
Python'da Tarayıcı PDF'leri Okuma
Dijital dönüşüm çağında, bilgi paylaşımı ve korunması için PDF belgelerinin vazgeçilmezliği abartılamaz.
Ancak, genellikle aranabilir metin yerine görüntüler içeren tarandığı PDF'ler'in yaygınlığı, değerli verileri çıkarmaya çalışırken büyük bir zorluk oluşturur.
Bu, Python'un farklı görevleri otomatikleştirmek için gidilecek bir programlama dili olarak kendini kurarak çok yönlü ve güçlü bir çözüm olarak ortaya çıktığı yerdir, taranmış belgelerden bilgi çıkarma bunun ilk örneğidir.
Python'un esnekliği ve sağlam yetenekleri, kullanıcıların taranmış içeriğin karmaşıklıklarını verimli bir şekilde aşmasına olanak tanır ve görüntü tabanlı PDF'lerden veri alıp kullanma konusunda streamline bir yaklaşım sunar.
Python, gelişmiş işlevselliği ile en çok kullanılan programlama dillerinden biridir. Python programlama dili ve yapılandırılmış biçimi hakkında bilgi almak için Python Wikipedia sayfasını ziyaret edin.
IronPDF PDF Kütüphanesi yardımıyla Python Programlama Dilinde nasıl taranan PDF'lerin okunabileceğini tartışacağız.
Python'da Taranmış PDF Nasıl Okunur
- PyCharm içinde yeni bir proje oluşturun.
- İlk önce taranan PDF dosyasını okumak için IronPDF PDF Kütüphanesini yükleyin.
- Gerekli bağımlılıkları içe aktarın.
- Tarama yapılmış PDF dosyasını
PdfDocument.FromFileyöntemi ile yükleyin. - Taramalı PDF'den tüm metni
ExtractAllTextyöntemi ile çıkarın. - PDF dosyasındaki tüm metni
print()yöntemi ile yazdırın.
IronPDF for Python
IronPDF Python için, Iron Software tarafından geliştirilen, Python uygulamalarına PDF oluşturma ve manipülasyon yeteneklerinin nahtif bir entegrasyonunu sağlayan sağlam bir kütüphanedir.
Bu çok yönlü araç, geliştiricilerin dinamik rapor oluşturma, HTML'den PDF'ye dönüştürme ve mevcut PDF dosyalarından içerik çıkarma gibi görevleri destekleyerek, PDF belgeleri üretme, değiştirme ve etkileşimde bulunma işlemlerini kolaylıkla gerçekleştirmelerine olanak tanır.
Kullanıcı dostu API'si, kapsamlı dokümantasyonu ve çeşitli özellikleri ile IronPDF, Python projelerine gelişmiş PDF işlevselliği ekleme sürecini basitleştirir, uygulamalarını profesyonel düzeyde belge işleme yetenekleri ile zenginleştirmek isteyen geliştiriciler için değerli bir kaynak haline getirir.
IronPDF Özellikleri
Python için IronPDF, PDF oluşturma ve metin dosya yapısı manipülasyonu için güçlü bir araç haline getiren çeşitli özelliklerle donatılmıştır.
Bazı temel özellikleri şunlardır:
- HTML'den PDF'ye Dönüştürme: CSS ve resimler dahil olmak üzere HTML içeriğini yüksek kaliteli PDF belgelerine dönüştürün, böylece geliştiriciler, PDF üretim süreçlerinde mevcut web tabanlı içerikleri kullanarak aranabilir PDF dosyaları oluşturabilirler.
- Metin ve Görüntü Manipülasyonu: PDF belgeleri içinde metin, resim ve diğer öğeleri kolayca ekleyin ve manipüle edin, üretilen PDF'lerin düzeni ve görünümü üzerinde ince ayar yapma kontrolü sağlayın.
- Belge Birleştirme ve Bölme: Birden fazla PDF belgesini tek bir dosya halinde birleştirin veya büyük PDF'leri daha küçük, daha yönetilebilir dosyalara ayırın, belge organizasyonunda esneklik sağlar.
- PDF Formları: İş uygulamalarında formla ilgili görevlerin otomasyonunu kolaylaştırmak için etkileşimli PDF formları programatik olarak oluşturun ve doldurun.
- Güvenlik Özellikleri: PDF belgelerini güvence altına almak için şifreleme ve parola koruması uygulayın, hassas bilgilerin gizli kalmasını ve yetkisiz erişimden korunmasını sağlayın.
- Metin Çıkarma: PDF belgelerinden analiz veya dizinleme amacıyla metin içeriğini çıkarın, böylece geliştiricilerin, IronPDF'in metin tanıma yeteneği ile PDF dosyalarında içindeki metin verileri ile çalışabilmelerini sağlar.
Python için IronPDF Nasıl Kurulur
Kod eğitimine başlamadan önce, ilk olarak Python için IronPDF'nin nasıl kurulacağını görelim.
İlk olarak, sistemde Python'un kurulu olduğundan ve PyCharm gibi iyi bir Python IDE'ye sahip olduğunuzdan emin olun. Ayrıca IronPDF for Python'u yüklemek için PIP kurulu olmalıdır.
- İlk olarak, yeni bir Python projesi oluşturun veya mevcut birini açın.
Konsolu açın ve şu komutu çalıştırın ve enter tuşuna basın.
pip install ironpdf
- Böylece, IronPDF for Python projenize entegre edilmiş olur.
Python İçin IronPDF Kullanarak Taranmış PDF Dosyalarını Okuma
Bu bölümde, IronPDF kullanarak taranan PDF dosyalarından nasıl metin çıkarabileceğinizi göreceğiz.
from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)Yukarıdaki kod örneği, taranan PDF dosyalarından metin çıkarmaktadır. Yukarıdaki kodun ayrıntılı açıklaması aşağıdadır:
IronPDF Modülünü İçe Aktar:
from ironpdf import *from ironpdf import *PYTHONBu satır, IronPDF kütüphanesinden gerekli modülleri ve sınıfları içe aktarıyor. Yıldız işareti (
*), modülden tüm sınıfların ve fonksiyonların içe aktarılması gerektiğini belirtir.Lisans Anahtarını Ayarla:
License.LicenseKey = "Your License Key"License.LicenseKey = "Your License Key"PYTHONBu satır, IronPDF için lisans anahtarını ayarlar.
"Your License Key", Iron Software'dan aldığınız gerçek lisans anahtarı ile değiştirmeniz gerekmektedir.Lisans anahtarı, IronPDF'yi kullanmak için gereklidir ve genellikle ürünü satın aldığınızda verilir.
Taranmış PDF Belgesi Yükleme:
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")PYTHONBu satır, belirtilen dosya yolundaki (
"C:/Users/buttw/INV_2023_00008.pdf") taranan PDF belgesini yükler.PdfDocument.FromFileyöntemi, verilen dosyadan birPdfDocumentnesnesi oluşturmak için kullanılır.PDF Belgesinden Metin Çıkartma:
all_text = pdf.ExtractAllText()all_text = pdf.ExtractAllText()PYTHONBu satır, tüm sayfalardan ExtractAllText yöntemi kullanılarak yüklenen PDF belgesinden metin içeriğini çıkartır. Çıkarılan metin daha sonra
all_textdeğişkeninde saklanır.Çıkarılan Metni Yazdırma:
print(all_text)print(all_text)PYTHONSon olarak, bu satırda çıkarılan metin konsola yazdırılır.
all_textdeğişkeni, taranan PDF belgesinin metin içeriğini içerir.
Giriş PDF
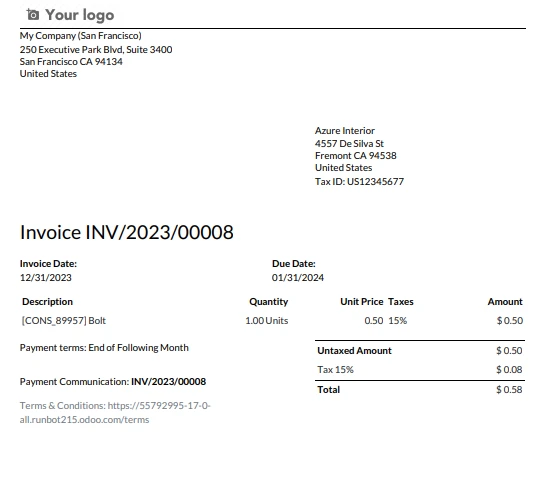
çıkış metni
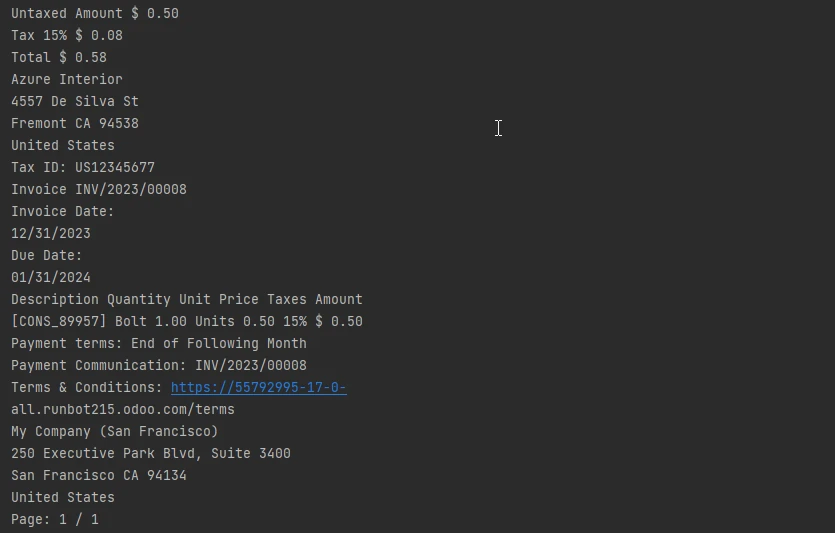
Sonuç
Dijital belge işleme alanında, aranabilir metin yerine resimler içeren taranan PDF'ler tarafından ortaya konulan zorlukları aşmak için Python programlama dili çok yönlü bir çözüm olarak ortaya çıkıyor.
Python'un esnekliği ve IronPDF for Python'un sağlam yetenekleri arasındaki sinerji, geliştiriciler için PDF oluşturma, manipülasyon ve çıkarma işlevlerini projelerine sorunsuz bir şekilde entegre etmeleri için etkileyici bir yol sunar.
Iron Software tarafından geliştirilen IronPDF, PDF dosyalarını çeşitli belge türlerinden dönüştürme, HTML'den PDF sayfasına dönüştürme, metin ve görüntü manipülasyonu ve taranmış PDF'lerden OCR tabanlı metin çıkarma gibi özellikler sunarak bu konuda etkili olur.
Sunulan kod örneği, taranan bir PDF sayfasından metin okuma için IronPDF'in doğrudan uygulanmasını göstererek, verimli veri çıkarma potansiyelini ve Python uygulamalarında belge işleme yeteneklerini artırmayı göstermektedir.
Gelişmiş PDF işlemi için talep artmaya devam ederken, Python için IronPDF, geliştiricilerin taranan içeriğin karmaşıklıklarını rahatça geçmeyelerine olanak tanıyan değerli bir araç olarak duruyor.
Python için IronPDF, geliştiricilerin IronPDF'un özelliklerini tanıması için harika bir fırsat olan bir deneme lisansı sunmaktadır.
Taranmış PDF'lerden metin çıkartma üzerine kapsamlı eğitim burada bulunabilir.
Sıkça Sorulan Sorular
Python'da taranmış bir PDF'den metni nasıl okuyabilirim?
Python'da taranmış bir PDF'den metin okumak için, IronPDF'nin OCR yeteneklerini kullanabilirsiniz. Öncelikle, pip install ironpdf komutuyla IronPDF'yi yükleyin. Ardından, PDF'nizi PdfDocument.FromFile kullanarak yükleyin ve ExtractAllText yöntemi ile metni çıkarın.
Taranmış PDF'lerde metin çıkarma için hangi zorluklar mevcuttur?
Taranmış PDF'ler genellikle içeriği metin olarak değil, resim olarak saklar, bu da metni çıkarıp yönetilebilir bir formata dönüştürmek için IronPDF’nin OCR gibi özel araçların kullanımını gerektirir.
IronPDF, Python'da PDF manipülasyonunu nasıl kolaylaştırır?
IronPDF, metin çıkarma, HTML'den PDF'ye dönüştürme, belge birleştirme ve bölme ve etkileşimli PDF formları ile çalışma gibi PDF manipülasyon araçları sunarak, Python uygulamalarının belge yönetimi yeteneklerini artırır.
Python ortamında IronPDF'yi kurmak için ne gereklidir?
Python'da IronPDF'yi kurmak için, sisteminize Python ve PIP yüklü olduğundan emin olun. Ardından, kütüphaneyi yüklemek için pip install ironpdf komutunu çalıştırın, böylece Python projelerinizde PDF'lerle işlem yapmaya başlayabilirsiniz.
Python'da HTML içeriğini PDF'lere IronPDF ile dönüştürebilir miyim?
Evet, IronPDF, yüksek kaliteli PDF belgelerine CSS ve resimler dâhil HTML içeriğini dönüştürebilir, web içeriğinden PDF oluşturması gereken geliştiriciler için çok yönlü bir araçtır.
IronPDF'yi satın almadan önce denemenin bir yolu var mı?
IronPDF, alım kararı vermeden önce OCR ve PDF manipulasyonu dâhil tüm özellik yelpazesini keşfetmek için bir deneme lisansı sunar.
Python, taranmış PDF'leri işlemek için neden iyi bir pilihan?
Python, IronPDF gibi güçlü kütüphanelerin mevcudiyeti nedeniyle taranmış PDF'leri işlemede tercih edilen bir dildir, bu da metin çıkarma ve PDF manipulasyon görevlerini basitleştirir.
IronPDF for Python'un bazı ana özellikleri nelerdir?
IronPDF for Python'un ana özellikleri arasında taranmış PDF'ler için OCR, HTML'den PDF'ye dönüştürme, belge birleştirme ve bölme, metin ve resim manipulasyonu ve etkileşimli form manipulasyonu yer alır; kapsamlı PDF işleme çözümleri sunar.
















