
So lesen Sie gescannte PDFs in Python
In der Ära der digitalen Transformation kann die Unverzichtbarkeit von PDF-Dokumenten zum Teilen und Bewahren von Informationen nicht genug betont werden.
Die Verbreitung von gescannten PDFs, die oft Bilder anstelle von durchsuchbarem Text enthalten, stellt jedoch eine erhebliche Herausforderung beim Extrahieren wertvoller Daten dar.
Hier erweist sich Python als vielseitige und leistungsstarke Lösung und etabliert sich als Anlaufstelle für die Automatisierung verschiedener Aufgaben, wobei die Informationsextraktion aus gescannten Dokumenten ein erstklassiges Beispiel ist.
Die Flexibilität und robusten Fähigkeiten von Python ermöglichen es Benutzern, effizient durch die Komplexitäten gescannter Inhalte zu navigieren, und bieten einen schlanken Ansatz, um auf Daten aus bildbasierten PDFs zuzugreifen und diese zu nutzen.
Python ist eine der am häufigsten verwendeten Programmiersprachen mit seiner fortschrittlichen Funktionalität. Besuchen Sie die Python-Wikipedia-Seite, um sich über die Programmiersprache Python und ihr strukturiertes Format zu informieren.
In diesem Artikel werden wir diskutieren, wie man gescannte PDFs in der Programmiersprache Python mit Hilfe von IronPDF für die Python PDF-Bibliothek lesen kann.
Wie man gescannte PDFs in Python liest
- Erstellen Sie ein neues Projekt in PyCharm.
- Installieren Sie zuerst die IronPDF PDF-Bibliothek, um die gescannte PDF-Datei zu lesen.
- Importieren Sie die erforderlichen Abhängigkeiten.
- Laden Sie die gescannte PDF-Datei mit der Methode
PdfDocument.FromFile. - Extrahieren Sie den gesamten Text aus der gescannten PDF-Datei mithilfe der Methode
ExtractAllText. - Drucken Sie den gesamten Text aus der PDF-Datei mit der Methode
print().
IronPDF for Python
IronPDF für Python ist eine robuste Bibliothek, die von Iron Software entwickelt wurde und eine nahtlose Integration von PDF-Erstellungs- und Manipulationsfunktionen in Python-Anwendungen ermöglicht.
Dieses vielseitige Werkzeug befähigt Entwickler, mühelos PDF-Dokumente zu erstellen, zu ändern und zu interagieren, wobei Aufgaben wie die Erzeugung dynamischer Berichte, die Konvertierung von HTML in PDF und das Extrahieren von Inhalten aus vorhandenen PDF-Dateien unterstützt werden.
Mit einer benutzerfreundlichen API, umfassender Dokumentation und einer Vielzahl von Funktionen vereinfacht IronPDF den Prozess des Einbaus von fortschrittlichen PDF-Funktionalitäten in Python-Projekte und macht es zu einer unschätzbaren Ressource für Entwickler, die ihre Anwendungen mit professionellen Dokumentenverarbeitungsmöglichkeiten erweitern möchten.
IronPDF Funktionen
IronPDF for Python ist mit einer Reihe von Funktionen ausgestattet, die es zu einem leistungsstarken Werkzeug für die PDF-Erzeugung und -Textstrukturmanipulation machen.
Einige seiner wichtigsten Funktionen sind:
- HTML zu PDF-Konvertierung: Konvertieren Sie HTML-Inhalte, einschließlich CSS und Bilder, in hochwertige PDF-Dokumente, damit Entwickler vorhandene webbasierte Inhalte in ihren PDF-Erzeugungsprozessen nutzen und durchsuchbare PDF-Dateien erstellen können.
- Text- und Bildbearbeitung: Fügen Sie Text, Bilder und andere Elemente in PDF-Dokumente ein und bearbeiten Sie diese einfach, um eine feingliedrige Kontrolle über das Layout und die Erscheinung der erzeugten PDFs zu erhalten.
- Dokumenten Zusammenführen und Teilen: Kombinieren Sie mehrere PDF-Dokumente zu einer einzigen Datei oder teilen Sie große PDFs in kleinere, handlichere Dateien auf, um Flexibilität in der Dokumentenorganisation zu bieten.
- PDF-Formulare: Erstellen und füllen Sie interaktive PDF-Formulare programmatisch aus, um die Automatisierung formularbezogener Aufgaben in Geschäftsapplikationen zu erleichtern.
- Sicherheitsfeatures: Implementieren Sie Verschlüsselung und Passwortschutz, um PDF-Dokumente zu sichern und sicherzustellen, dass vertrauliche Informationen vor unbefugtem Zugriff geschützt bleiben.
- Textextraktion: Extrahieren Sie Textinhalte aus PDF-Dokumenten zu Analyse- oder Indexierungszwecken, sodass Entwickler mit den in PDF-Dateien enthaltenen Textdaten mit der Texterkennungsfähigkeit von IronPDF arbeiten können.
Installation von IronPDF for Python
Bevor wir mit dem Code-Tutorial beginnen, sehen wir uns erst an, wie IronPDF for Python installiert werden kann.
Stellen Sie zuerst sicher, dass Python auf dem System installiert ist und Sie eine gute Python-IDE wie PyCharm haben. Außerdem sollte PIP installiert sein, um IronPDF for Python zu installieren.
- Erstellen Sie zunächst ein neues Python-Projekt oder öffnen Sie ein bestehendes.
-
Öffnen Sie die Konsole und führen Sie den folgenden Befehl aus und drücken Sie Enter.
pip install ironpdfpip install ironpdfSHELL - So wird IronPDF for Python nahtlos in Ihr Python-Projekt integriert.
Lesen von gescannten PDF-Dateien mit IronPDF for Python
In diesem Abschnitt sehen wir, wie Sie Text aus gescannten PDF-Dateien extrahieren können, indem Sie IronPDF verwenden.
from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)Das obige Codebeispiel extrahiert Text aus gescannten PDF-Dateien. Nachfolgend finden Sie die Aufschlüsselung des obigen Codes:
-
Importieren des IronPDF-Moduls:
from ironpdf import *from ironpdf import *PYTHONDiese Zeile importiert die notwendigen Module und Klassen aus der IronPDF-Bibliothek. Das Sternchen (
*) bedeutet, dass alle Klassen und Funktionen aus dem Modul importiert werden müssen. -
Setzen des Lizenzschlüssels:
License.LicenseKey = "Your License Key"License.LicenseKey = "Your License Key"PYTHONDiese Zeile setzt den Lizenzschlüssel für IronPDF. Sie müssen
"Your License Key"durch den tatsächlichen Lizenzschlüssel ersetzen, den Sie von Iron Software erhalten haben.
Der Lizenzschlüssel ist notwendig für die Nutzung von IronPDF und wird in der Regel bereitgestellt, wenn Sie das Produkt kaufen.
-
Laden eines gescannten PDF-Dokuments:
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")PYTHONDiese Zeile lädt ein gescanntes PDF-Dokument, das sich unter dem angegebenen Dateipfad befindet (
"C:/Users/buttw/INV_2023_00008.pdf"). Die MethodePdfDocument.FromFilewird verwendet, um einPdfDocument-Objekt aus der angegebenen Datei zu erstellen. -
Text aus PDF-Dokument extrahieren:
all_text = pdf.ExtractAllText()all_text = pdf.ExtractAllText()PYTHONDiese Zeile extrahiert den gesamten Textinhalt aus dem geladenen PDF-Dokument mit der ExtractAllText-Methode von allen Seiten. Der extrahierte Text wird dann in der Variable
all_textgespeichert. -
Extrahierten Text drucken:
print(all_text)print(all_text)PYTHONSchließlich druckt diese Zeile den extrahierten Text auf der Konsole aus. Die Variable
all_textenthält den Textinhalt des gescannten PDF-Dokuments.
Eingabe-PDF
Ausgabetext
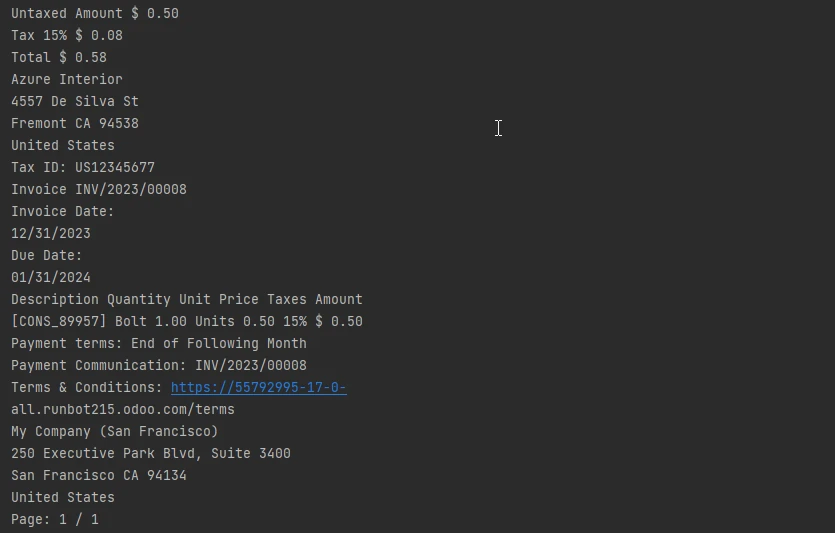
Abschluss
Im Bereich der digitalen Dokumentenverarbeitung erweist sich die Programmiersprache Python als vielseitige Lösung zur Überwindung der Herausforderungen, die durch gescannte PDFs entstehen, die Bilder anstelle von durchsuchbarem Text enthalten.
Die Synergie zwischen der Flexibilität von Python und den robusten Fähigkeiten von IronPDF for Python bietet einen überzeugenden Weg für Entwickler, um PDF-Erzeugung, -Manipulation und -Extraktionsfunktionalitäten nahtlos in ihre Projekte zu integrieren.
IronPDF, entwickelt von Iron Software, erweist sich in dieser Hinsicht als einflussreich, indem es Funktionen wie das Umwandeln von PDF-Dateien aus verschiedenen Dokumenttypen, HTML-zu-PDF-Seitenkonvertierung, Text- und Bildbearbeitung sowie OCR-basierte Textextraktion aus gescannten PDFs bietet.
Das präsentierte Codebeispiel zeigt die unkomplizierte Implementierung von IronPDF zur Textextraktion aus einer gescannten PDF-Seite, und demonstriert das Potenzial für eine effiziente Datenextraktion und die Verbesserung der Dokumentenverarbeitungsmöglichkeiten in Python-Anwendungen.
Da die Nachfrage nach anspruchsvoller PDF-Handhabung weiterhin steigt, steht IronPDF for Python als wertvolles Werkzeug bereit, das Entwicklern hilft, die Komplexitäten von gescannten Inhalten mit Leichtigkeit zu meistern.
IronPDF for Python bietet eine Testlizenz, die eine großartige Gelegenheit für Entwickler darstellt, um die Funktionen von IronPDF kennenzulernen.
Das vollständige Tutorial zur Textextraktion aus gescannten PDFs finden Sie hier.
Häufig gestellte Fragen
Wie kann ich Text aus einem gescannten PDF in Python lesen?
Um Text aus einem gescannten PDF in Python zu lesen, können Sie die OCR-Fähigkeiten von IronPDF verwenden. Zuerst installieren Sie IronPDF mit pip install ironpdf. Laden Sie dann Ihr PDF mit PdfDocument.FromFile und extrahieren Sie den Text mit der Methode ExtractAllText.
Welche Herausforderungen bieten gescannte PDFs bei der Textextraktion?
Gescannte PDFs speichern Inhalte oft als Bilder, nicht als durchsuchbaren Text, und erfordern spezielle Werkzeuge wie IronPDFs OCR, um den Text zu extrahieren und in ein verwaltbares Format zu konvertieren.
Wie erleichtert IronPDF die PDF-Bearbeitung in Python?
IronPDF bietet eine Reihe von Werkzeugen zur PDF-Bearbeitung, einschließlich Textextraktion, HTML-zu-PDF-Konvertierung, Dokumenten-Zusammenführung und -Teilung sowie die Arbeit mit interaktiven PDF-Formularen, wodurch die Dokumentverarbeitungskapazitäten von Python-Anwendungen erweitert werden.
Was ist erforderlich, um IronPDF in einer Python-Umgebung einzurichten?
Um IronPDF in Python einzurichten, stellen Sie sicher, dass Python und PIP auf Ihrem System installiert sind. Führen Sie dann pip install ironpdf aus, um die Bibliothek zu installieren und Ihnen die Manipulation von PDFs in Ihren Python-Projekten zu ermöglichen.
Kann IronPDF HTML-Inhalte in PDFs in Python konvertieren?
Ja, IronPDF kann HTML-Inhalte, einschließlich CSS und Bilder, in hochwertige PDF-Dokumente konvertieren und ist damit ein vielseitiges Werkzeug für Entwickler, die PDFs aus Webinhalten erstellen müssen.
Gibt es eine Möglichkeit, IronPDF vor dem Kauf auszuprobieren?
IronPDF bietet eine Testlizenz an, die es Entwicklern ermöglicht, den vollen Funktionsumfang, einschließlich OCR und PDF-Bearbeitung, zu erkunden, bevor sie sich für einen Kauf entscheiden.
Warum ist Python eine gute Wahl zur Bearbeitung gescannter PDFs?
Python ist aufgrund seiner Flexibilität und der Verfügbarkeit von robusten Bibliotheken wie IronPDF, die Aufgaben wie Textextraktion und PDF-Bearbeitung vereinfachen, eine bevorzugte Sprache zur Bearbeitung gescannter PDFs.
Was sind einige Hauptmerkmale von IronPDF for Python?
Hauptmerkmale von IronPDF for Python sind OCR für gescannte PDFs, HTML-zu-PDF-Konvertierung, Dokument-Zusammenführung und -Teilung, Text- und Bildbearbeitung sowie die Handhabung interaktiver Formulare, die umfassende PDF-Verarbeitungslösungen bieten.
















