemins d'image et en chargeant chaque image à l'aide de la méthode Image.open() de la bibliothèque PIL, un objet PhotoImage est créé à l'aide de ImageTk.PhotoImage(). Créez ensuite un widget Label pour afficher l'image.
images = convert_pdf_to_images("input.pdf")
# Load and display the images in the Frame
for image_path in images:
image = Image.open(image_path)
photo = ImageTk.PhotoImage(image)
label = Label(frame, image=photo)
label.image = photo # Store a reference to prevent garbage collection
label.pack(pady=10)images = convert_pdf_to_images("input.pdf")
# Load and display the images in the Frame
for image_path in images:
image = Image.open(image_path)
photo = ImageTk.PhotoImage(image)
label = Label(frame, image=photo)
label.image = photo # Store a reference to prevent garbage collection
label.pack(pady=10) Le fichier d'entrée
Le fichier d'entrée
Exécuter la boucle principale de la GUI
Enfin, exécutons la boucle d'événements principale en utilisant window.mainloop(). Cela garantit que la fenêtre de la GUI reste ouverte et réactive jusqu'à ce qu'elle soit fermée par l'utilisateur.
window.mainloop()window.mainloop() La sortie de l'UI
La sortie de l'UI
Conclusion
Ce tutoriel a exploré comment visualiser des documents PDF en Python en utilisant la bibliothèque IronPDF. Il a couvert les étapes nécessaires pour ouvrir un fichier PDF et le convertir en une série de fichiers image, puis les afficher dans un canevas défilable, et gérer le nettoyage des images extraites lorsque l'application est fermée.
Pour plus de détails sur la bibliothèque IronPDF for Python, veuillez vous référer à la documentation.
Téléchargez et installez la bibliothèque IronPDF pour Python et obtenez également un essai gratuit pour tester sa fonctionnalité complète dans un développement commercial.
Questions Fréquemment Posées
Comment puis-je afficher des fichiers PDF en Python ?
Vous pouvez utiliser la bibliothèque IronPDF pour afficher des fichiers PDF en Python. Elle vous permet de convertir des pages de PDF en images, qui peuvent ensuite être affichées dans une application GUI utilisant Tkinter.
Quelles sont les étapes nécessaires pour créer un visualiseur de PDF en Python ?
Pour créer un visualiseur de PDF en Python, vous devez installer IronPDF, utiliser Tkinter pour la GUI, et Pillow pour le traitement des images. Convertissez les pages PDF en images à l'aide de IronPDF et affichez-les dans un canevas défilant créé avec Tkinter.
Comment puis-je installer IronPDF pour l'utiliser dans un projet Python ?
Vous pouvez installer IronPDF en utilisant pip en exécutant la commande pip install ironpdf dans votre terminal ou invite de commande.
Quelles bibliothèques sont nécessaires pour construire une application de visualisation de PDF en Python ?
Vous aurez besoin de IronPDF pour la manipulation des PDF, de Tkinter pour la GUI, et de Pillow pour le traitement des images.
Puis-je extraire des images d'un PDF en utilisant Python ?
Oui, IronPDF vous permet d'extraire des images à partir de PDF, qui peuvent ensuite être traitées ou affichées en utilisant la bibliothèque Pillow.
Comment puis-je convertir une page de PDF en image en Python ?
Vous pouvez utiliser la fonctionnalité de IronPDF pour convertir des pages de PDF en formats d'image, qui peuvent ensuite être manipulés ou affichés dans une application Python.
Comment puis-je gérer la fermeture de fenêtre dans une application de visualisation de PDF en Python ?
Dans une application de visualisation de PDF, vous pouvez gérer la fermeture de fenêtre en nettoyant les images extraites et en vous assurant que toutes les ressources sont correctement libérées, souvent en utilisant les fonctions de gestion des évènements de Tkinter.
Comment puis-je sécuriser les fichiers PDF en Python ?
IronPDF fournit des options pour améliorer la sécurité des PDF en ajoutant des mots de passe et des restrictions d'utilisation aux fichiers PDF.
Quel est l'avantage d'utiliser Tkinter dans une application de visualisation de PDF ?
Tkinter vous permet de créer une interface graphique conviviale pour votre visualiseur de PDF, en activant des fonctionnalités comme les vues défilables pour naviguer à travers les pages de PDF.
Quel est le but d'utiliser Pillow dans un projet PDF ?
Pillow est utilisé dans un projet PDF pour traiter les images, telles que le chargement et l'affichage des images qui ont été extraites des fichiers PDF en using IronPDF.