
PDFtoText w Pythonie: samouczek krok po kroku
Pliki PDF są jednym z najpopularniejszych formatów dokumentów cyfrowych. Są one preferowane ze względu na kompatybilność z różnymi systemami oraz zdolność do zachowania formatowania złożonych dokumentów.
W zarządzaniu danymi nieoceniona jest konwersja dokumentów PDF do formatów edytowalnych lub wyodrębnianie tekstu do analizy. Ten proces konwersji umożliwia firmom i osobom prywatnym wydobywanie i wykorzystywanie danych, które w innym przypadku byłyby zamknięte w statycznych dokumentach.
Python, dzięki rozbudowanemu ekosystemowi bibliotek, oferuje przystępny i potężny sposób na manipulowanie plikami PDF. Niezależnie od tego, czy chodzi o wyodrębnianie danych, konwersję plików PDF czy automatyzację generowania raportów, prostota języka Python i bogaty zestaw narzędzi sprawiają, że jest to język pierwszego wyboru do zadań związanych z przetwarzaniem plików PDF.
Czym jest IronPDF?
IronPDF to kompleksowa biblioteka do renderowania plików PDF przeznaczona dla programistów języka Python, ułatwiająca pracę z plikami PDF. Zapewnia solidny zestaw narzędzi, które umożliwiają tworzenie, edycję i konwersję dokumentów PDF w środowisku programistycznym Python.
IronPDF łączy w sobie łatwość pisania skryptów w języku Python z możliwościami zarządzania dokumentami wymaganymi do przetwarzania plików PDF, umożliwiając tym samym programistom wbudowanie funkcji PDF bezpośrednio w ich aplikacje.
Wymagania systemowe i instrukcja instalacji
Przed zainstalowaniem IronPDF upewnij się, że Twój system spełnia następujące wymagania:
- Python 3.x zainstalowany w systemie.
- Dostęp do pip (instalatora pakietów Python) w celu łatwej instalacji.
- .NET Framework, jeśli korzystasz z systemu Windows, ponieważ IronPDF do działania wymaga środowiska .NET Framework.
Po upewnieniu się, że system spełnia te wymagania, można zainstalować IronPDF za pomocą pip. Otwórz wiersz poleceń lub terminal i uruchom następujące polecenie:
pip install ironpdf
Upewnij się, że korzystasz z najnowszej wersji biblioteki IronPDF for Python. To polecenie spowoduje pobranie i zainstalowanie biblioteki IronPDF oraz wszystkich wymaganych zależności w Twoim środowisku Python.
Konwersja pliku PDF na tekst: samouczek krok po kroku
Krok 1: Importowanie IronPDF
from ironpdf import *from ironpdf import *Ten fragment kodu zaczyna się od instrukcji importu, która wprowadza wszystkie niezbędne komponenty z biblioteki IronPDF do skryptu w języku Python. Jest to niezbędne do uzyskania dostępu do klas i metod udostępnianych przez IronPDF, które umożliwiają pracę z plikami PDF.
Krok 2: Konfiguracja rejestrowania
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.AllLogger.EnableDebugging = True: Włącza funkcję debugowania w bibliotece IronPDF w celu śledzenia operacji, co ma kluczowe znaczenie dla rozwiązywania problemów.
Logger.LogFilePath = "Custom.log": Określa ścieżkę i nazwę pliku dziennika, do którego będą zapisywane informacje dotyczące debugowania. Upewnij się, że katalog ma uprawnienia do zapisu.
- Logger.LoggingMode = Logger.LoggingModes.All: Ustawia tryb logowania tak, aby rejestrował wszystkie zdarzenia, w tym logi na poziomie informacyjnym, ostrzeżenia i błędy. To kompleksowe logowanie pomaga w debugowaniu.
Krok 3: Ładowanie dokumentu PDF
# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")PdfDocument.FromFile("content.pdf"): Ładuje plik PDF o nazwie "content.pdf" do środowiska poprzez utworzenie obiektu PdfDocument.
- Zmienna pdf zawiera teraz dokument PDF i umożliwia wykonywanie różnych operacji.
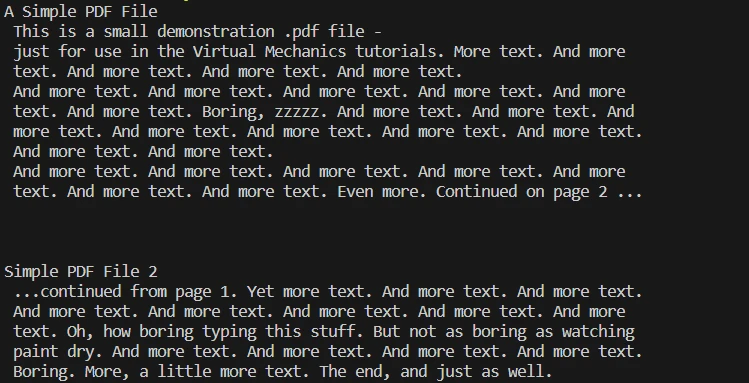
Krok 4: Wyodrębnianie tekstu z całego dokumentu
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)PDF.ExtractAllText(): Wyodrębnia całą treść tekstową z dokumentu. Tekst jest następnie zapisywany w zmiennej all_text.
- print(all_text): Wyświetla wyodrębniony tekst w konsoli, weryfikując proces wyodrębniania tekstu.
Krok 5: Pobieranie tekstu z określonej strony
# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)PdfDocument.FromFile("content.pdf"): Pokazuje, że do wyodrębnienia tekstu potrzebny jest obiekt pliku PDF (obiekt PdfDocument). Ta linia nie jest konieczna, jeśli dokument został już załadowany w skrypcie ciągłym.
pdf.ExtractTextFromPage(1): Wyodrębnia tekst z drugiej strony (indeks 1) pliku PDF.
- Przykład zakłada, że wyodrębniony tekst zostanie wydrukowany w celu weryfikacji działania: PRINT(page_text).
Ten samouczek przedstawia programistom jasną ścieżkę konwersji zawartości plików PDF na tekst, niezależnie od tego, czy trzeba przetworzyć cały dokument, czy tylko poszczególne strony, przy użyciu biblioteki IronPDF w języku Python.
Pełny fragment kodu
Oto pełny kod, z którego możesz skorzystać:
from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)Zaawansowane funkcje dla plików PDF
Konwersja plików PDF do innych formatów
IronPDF nie zajmuje się wyłącznie wyodrębnianiem tekstu. Jedną z jego kluczowych funkcji jest możliwość konwersji plików PDF do innych formatów, co może być szczególnie przydatne przy udostępnianiu i prezentowaniu informacji w różnych mediach.
Drukowanie i zarządzanie dokumentami PDF
Zarządzanie zadaniem drukowania pliku PDF bezpośrednio z poziomu języka Python ma nieocenione znaczenie w przypadku dokumentacji fizycznej. IronPDF zapewnia tę funkcjonalność, usprawniając proces przejścia od formatu cyfrowego do fizycznego za pomocą zaledwie kilku poleceń.
Obsługa zeskanowanych plików PDF
W przypadku zeskanowanych plików PDF IronPDF oferuje specjalistyczne metody wyodrębniania tekstu, co może stanowić trudne zadanie ze względu na charakter treści, która jest obrazem, a nie tekstem, który można zaznaczyć. Rozszerza to zakres zastosowania biblioteki na szersze zadania związane z zarządzaniem dokumentami.
Ewolucja technologii przetwarzania plików PDF
Technologie przetwarzania plików PDF szybko ewoluowały, od prostego wyodrębniania tekstu po złożoną obsługę danych i bardziej interaktywną manipulację dokumentami. Nacisk przenosi się w kierunku automatyzacji, sztucznej inteligencji i usług w chmurze, umożliwiających bardziej dynamiczne i inteligentne rozwiązania w zakresie przetwarzania dokumentów.
IronPDF będzie prawdopodobnie ewoluować równolegle, wdrażając te najnowocześniejsze technologie, aby pozostać aktualnym i niezawodnym.
Wniosek: Usprawnij swój przepływ pracy dzięki IronPDF
IronPDF upraszcza konwersję plików PDF na tekst i usprawnia przepływ pracy, co czyni go cennym narzędziem dla programistów i firm.
IronPDF wyróżnia się możliwością płynnej integracji ze środowiskami Python, solidnym wyodrębnianiem tekstu zarówno ze standardowych, jak i zeskanowanych plików PDF oraz wysoką wiernością w zachowaniu formatu oryginalnego dokumentu.
Funkcje rejestrowania i debugowania biblioteki dodatkowo pomagają w tworzeniu niezawodnych aplikacji do obróbki plików PDF.
Po konwersji pliku PDF na tekst, kolejne kroki obejmują wykorzystanie wyodrębnionych danych. Może to oznaczać integrację tekstu z bazami danych, przeprowadzanie analizy danych, wprowadzanie ich do narzędzi do raportowania lub wykorzystywanie ich do uczenia maszynowego.
Dzięki udostępnieniu danych tekstowych w bardziej przystępnym formacie znacznie rozszerzają się możliwości przetwarzania i wykorzystania tych informacji, otwierając drzwi do nowych spostrzeżeń i zwiększenia wydajności operacyjnej.
IronPDF oferuje 30-dniowy bezpłatny okres probny, który pozwala zapoznać się z pełną funkcjonalnością oprogramowania i ocenić je przed podjęciem decyzji o zakupie. Ten okres próbny to doskonała okazja dla programistów, aby na własnej skórze przekonać się, jak IronPDF może usprawnić ich procesy pracy z plikami PDF.
Często Zadawane Pytania
Jak wyodrębnić tekst z pliku PDF w języku Python?
Możesz użyć IronPDF do wyodrębnienia tekstu z pliku PDF w języku Python. Załaduj dokument PDF za pomocą PdfDocument.FromFile('filename.pdf') i wyodrębnij tekst za pomocą pdf.ExtractAllText().
Jakie są zalety korzystania z IronPDF do przetwarzania plików PDF w języku Python?
IronPDF oferuje solidne narzędzia do wyodrębniania tekstu, edycji dokumentów i konwersji, które płynnie integrują się ze środowiskami Python. Jego zaawansowane funkcje obejmują obsługę zeskanowanych plików PDF oraz konwersję plików PDF do innych formatów.
Jak zainstalować IronPDF w Pythonie?
Aby zainstalować IronPDF, upewnij się, że masz zainstalowane Python 3.x i pip. Uruchom polecenie pip install ironpdf w wierszu poleceń lub terminalu.
Czy IronPDF obsługuje zeskanowane pliki PDF?
Tak, IronPDF posiada specjalistyczne metody wyodrębniania tekstu ze skanowanych plików PDF, co pozwala na pracę z dokumentami, których zawartość ma formę obrazu.
Jakie są wymagania systemowe dotyczące korzystania z IronPDF w języku Python?
Aby korzystać z IronPDF, potrzebujesz Pythona 3.x, pip (instalatora pakietów Pythona) oraz, jeśli korzystasz z systemu Windows, .NET Framework.
Jak mogę przekonwertować plik PDF na inne formaty za pomocą IronPDF?
IronPDF umożliwia konwersję plików PDF do różnych formatów przy użyciu swoich metod konwersji, zwiększając elastyczność zarządzania dokumentami w aplikacjach napisanych w języku Python.
Czy dostępna jest bezpłatna wersja próbna IronPDF?
Tak, IronPDF oferuje 30-dniowy bezpłatny okres probny, umożliwiający programistom zapoznanie się z jego funkcjonalnościami i ich ocenę przed dokonaniem zakupu.
Dlaczego rejestrowanie jest ważne podczas korzystania z IronPDF?
Rejestrowanie w IronPDF ma kluczowe znaczenie, ponieważ pomaga śledzić operacje, rozwiązywać problemy i rejestrować wszystkie zdarzenia, w tym logi na poziomie informacyjnym, ostrzeżenia i błędy, co ułatwia debugowanie.
W jaki sposób IronPDF usprawnia automatyzację przepływu pracy w języku Python?
IronPDF usprawnia automatyzację przepływu pracy poprzez uproszczenie konwersji plików PDF na tekst oraz umożliwienie płynnej integracji z projektami w języku Python, zwiększając w ten sposób produktywność i wydajność operacyjną.
















