
PDFtoText em Python: Um tutorial passo a passo
Os arquivos PDF estão entre os formatos mais populares de documentos digitais. São preferidos pela sua compatibilidade com diferentes sistemas e pela sua capacidade de preservar a formatação de documentos complexos.
Na gestão de dados, converter documentos PDF em formatos editáveis ou extrair texto para análise é algo de valor inestimável. Esse processo de conversão permite que empresas e indivíduos extraiam e aproveitem dados que, de outra forma, estariam presos em documentos estáticos.
Python, com seu extenso ecossistema de bibliotecas, oferece uma maneira acessível e poderosa de manipular arquivos PDF. Seja para extrair dados, converter arquivos PDF ou automatizar a geração de relatórios, a simplicidade e as ferramentas abrangentes do Python o tornam uma linguagem ideal para tarefas de processamento de PDF.
O que é o IronPDF?
IronPDF é uma biblioteca completa de renderização de PDF para desenvolvedores Python, que facilita a interação com arquivos PDF. Ele fornece um conjunto robusto de ferramentas que permitem a criação, manipulação e conversão de documentos PDF dentro do ambiente de programação Python.
O IronPDF une a facilidade da programação em Python com os recursos de gerenciamento de documentos necessários para o processamento de PDFs, permitindo assim que os desenvolvedores incorporem funcionalidades de PDF diretamente em seus aplicativos.
Requisitos do sistema e guia de instalação
Antes de instalar o IronPDF, certifique-se de que seu sistema atende aos seguintes requisitos:
- Python 3.x instalado em seu sistema.
- Acesso ao pip (instalador de pacotes Python) para facilitar a instalação.
- É .NET Framework se você estiver usando um sistema Windows, pois o IronPDF depende do .NET para funcionar.
Após confirmar que seu sistema atende a esses requisitos, você pode instalar o IronPDF usando o pip. Abra a linha de comando ou o terminal e execute o seguinte comando:
pip install ironpdf
Certifique-se de estar usando a versão mais recente da biblioteca IronPDF for Python. Este comando fará o download e instalará a biblioteca IronPDF e todas as dependências necessárias em seu ambiente Python.
Converter PDF em Texto: Um Tutorial Passo a Passo
Passo 1: Importando o IronPDF
from ironpdf import *from ironpdf import *Este trecho de código começa com uma declaração de importação que traz todos os componentes necessários da biblioteca IronPDF para o seu script Python. É essencial para acessar as classes e os métodos fornecidos pelo IronPDF que permitem trabalhar com arquivos PDF.
Etapa 2: Configurando o registro de logs
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All-
Logger.EnableDebugging = True: Habilita o recurso de depuração na biblioteca IronPDF para rastrear operações, o que é crucial para a resolução de problemas.
-
Logger.LogFilePath = "Custom.log": Especifica o caminho e o nome do arquivo de log onde as informações de depuração serão gravadas. Certifique-se de que o diretório tenha permissão de escrita.
- Logger.LoggingMode = Logger.LoggingModes.All: Define o modo de registro para gravar todos os eventos, incluindo logs de nível informativo, avisos e erros. Este registro detalhado auxilia na depuração.
Etapa 3: Carregando o documento PDF
# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")-
PdfDocument.FromFile("content.pdf"): Carrega o arquivo PDF chamado "content.pdf" no ambiente criando um objeto PdfDocument .
- A variável pdf agora armazena seu documento PDF e permite que você execute diversas operações.
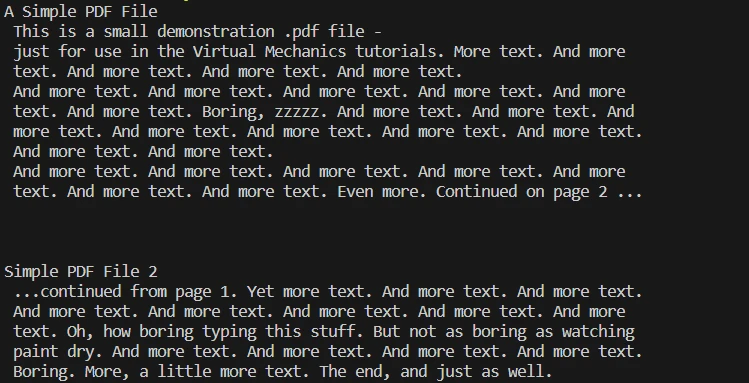
Etapa 4: Extraindo o texto de todo o documento
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)-
pdf.ExtractAllText(): Extrai todo o conteúdo textual do documento. O texto é então armazenado na variável all_text .
- print(all_text): Imprime o texto extraído no console, verificando o processo de extração de texto.
Etapa 5: Extraindo texto de uma página específica
# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)-
PdfDocument.FromFile("content.pdf"): Demonstra a necessidade de um objeto de arquivo PDF (o objeto PdfDocument ) para extrair o texto. Esta linha não é necessária se o documento já tiver sido carregado em um script contínuo.
-
pdf.ExtractTextFromPage(1): Extrai o texto da segunda página (índice 1) do PDF.
- O exemplo pressupõe que você imprimirá o texto extraído para verificar a operação: print(page_text) .
Este tutorial fornece um caminho claro para que os desenvolvedores convertam o conteúdo de arquivos PDF em texto, seja para processar o documento inteiro ou apenas páginas individuais, usando a biblioteca IronPDF em Python.
Trecho de código completo
Aqui está o código completo que você pode usar:
from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)Recursos avançados para arquivos PDF
Converter arquivos PDF para outros formatos
O IronPDF não se limita apenas à extração de texto. Uma de suas principais características é a capacidade de converter arquivos PDF em outros formatos, o que pode ser particularmente útil para compartilhar e apresentar informações em diferentes meios.
Imprimir e gerenciar documentos PDF
Gerenciar a impressão de arquivos PDF diretamente do Python é algo inestimável quando se trata de documentação física. O IronPDF oferece essa funcionalidade, simplificando o processo de digitalização para o físico com apenas alguns comandos.
Manipulação de arquivos PDF digitalizados
Para arquivos PDF digitalizados, o IronPDF oferece métodos especializados para extrair texto, o que pode ser uma tarefa desafiadora devido à natureza do conteúdo, que é uma imagem em vez de texto selecionável. Isso amplia a utilidade da biblioteca para tarefas mais abrangentes de gerenciamento de documentos.
A Evolução das Tecnologias de Processamento de PDF
As tecnologias de processamento de PDF evoluíram rapidamente, desde a simples extração de texto até o processamento complexo de dados e a manipulação mais interativa de documentos. O foco está se voltando para a automação, a inteligência artificial e os serviços baseados em nuvem, possibilitando soluções de processamento de documentos mais dinâmicas e inteligentes.
É provável que o IronPDF evolua em paralelo, incorporando essas tecnologias de ponta para se manter relevante e robusto.
Conclusão: Otimizando seu fluxo de trabalho com o IronPDF
O IronPDF simplifica a conversão de PDFs em texto e otimiza os fluxos de trabalho, tornando-se um recurso valioso para desenvolvedores e empresas.
O IronPDF se destaca por sua capacidade de se integrar perfeitamente em ambientes Python, sua robusta extração de texto de PDFs padrão e digitalizados, e sua alta fidelidade em manter o formato original do documento.
Os recursos de registro e depuração da biblioteca auxiliam ainda mais no desenvolvimento de aplicações confiáveis para manipulação de PDFs.
Após converter um PDF em texto, as etapas seguintes envolvem o aproveitamento dos dados extraídos. Isso pode significar integrar o texto em bancos de dados, realizar análises de dados, alimentá-lo em ferramentas de geração de relatórios ou utilizá-lo para aprendizado de máquina.
Com os dados textuais em um formato mais acessível, as possibilidades de processamento e utilização dessas informações se expandem significativamente, abrindo portas para novas descobertas e ganhos de eficiência operacional.
O IronPDF oferece um período de teste gratuito de 30 dias , permitindo que você explore e avalie todas as suas funcionalidades antes de se comprometer. Este período de teste é uma excelente oportunidade para os desenvolvedores experimentarem em primeira mão como o IronPDF pode otimizar seus fluxos de trabalho com PDFs.
Perguntas frequentes
Como posso extrair texto de um PDF em Python?
Você pode usar o IronPDF para extrair texto de um PDF em Python. Carregue o documento PDF usando PdfDocument.FromFile('filename.pdf') e extraia o texto usando pdf.ExtractAllText() .
Quais são as vantagens de usar o IronPDF para processamento de PDFs em Python?
O IronPDF oferece ferramentas robustas para extração de texto, manipulação e conversão de documentos, integrando-se perfeitamente a ambientes Python. Seus recursos avançados incluem o processamento de PDFs digitalizados e a conversão de PDFs para outros formatos.
Como instalo o IronPDF em Python?
Para instalar o IronPDF, certifique-se de ter o Python 3.x e o pip instalados. Execute o comando pip install ironpdf na linha de comando ou terminal.
O IronPDF consegue lidar com arquivos PDF digitalizados?
Sim, o IronPDF possui métodos especializados para extrair texto de arquivos PDF digitalizados, permitindo que você trabalhe com documentos cujo conteúdo está em formato de imagem.
Quais são os requisitos de sistema para usar o IronPDF em Python?
Para usar o IronPDF, você precisa do Python 3.x, do pip (instalador de pacotes Python) e, se estiver em um sistema Windows, do .NET Framework.
Como posso converter um PDF para outros formatos usando o IronPDF?
O IronPDF permite converter PDFs para vários formatos utilizando seus métodos de conversão, aumentando a flexibilidade do gerenciamento de documentos em aplicações Python.
Existe algum período de teste gratuito disponível para o IronPDF?
Sim, o IronPDF oferece um período de teste gratuito de 30 dias, permitindo que os desenvolvedores explorem e avaliem suas funcionalidades antes de efetuar a compra.
Por que o registro de logs é importante ao usar o IronPDF?
O registro de atividades no IronPDF é crucial, pois ajuda a rastrear operações, solucionar problemas e registrar todos os eventos, incluindo logs de nível informativo, avisos e erros, auxiliando na depuração.
Como o IronPDF aprimora a automação do fluxo de trabalho em Python?
O IronPDF aprimora a automação do fluxo de trabalho, simplificando a conversão de PDF para texto e permitindo a integração perfeita em projetos Python, aumentando assim a produtividade e a eficiência operacional.
















