Comment lire des PDF scannés en Python
À l'ère de la transformation numérique, l'indispensabilité des documents PDF pour le partage et la préservation des informations ne peut être surestimée.
Cependant, la prévalence des PDF numérisés, qui contiennent souvent des images plutôt que du texte interrogeable, présente un défi significatif lorsqu'il s'agit d'extraire des données précieuses.
C'est là que Python émerge comme une solution polyvalente et puissante, s'établissant comme un langage de programmation incontournable pour automatiser des tâches diverses, avec l'extraction d'informations de documents numérisés comme un exemple clé.
La flexibilité et les capacités robustes de Python permettent aux utilisateurs de naviguer efficacement à travers les complexités du contenu numérisé, fournissant une approche simplifiée pour accéder et utiliser les données provenant de PDF basés sur des images.
Python est l'un des langages de programmation les plus utilisés avec ses fonctionnalités avancées. Visitez la page Wikipédia de Python pour en savoir plus sur le langage de programmation Python et son format structuré.
Dans cet article, nous discuterons de la façon de lire des PDF numérisés dans le langage de programmation Python avec l'aide d'IronPDF pour la bibliothèque PDF Python.
Comment lire un PDF numérisé en Python
- Créez un nouveau projet dans PyCharm.
- Pour lire le fichier PDF numérisé, installez d'abord la bibliothèque PDF IronPDF.
- Importez les dépendances requises.
- Chargez le fichier PDF numérisé en utilisant la méthode
PdfDocument.FromFile. - Extraire tout le texte du PDF numérisé en utilisant la méthode
ExtractAllText. - Imprimez tout le texte du fichier PDF en utilisant la méthode
print().
IronPDF for Python
IronPDF pour Python est une bibliothèque robuste développée par Iron Software, permettant une intégration transparente des capacités de génération et de manipulation de PDF dans des applications Python.
Cet outil polyvalent permet aux développeurs de créer, modifier et interagir sans effort avec des documents PDF, prenant en charge des tâches telles que la génération de rapports dynamiques, la conversion HTML en PDF, et l'extraction de contenu à partir de fichiers PDF existants.
Avec une API conviviale, une documentation complète, et une gamme de fonctionnalités, IronPDF simplifie le processus d'incorporation de fonctionnalités PDF avancées dans des projets Python, en faisant une ressource inestimable pour les développeurs cherchant à améliorer leurs applications avec des capacités de traitement documentaire de qualité professionnelle.
Fonctionnalités d'IronPDF
IronPDF for Python est équipé d'une gamme de fonctionnalités qui en font un outil puissant pour la génération de PDF et la manipulation de la structure des fichiers texte.
Certaines de ses fonctionnalités clés incluent:
- Conversion HTML en PDF : Convertissez du contenu HTML, y compris CSS et images, en documents PDF de haute qualité, permettant aux développeurs de tirer parti du contenu web existant dans leurs processus de génération de PDF et de créer des fichiers PDF interrogeables.
- Manipulation de texte et d'image : Ajoutez et manipulez facilement du texte, des images et d'autres éléments dans des documents PDF, offrant un contrôle précis sur la mise en page et l'apparence des PDF générés.
- Fusion et division de documents : Combinez plusieurs documents PDF en un seul fichier ou divisez de grands PDF en fichiers plus petits et plus faciles à gérer, offrant une flexibilité dans l'organisation des documents.
- Formulaires PDF : Créez et remplissez des formulaires PDF interactifs de manière programmatique, facilitant l'automatisation des tâches liées aux formulaires dans les applications professionnelles.
- Fonctionnalités de sécurité : Mettez en œuvre le chiffrement et la protection par mot de passe pour sécuriser les documents PDF, garantissant que les informations sensibles restent confidentielles et protégées contre un accès non autorisé.
- Extraction de texte : Extrayez le contenu texte des documents PDF à des fins d'analyse ou d'indexation, permettant aux développeurs de travailler avec les données textuelles contenues dans les fichiers PDF grâce à la capacité de reconnaissance de texte d'IronPDF.
Installer IronPDF for Python
Avant de commencer avec le tutoriel de code, voyons d'abord comment vous pouvez installer IronPDF for Python.
Tout d'abord, assurez-vous que Python est installé sur le système, et que vous avez un bon IDE Python comme PyCharm. De plus, PIP doit être installé pour installer IronPDF for Python.
- Tout d'abord, créez un nouveau projet Python ou ouvrez un projet existant.
-
Ouvrez la console et exécutez la commande suivante et appuyez sur entrer.
pip install ironpdfpip install ironpdfSHELL - Tout comme ça, IronPDF for Python est intégré dans votre projet Python.
Lire des fichiers PDF numérisés à l'aide de IronPDF for Python
Dans cette section, nous verrons comment vous pouvez extraire du texte de fichiers PDF numérisés avec IronPDF.
from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)L'exemple de code ci-dessus extrait le texte des fichiers PDF numérisés. Ci-dessous est une décomposition de l'exemple de code ci-dessus :
-
Importez le module IronPDF :
from ironpdf import *from ironpdf import *PYTHONCette ligne importe les modules et classes nécessaires de la bibliothèque IronPDF. L'astérisque (
*) indique que toutes les classes et fonctions du module doivent être importées. -
Définissez la clé de licence :
License.LicenseKey = "Your License Key"License.LicenseKey = "Your License Key"PYTHONCette ligne définit la clé de licence pour IronPDF. Vous devez remplacer
"Your License Key"par la clé de licence réelle que vous avez obtenue auprès d' Iron Software.La clé de licence est nécessaire pour utiliser IronPDF et est généralement fournie lorsque vous achetez le produit.
-
Chargez un document PDF numérisé :
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")PYTHONCette ligne charge un document PDF numérisé situé à l'emplacement spécifié (
"C:/Users/buttw/INV_2023_00008.pdf"). La méthodePdfDocument.FromFileest utilisée pour créer un objetPdfDocumentà partir du fichier donné. -
Extrayez le texte du document PDF :
all_text = pdf.ExtractAllText()all_text = pdf.ExtractAllText()PYTHONCette ligne extrait tout le contenu texte du document PDF chargé en utilisant la méthode ExtractAllText de toutes les pages. Le texte extrait est ensuite stocké dans la variable
all_text. -
Imprimez le texte extrait :
print(all_text)print(all_text)PYTHONEnfin, cette ligne imprime le texte extrait dans la console. La variable
all_textcontient le contenu textuel du document PDF numérisé.
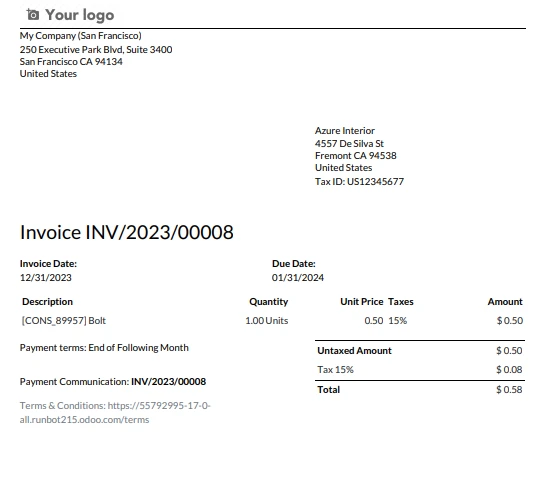
PDF d'entrée
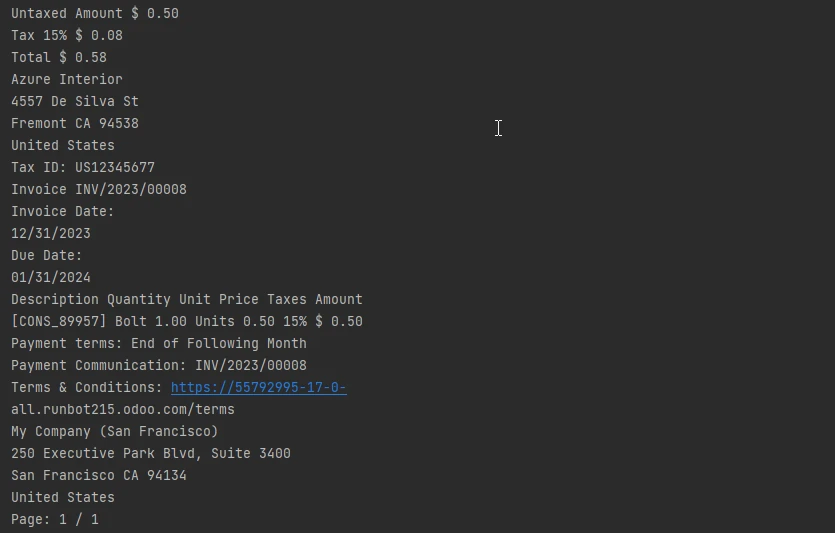
Texte de sortie
Conclusion
Dans le domaine du traitement des documents numériques, le langage de programmation Python émerge comme une solution polyvalente pour surmonter les défis posés par les PDF numérisés contenant des images au lieu de texte interrogeable.
La synergie entre la flexibilité de Python et les capacités robustes d'IronPDF for Python offre une voie convaincante pour les développeurs pour intégrer sans effort des fonctionnalités de génération, de manipulation et d'extraction de PDF dans leurs projets.
IronPDF, développé par Iron Software, se révèle instrumental à cet égard, offrant des caractéristiques telles que la conversion de fichiers PDF à partir de divers types de documents, la conversion de page HTML en PDF, la manipulation de texte et d'image, et l'extraction de texte basée sur l'OCR à partir de PDF numérisés.
L'exemple de code présenté démontre l'implémentation simple d'IronPDF pour lire le texte à partir d'une page PDF numérisée, montrant le potentiel pour une extraction de données efficace et l'amélioration des capacités de traitement documentaire dans les applications Python.
Alors que la demande pour une gestion sophistiquée des PDF continue de croître, IronPDF for Python se tient comme un outil précieux permettant aux développeurs de naviguer dans les complexités du contenu numérisé avec facilité.
IronPDF for Python propose une licence d'essai, qui est une excellente opportunité pour les développeurs de découvrir les fonctionnalités d'IronPDF.
Le tutoriel complet sur l'extraction de texte à partir de PDF numérisés peut être trouvé ici.
Questions Fréquemment Posées
Comment puis-je lire le texte d'un PDF scanné en Python ?
Pour lire le texte d'un PDF scanné en Python, vous pouvez utiliser les capacités OCR d'IronPDF. Tout d'abord, installez IronPDF avec pip install ironpdf. Ensuite, chargez votre PDF en utilisant PdfDocument.FromFile et extrayez le texte avec la méthode ExtractAllText.
Quels défis présentent les PDF scannés pour l'extraction de texte ?
Les PDF scannés stockent souvent le contenu sous forme d'images, et non de texte interrogeable, nécessitant des outils spécialisés comme l'OCR d'IronPDF pour extraire et convertir le texte en un format gérable.
Comment IronPDF facilite-t-il la manipulation de PDF en Python ?
IronPDF offre une suite d'outils pour la manipulation de PDF, y compris l'extraction de texte, la conversion HTML en PDF, la fusion et la division de documents, ainsi que le travail avec des formulaires PDF interactifs, améliorant ainsi les capacités de gestion de documents des applications Python.
Que faut-il pour configurer IronPDF dans un environnement Python ?
Pour configurer IronPDF en Python, assurez-vous que Python et PIP sont installés sur votre système. Ensuite, exécutez pip install ironpdf pour installer la bibliothèque, vous permettant ainsi de commencer à manipuler des PDF dans vos projets Python.
IronPDF peut-il convertir du contenu HTML en PDF en Python ?
Oui, IronPDF peut convertir du contenu HTML, y compris CSS et images, en documents PDF de haute qualité, ce qui en fait un outil polyvalent pour les développeurs nécessitant de générer des PDF à partir de contenu Web.
Y a-t-il un moyen d'essayer IronPDF avant d'acheter ?
IronPDF propose une licence d'essai, qui permet aux développeurs d'explorer sa gamme complète de fonctionnalités, y compris l'OCR et la manipulation de PDF, avant de décider d'un achat.
Pourquoi Python est-il un bon choix pour traiter des PDF scannés ?
Python est un langage de choix pour traiter des PDF scannés grâce à sa flexibilité et à la disponibilité de bibliothèques robustes comme IronPDF, qui simplifie les tâches telles que l'extraction de texte et la manipulation de PDF.
Quelles sont les caractéristiques clés d'IronPDF for Python ?
Les caractéristiques clés d'IronPDF for Python incluent l'OCR pour les PDF scannés, la conversion HTML en PDF, la fusion et la division de documents, la manipulation de texte et d'images, et la gestion de formulaires interactifs, offrant des solutions complètes de traitement PDF.