
Python PdfWriter (Tutorial com Exemplo de Código)
IronPDF é uma biblioteca de objetos de arquivo PDF em Python puro, destinada a desenvolvedores Python que desejam escrever ou manipular arquivos PDF em seus aplicativos. O IronPDF destaca-se pela sua simplicidade e versatilidade, tornando-o uma escolha ideal para tarefas que exigem a criação automatizada de PDFs ou a integração da geração de PDFs em sistemas de software.
Este guia irá explorar como o IronPDF, uma biblioteca PDF escrita puramente em Python, pode ser usada para criar arquivos PDF ou atributos de página PDF e para ler arquivos PDF. Este curso incluirá exemplos e trechos de código práticos, proporcionando uma compreensão prática de como usar o PdfWriter do IronPDF for Python em seus projetos Python para escrever arquivos PDF e criar uma nova página em PDF.
Configurando o IronPDF
Instalação
Para começar a usar o IronPDF, você precisará instalá-lo através do Índice de Pacotes do Python. Execute o seguinte comando no terminal:
pip install ironpdf
Escrita e manipulação de arquivos PDF
Criando um novo PDF
O IronPDF simplifica o processo de criação de novos arquivos PDF e de edição de PDFs já existentes. Oferece uma interface intuitiva para gerar documentos, sejam eles um simples PDF de uma página ou um documento mais complexo com vários elementos, como senhas de usuário. Essa funcionalidade é vital para tarefas como geração de relatórios, criação de faturas e muito mais.
from ironpdf import ChromePdfRenderer, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Basic HTML content for the PDF
html = """
<html>
<head>
<title>IronPDF for Python!</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>It's IronPDF World!!</h1>
<a href="https://ironpdf.com/python/"><img src='assets/logo.png' /></a>
</body>
</html>
"""
# Create a PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html)
# Save the rendered PDF to a file
pdf.SaveAs("New PDF File.pdf")from ironpdf import ChromePdfRenderer, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Basic HTML content for the PDF
html = """
<html>
<head>
<title>IronPDF for Python!</title>
<link rel='stylesheet' href='assets/style.css'>
</head>
<body>
<h1>It's IronPDF World!!</h1>
<a href="https://ironpdf.com/python/"><img src='assets/logo.png' /></a>
</body>
</html>
"""
# Create a PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html)
# Save the rendered PDF to a file
pdf.SaveAs("New PDF File.pdf") Arquivo de saída
Arquivo de saída
Unindo arquivos PDF
O IronPDF simplifica a tarefa de combinar vários arquivos PDF em um só. Essa funcionalidade é útil para agregar diversos relatórios, reunir documentos digitalizados ou organizar informações que pertencem ao mesmo grupo. Por exemplo, você pode precisar mesclar arquivos PDF ao criar um relatório abrangente a partir de várias fontes ou quando tiver uma série de documentos que precisam ser apresentados como um único arquivo.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF documents
pdfOne = PdfDocument("Report First.pdf")
pdfTwo = PdfDocument("Report Second.pdf")
# Merge the PDFs into a single document
merged = PdfDocument.Merge(pdfOne, pdfTwo)
# Save the merged PDF
merged.SaveAs("Merged.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load existing PDF documents
pdfOne = PdfDocument("Report First.pdf")
pdfTwo = PdfDocument("Report Second.pdf")
# Merge the PDFs into a single document
merged = PdfDocument.Merge(pdfOne, pdfTwo)
# Save the merged PDF
merged.SaveAs("Merged.pdf")A capacidade de mesclar arquivos PDF existentes em um novo arquivo PDF também pode ser útil em áreas como ciência de dados, onde um documento PDF consolidado pode servir como um conjunto de dados para treinar um módulo de IA. O IronPDF realiza essa tarefa sem esforço, mantendo a integridade e a formatação de cada página dos documentos originais, resultando em um arquivo PDF de saída perfeito e coerente.
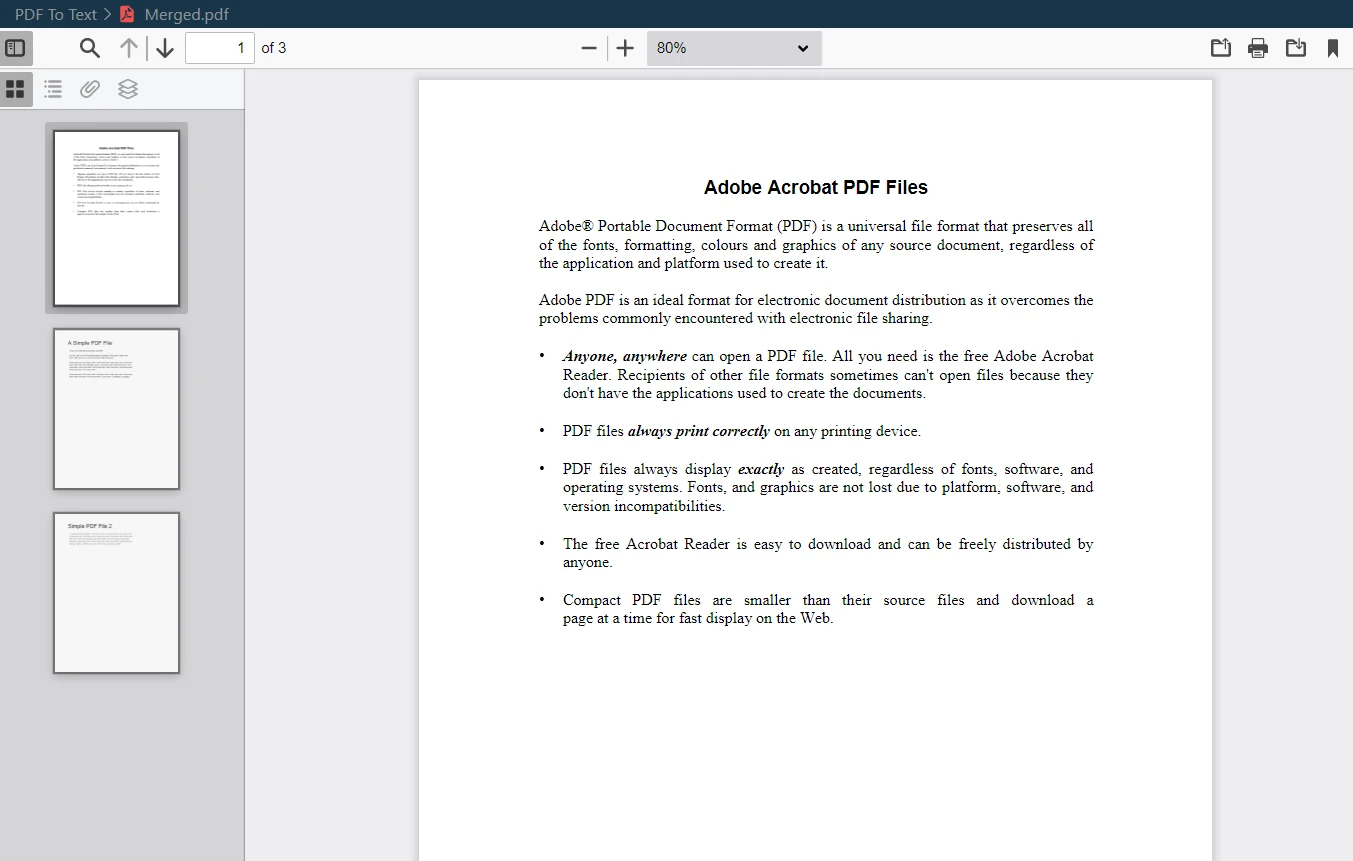 Saída em PDF mesclada
Saída em PDF mesclada
Dividir um único PDF
Por outro lado, o IronPDF também se destaca na divisão de um arquivo PDF existente em vários novos arquivos. Essa função é útil quando você precisa extrair seções específicas de um documento PDF extenso ou quando precisa dividir um documento em partes menores e mais fáceis de gerenciar.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract the first page
page1doc = pdf.CopyPage(0)
# Save the extracted page as a new PDF
page1doc.SaveAs("Split1.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract the first page
page1doc = pdf.CopyPage(0)
# Save the extracted page as a new PDF
page1doc.SaveAs("Split1.pdf")Por exemplo, você pode querer isolar determinadas páginas de um PDF de um relatório extenso ou criar documentos individuais a partir de diferentes capítulos de um livro. O IronPDF permite selecionar as várias páginas desejadas para converter em um novo arquivo PDF, garantindo que você possa manipular e gerenciar o conteúdo do seu PDF conforme necessário.
 Saída em PDF dividida
Saída em PDF dividida
Implementando recursos de segurança
Garantir a segurança dos seus documentos PDF torna-se uma prioridade máxima quando se lida com informações sensíveis ou confidenciais. O IronPDF atende a essa necessidade oferecendo recursos de segurança robustos, incluindo proteção por senha do usuário e criptografia. Isso garante que seus arquivos PDF permaneçam seguros e acessíveis apenas a usuários autorizados.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Adjust security settings to make the PDF read-only and set permissions
pdf.SecuritySettings.RemovePasswordsAndEncryption()
pdf.SecuritySettings.MakePdfDocumentReadOnly("secret-key")
pdf.SecuritySettings.AllowUserAnnotations = False
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = False
pdf.SecuritySettings.AllowUserPrinting = PdfPrintSecurity.FullPrintRights
# Set the document encryption passwords
pdf.SecuritySettings.OwnerPassword = "top-secret" # password to edit the PDF
pdf.SecuritySettings.UserPassword = "sharable" # password to open the PDF
# Save the secured PDF
pdf.SaveAs("secured.pdf")from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Adjust security settings to make the PDF read-only and set permissions
pdf.SecuritySettings.RemovePasswordsAndEncryption()
pdf.SecuritySettings.MakePdfDocumentReadOnly("secret-key")
pdf.SecuritySettings.AllowUserAnnotations = False
pdf.SecuritySettings.AllowUserCopyPasteContent = False
pdf.SecuritySettings.AllowUserFormData = False
pdf.SecuritySettings.AllowUserPrinting = PdfPrintSecurity.FullPrintRights
# Set the document encryption passwords
pdf.SecuritySettings.OwnerPassword = "top-secret" # password to edit the PDF
pdf.SecuritySettings.UserPassword = "sharable" # password to open the PDF
# Save the secured PDF
pdf.SaveAs("secured.pdf")Ao implementar senhas de usuário, você pode controlar quem pode visualizar ou editar seus documentos PDF. As opções de criptografia adicionam uma camada extra de segurança, protegendo seus dados contra acesso não autorizado e tornando o IronPDF uma escolha confiável para gerenciar informações confidenciais em formato PDF.
Extraindo texto de PDFs
Outra característica fundamental do IronPDF é sua capacidade de extrair texto de documentos PDF. Essa funcionalidade é particularmente útil para recuperação de dados, análise de conteúdo ou mesmo para reaproveitar o conteúdo de texto de PDFs existentes em novos documentos.
from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract all text from the PDF document
allText = pdf.ExtractAllText()
# Extract text from a specific page in the document
specificPage = pdf.ExtractTextFromPage(3)from ironpdf import PdfDocument, License, Logger
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load the PDF document
pdf = PdfDocument("Report.pdf")
# Extract all text from the PDF document
allText = pdf.ExtractAllText()
# Extract text from a specific page in the document
specificPage = pdf.ExtractTextFromPage(3)Seja para extrair dados para análise, procurar informações específicas em um documento extenso ou converter conteúdo de PDF para arquivos de texto para processamento posterior, o IronPDF torna tudo simples e eficiente. A biblioteca garante que o texto extraído mantenha sua formatação e estrutura originais, tornando-o imediatamente utilizável para suas necessidades específicas.
Gerenciando informações de documentos
A gestão eficiente de PDFs vai além do seu conteúdo. O IronPDF permite gerenciar de forma eficaz os metadados e propriedades dos documentos, como nome do autor, título do documento, data de criação e muito mais. Essa funcionalidade é vital para organizar e catalogar seus documentos PDF, especialmente em ambientes onde a procedência e os metadados dos documentos são importantes.
from ironpdf import PdfDocument, License, Logger
from datetime import datetime
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF or create a new one
pdf = PdfDocument("Report.pdf")
# Edit file metadata
pdf.MetaData.Author = "Satoshi Nakamoto"
pdf.MetaData.Keywords = "SEO, Friendly"
pdf.MetaData.ModifiedDate = datetime.now()
# Save the PDF with updated metadata
pdf.SaveAs("MetaData Updated.pdf")from ironpdf import PdfDocument, License, Logger
from datetime import datetime
# Set the IronPDF license key
License.LicenseKey = "Your-License-Key"
# Enable logging for debugging purposes
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF or create a new one
pdf = PdfDocument("Report.pdf")
# Edit file metadata
pdf.MetaData.Author = "Satoshi Nakamoto"
pdf.MetaData.Keywords = "SEO, Friendly"
pdf.MetaData.ModifiedDate = datetime.now()
# Save the PDF with updated metadata
pdf.SaveAs("MetaData Updated.pdf")Por exemplo, em um ambiente acadêmico ou corporativo, ser capaz de rastrear a data de criação e a autoria de documentos pode ser essencial para fins de arquivamento e recuperação de documentos. O IronPDF facilita o gerenciamento dessas informações, oferecendo uma maneira simplificada de manipular e atualizar informações de documentos em seus aplicativos Python.
Conclusão
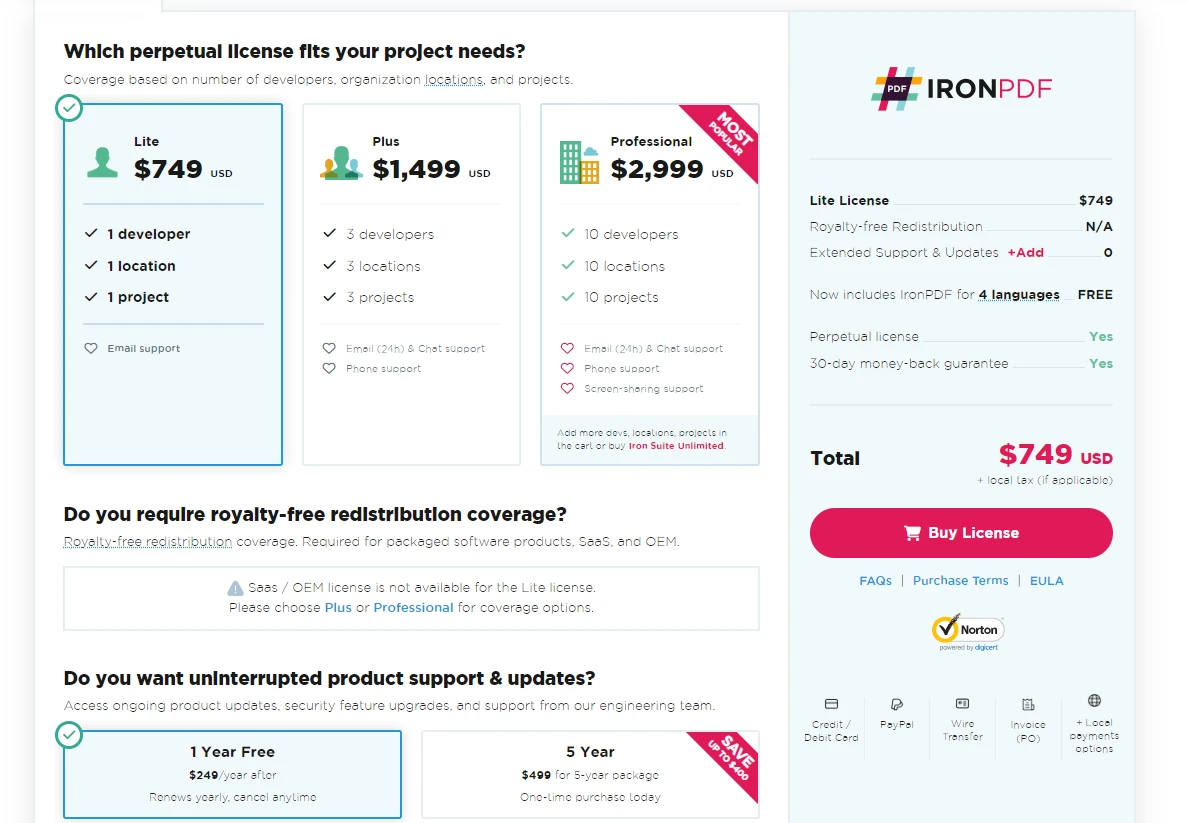 Licença
Licença
Este tutorial abordou os conceitos básicos da utilização do IronPDF em Python para manipulação de PDFs. Desde a criação de novos arquivos PDF até a fusão de arquivos existentes e a adição de recursos de segurança, o IronPDF é uma ferramenta versátil para qualquer desenvolvedor Python.
O IronPDF for Python também oferece os seguintes recursos:
- Crie um novo arquivo PDF do zero usando HTML ou URL
- Edição de arquivos PDF existentes
- Girar páginas do PDF
- Extrair texto , metadados e imagens de arquivos PDF
- Proteja arquivos PDF com senhas e restrições.
- Dividir e mesclar PDFs
O IronPDF for Python oferece um período de teste gratuito para que os usuários explorem seus recursos. Para uso contínuo além do teste, as licenças começam em $999. Essa estrutura de preços permite que os desenvolvedores utilizem toda a gama de recursos do IronPDF em seus projetos.
Perguntas frequentes
Como posso criar um arquivo PDF em Python?
Você pode usar o método CreatePdf do IronPDF para gerar novos arquivos PDF. Esse método permite criar documentos PDF personalizados do zero usando Python.
Quais são os passos para instalar o IronPDF for Python?
Para instalar o IronPDF for Python, você pode usar o Índice de Pacotes do Python executando o comando: pip install ironpdf .
Como faço para mesclar vários PDFs em um só usando Python?
O IronPDF oferece funcionalidades para mesclar vários arquivos PDF. Você pode usar o método MergePdfFiles para combinar diversos PDFs em um único documento.
Posso dividir um PDF em páginas separadas com o IronPDF?
Sim, o IronPDF oferece a função SplitPdf , que permite dividir um PDF em páginas ou seções individuais, criando arquivos separados para cada parte.
Quais recursos de segurança o IronPDF oferece para PDFs?
O IronPDF oferece diversos recursos de segurança, incluindo proteção por senha e criptografia, para garantir que seus arquivos PDF estejam seguros e acessíveis apenas a usuários autorizados.
Como posso extrair texto de um documento PDF em Python?
Com o IronPDF, você pode extrair facilmente texto de documentos PDF usando o método ExtractText , o que é útil para recuperação e análise de dados.
Quais são os principais recursos de manipulação de PDF oferecidos pelo IronPDF?
O IronPDF permite criar, mesclar e dividir PDFs, aplicar medidas de segurança, extrair texto e gerenciar metadados de documentos, como nome do autor e data de criação.
Existe algum período de teste gratuito para o IronPDF? Como posso acessá-lo?
Sim, o IronPDF oferece um período de teste gratuito. Você pode explorar seus recursos durante o período de teste, e as licenças estão disponíveis para compra para uso contínuo após o término do período de teste.
Quais são alguns casos de uso práticos para o IronPDF em projetos Python?
O IronPDF é ideal para gerar relatórios, criar faturas, proteger documentos e gerenciar metadados de PDF em diversos projetos Python.
Como posso gerenciar metadados de PDF usando o IronPDF?
O IronPDF permite gerenciar metadados de PDFs, incluindo nomes de autores, títulos de documentos e datas de criação, o que é crucial para a organização e catalogação de documentos.
















