
Python에서 PDFtoText를 사용하는 방법: 단계별 튜토리얼
PDF 파일은 가장 인기 있는 디지털 문서 형식 중 하나입니다. 이러한 파일 형식은 다양한 시스템과의 호환성이 뛰어나고 복잡한 문서의 서식을 유지하는 능력이 있어 선호됩니다.
데이터 관리에서 PDF 문서를 편집 가능한 형식으로 변환하거나 분석을 위해 텍스트를 추출하는 것은 매우 중요합니다. 이러한 변환 과정을 통해 기업과 개인은 정적인 문서에 갇혀 있던 데이터를 추출하고 활용할 수 있습니다.
Python은 방대한 라이브러리 생태계를 통해 PDF 파일을 조작하는 데 있어 접근하기 쉽고 강력한 방법을 제공합니다. 데이터 추출, PDF 파일 변환, 보고서 자동 생성 등 어떤 작업이든 Python의 간편함과 풍부한 도구 덕분에 PDF 처리 작업에 가장 적합한 언어로 자리매김했습니다.
IronPDF 란 무엇인가요?
IronPDF Python 개발자가 PDF 파일과 상호 작용하는 것을 용이하게 해주는 포괄적인 PDF 렌더링 라이브러리 입니다. 이 라이브러리는 Python 프로그래밍 환경 내에서 PDF 문서를 생성, 조작 및 변환할 수 있는 강력한 도구 세트를 제공합니다.
IronPDF Python 스크립팅의 편리함과 PDF 처리에 필요한 문서 관리 기능을 결합하여 개발자가 PDF 기능을 애플리케이션에 직접 통합할 수 있도록 지원합니다.
시스템 요구 사항 및 설치 가이드
IronPDF 설치하기 전에 시스템이 다음 요구 사항을 충족하는지 확인하십시오.
- 시스템에 Python 3.x가 설치되어 있어야 합니다.
- 간편한 설치를 위해 pip(Python Install-Package 프로그램)에 접근할 수 있습니다.
- Windows 시스템에서 실행하는 경우 IronPDF .NET Framework에 의존하므로 .NET Framework 필요합니다.
시스템이 이러한 요구 사항을 충족하는지 확인했으면 pip를 사용하여 IronPDF 설치할 수 있습니다. 명령 프롬프트 또는 터미널을 열고 다음 명령을 실행하십시오.
pip install ironpdf
Python용 IronPDF 라이브러리의 최신 버전을 사용하고 있는지 확인하십시오. 이 명령은 IronPDF 라이브러리와 필요한 모든 종속성을 Python 환경에 다운로드하고 설치합니다.
PDF를 텍스트로 변환하는 방법: 단계별 튜토리얼
1단계: IronPDF 가져오기
from ironpdf import *from ironpdf import *이 코드 조각은 IronPDF 라이브러리에서 필요한 모든 구성 요소를 Python 스크립트로 가져오는 import 문으로 시작합니다. PDF 파일을 다룰 수 있도록 IronPDF 에서 제공하는 클래스와 메서드에 접근하려면 이 권한이 필수적입니다.
2단계: 로깅 설정
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.AllLogger.EnableDebugging = True: IronPDF 라이브러리 내의 디버깅 기능을 활성화하여 작업 진행 상황을 추적할 수 있도록 합니다. 이는 문제 해결에 매우 중요합니다.
Logger.LogFilePath = "Custom.log": 디버깅 정보가 기록될 로그 파일의 경로와 이름을 지정합니다. 해당 디렉터리에 쓰기 권한이 있는지 확인하십시오.
- Logger.LoggingMode = Logger.LoggingModes.All: 정보 수준 로그, 경고 및 오류를 포함한 모든 이벤트를 기록하도록 로깅 모드를 설정합니다. 이처럼 포괄적인 로깅은 디버깅에 도움이 됩니다.
3단계: PDF 문서 불러오기
# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")PdfDocument.FromFile("content.pdf"): "content.pdf"라는 이름의 PDF 파일을 PdfDocument 객체를 생성하여 환경에 로드합니다.
- 이제 pdf 변수에 PDF 문서가 저장되며, 이를 통해 다양한 작업을 수행할 수 있습니다.
4단계: 문서 전체에서 텍스트 추출
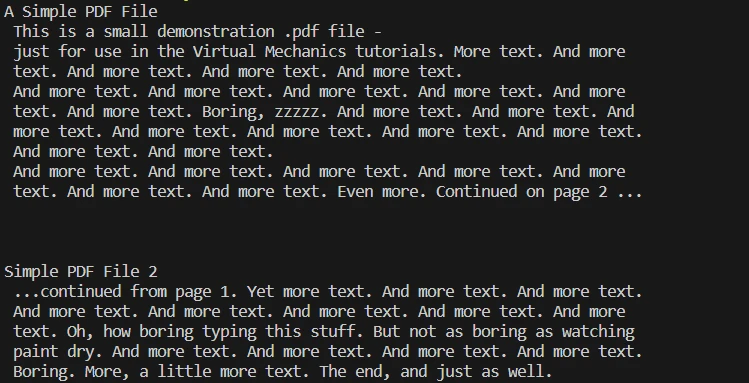
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)pdf.ExtractAllText(): 문서에서 모든 텍스트 콘텐츠를 추출합니다. 그러면 해당 텍스트가 all_text 변수에 저장됩니다.
- print(all_text): 추출된 텍스트를 콘솔에 출력하여 텍스트 추출 과정이 제대로 되었는지 확인합니다.
5단계: 특정 페이지에서 텍스트 추출
# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)PdfDocument.FromFile("content.pdf"): 텍스트를 추출하기 위해 PDF 파일 객체( PdfDocument 객체)가 필요함을 보여줍니다. 문서가 이미 연속 스크립트에 로드된 경우에는 이 줄이 필요하지 않습니다.
pdf.ExtractTextFromPage(1): PDF의 두 번째 페이지(인덱스 1)에서 텍스트를 추출합니다.
- 이 예제에서는 추출된 텍스트를 출력하여 작업이 제대로 수행되었는지 확인합니다: print(page_text) .
이 튜토리얼은 개발자가 Python의 IronPDF 라이브러리를 사용하여 PDF 파일의 내용을 텍스트로 변환하는 명확한 방법을 제시합니다. 문서 전체를 처리해야 하는 경우든, 개별 페이지만 처리해야 하는 경우든 모두 다룹니다.
전체 코드 조각
다음은 사용 가능한 전체 코드입니다.
from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)PDF 파일의 고급 기능
PDF 파일을 다른 형식으로 변환
IronPDF 텍스트 추출 기능만 제공하는 것이 아닙니다. 이 프로그램의 주요 기능 중 하나는 PDF 파일을 다른 형식으로 변환할 수 있다는 점인데, 이는 다양한 매체를 통해 정보를 공유하고 발표하는 데 특히 유용할 수 있습니다.
PDF 문서 인쇄 및 관리
Python에서 PDF 파일 인쇄 작업을 직접 관리하는 것은 물리적 문서 관리 측면에서 매우 유용합니다. IronPDF 이러한 기능을 제공하여 몇 가지 명령만으로 디지털에서 물리적 형태로의 변환 과정을 간소화합니다.
스캔한 PDF 파일 처리
스캔한 PDF 파일의 경우, IronPDF 텍스트를 추출하는 특수한 방법을 제공합니다. 콘텐츠가 선택 가능한 텍스트가 아닌 이미지이기 때문에 텍스트 추출은 어려운 작업일 수 있습니다. 이를 통해 라이브러리의 활용 범위가 더욱 광범위한 문서 관리 작업으로 확장됩니다.
PDF 처리 기술의 진화
PDF 처리 기술은 단순한 텍스트 추출에서 복잡한 데이터 처리 및 더욱 상호작용적인 문서 조작에 이르기까지 빠르게 발전해 왔습니다. 자동화, 인공지능, 클라우드 기반 서비스에 대한 관심이 높아지면서 더욱 역동적이고 지능적인 문서 처리 솔루션이 가능해지고 있습니다.
IronPDF 앞으로도 관련성과 안정성을 유지하기 위해 이러한 최첨단 기술을 통합하며 함께 발전해 나갈 가능성이 높습니다.
결론: IronPDF 로 워크플로우를 간소화하세요
IronPDF PDF를 텍스트로 변환하는 과정을 간소화하고 워크플로우를 효율화하여 개발자와 기업 모두에게 유용한 도구입니다.
IronPDF Python 환경에 원활하게 통합되는 기능, 일반 PDF와 스캔한 PDF 모두에서 강력한 텍스트 추출 기능, 그리고 원본 문서 형식을 높은 정확도로 유지하는 기능으로 두각을 나타냅니다.
라이브러리의 로깅 및 디버깅 기능은 PDF 조작을 위한 안정적인 애플리케이션 개발에 더욱 도움이 됩니다.
PDF 파일을 텍스트로 변환한 후에는 추출된 데이터를 활용하는 단계가 이어집니다. 이는 텍스트를 데이터베이스에 통합하거나, 데이터 분석을 수행하거나, 보고 도구에 입력하거나, 기계 학습에 활용하는 것을 의미할 수 있습니다.
텍스트 데이터를 보다 접근하기 쉬운 형식으로 제공함으로써, 이 정보를 처리하고 활용할 수 있는 가능성이 크게 확장되어 새로운 통찰력과 운영 효율성을 확보할 수 있게 됩니다.
IronPDF 30일 무료 체험판을 제공하므로 구매 전에 모든 기능을 살펴보고 평가해 볼 수 있습니다. 이번 시범 사용 기간은 개발자들이 IronPDF PDF 워크플로우를 어떻게 간소화할 수 있는지 직접 경험해 볼 수 있는 좋은 기회입니다.
자주 묻는 질문
Python을 사용하여 PDF에서 텍스트를 추출하는 방법은 무엇인가요?
Python에서 IronPDF를 사용하여 PDF에서 텍스트를 추출할 수 있습니다. PdfDocument.FromFile('filename.pdf') 를 사용하여 PDF 문서를 불러오고 pdf.ExtractAllText() 사용하여 텍스트를 추출합니다.
Python에서 PDF 처리를 위해 IronPDF를 사용하는 장점은 무엇인가요?
IronPDF는 텍스트 추출, 문서 조작 및 변환을 위한 강력한 도구를 제공하며, Python 환경에 원활하게 통합됩니다. 고급 기능으로는 스캔한 PDF 파일을 처리하고 PDF를 다른 형식으로 변환하는 기능이 있습니다.
Python에 IronPDF를 설치하는 방법은 무엇인가요?
IronPDF를 설치하려면 Python 3.x와 pip가 설치되어 있는지 확인하십시오. 명령 프롬프트 또는 터미널에서 pip install ironpdf 명령을 실행하세요.
IronPDF는 스캔한 PDF 파일을 처리할 수 있나요?
네, IronPDF는 스캔한 PDF 파일에서 텍스트를 추출하는 특수한 방법을 제공하여 이미지 형태의 콘텐츠가 포함된 문서도 작업할 수 있도록 합니다.
Python에서 IronPDF를 사용하기 위한 시스템 요구 사항은 무엇입니까?
IronPDF를 사용하려면 Python 3.x, pip(Python Install-Package 프로그램)이 필요하며, Windows 시스템을 사용하는 경우 .NET Framework도 필요합니다.
IronPDF를 사용하여 PDF 파일을 다른 형식으로 변환하려면 어떻게 해야 하나요?
IronPDF는 자체 변환 메서드를 활용하여 PDF를 다양한 형식으로 변환할 수 있도록 해주므로 Python 애플리케이션에서 문서 관리의 유연성을 향상시켜 줍니다.
IronPDF 무료 체험판이 있나요?
네, IronPDF는 30일 무료 체험판을 제공하므로 개발자는 구매 전에 기능을 살펴보고 평가할 수 있습니다.
IronPDF를 사용할 때 로깅이 중요한 이유는 무엇입니까?
IronPDF에서 로깅은 운영 추적, 문제 해결, 정보 수준 로그, 경고 및 오류를 포함한 모든 이벤트 기록에 도움이 되므로 디버깅에 매우 중요합니다.
IronPDF는 Python 워크플로 자동화를 어떻게 향상시키나요?
IronPDF는 PDF를 텍스트로 변환하는 과정을 간소화하고 Python 프로젝트에 원활하게 통합할 수 있도록 지원하여 워크플로 자동화를 향상시키고 생산성과 운영 효율성을 높입니다.
















