
Jak wyodrębnić tekst z PDF linia po linii
W niniejszym przewodniku przedstawiono niuanse korzystania z IronPDF do sekwencyjnego wyodrębniania tekstu z dokumentów PDF w języku Python. Obejmie on wszystko, od konfiguracji środowiska Python po uruchomienie pierwszego programu w języku Python służącego do wyodrębniania tekstu z plików PDF.
Jak wyodrębnić tekst z pliku PDF wiersz po wierszu
- Pobierz i zainstaluj bibliotekę PDF przy użyciu języka Python, aby wyodrębnić tekst z pliku PDF.
- Utwórz projekt w języku Python w preferowanym środowisku IDE.
- Załaduj wybrany plik PDF w celu pobrania treści tekstowej.
- Przejrzyj plik PDF i wyodrębnij tekst sekwencyjnie, korzystając z wbudowanej funkcji biblioteki.
- Zapisz wyodrębniony tekst do pliku.
Biblioteka IronPDF PDF dla języka Python
IronPDF to przydatne narzędzie, które pozwala pracować z plikami PDF w języku Python. Pomyśl o tym jak o pomocnym asystencie, który ułatwia czytanie, tworzenie i edycję plików PDF. Niezależnie od tego, czy chcesz wyodrębnić treść z dokumentu PDF, dodać nowe informacje, czy przekształcić stronę internetową do formatu PDF, IronPDF oferuje kompleksowe rozwiązania. Jest to płatny pakiet oprogramowania, ale oferowana jest wersja próbna, którą można wypróbować przed podjęciem decyzji o zakupie.
Zanim zagłębimy się w skrypt, konieczne jest skonfigurowanie środowiska Python. Ten przewodnik krok po kroku pomoże Ci skonfigurować środowisko, utworzyć nowy projekt w języku Python w Visual Studio Code oraz skonfigurować środowisko biblioteki IronPDF.
Pobierz i zainstaluj Python: Jeśli nie masz jeszcze zainstalowanego Pythona, pobierz najnowszą wersję z oficjalnej strony Pythona. Postępuj zgodnie z instrukcjami instalacji dla danego systemu operacyjnego.
Sprawdź instalację Pythona: Otwórz terminal lub wiersz poleceń i wpisz python --version. To polecenie powinno wyświetlić zainstalowaną wersję Pythona, potwierdzając, że instalacja przebiegła pomyślnie.
Aktualizacja pip: Pip to instalator pakietów w języku Python. Upewnij się, że jest aktualny, uruchamiając pip install --upgrade pip.
Tworzenie nowego projektu Python w Visual Studio Code
Pobierz Visual Studio Code: Jeśli jeszcze go nie masz, pobierz go z oficjalnej strony internetowej.
Zainstaluj rozszerzenie Python: Otwórz Visual Studio Code i przejdź do Extensions Marketplace. Wyszukaj rozszerzenie Python firmy Microsoft i zainstaluj je.
Utwórz nowy folder: Utwórz nowy folder, w którym chcesz umieścić swój projekt w języku Python. Nadaj mu odpowiednią nazwę, np. PDF_Text_Extractor.
Otwórz folder w VS Code: Przeciągnij folder do Visual Studio Code lub użyj opcji menu Plik > Otwórz folder, aby otworzyć folder.
Utwórz plik Python: Kliknij prawym przyciskiem myszy w panelu VS Code Explorer i wybierz opcję New File. Nazwij plik main.py lub podobnie. Ten plik będzie zawierał Twój program w języku Python.
 Utwórz nowy plik Python w Visual Studio Code
Utwórz nowy plik Python w Visual Studio Code
Wymagania i konfiguracja biblioteki IronPDF
IronPDF jest niezbędny do pobierania treści tekstowych z plików PDF. Oto jak to zainstalować:
Otwieranie terminala w VS Code: Terminal w VS Code można otworzyć, wybierając opcję Terminal > New Terminal.
Zainstaluj IronPDF: W terminalu wykonaj następujące polecenie, aby zainstalować najnowszą wersję IronPDF:
pip install ironpdf
Ten proces pobiera i instaluje bibliotekę IronPDF wraz z wszelkimi wymaganymi modułami.
 Zainstaluj pakiet IronPDF
Zainstaluj pakiet IronPDF
I to wszystko! Pomyślnie skonfigurowałeś środowisko Python, utworzyłeś nowy projekt w Visual Studio Code i zainstalowałeś bibliotekę IronPDF.
Wyodrębnianie tekstu z pliku PDF wiersz po wierszu
Stosowanie klucza licencyjnego
Przed rozpoczęciem pracy upewnij się, że zastosowałeś swój klucz licencyjny IronPDF.
from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Zastąp YOUR-LICENSE-KEY-HERE swoim rzeczywistym kluczem licencyjnym IronPDF. Ta licencja pozwala odblokować wszystkie funkcje biblioteki dla Twojego projektu.
Ładowanie pliku w formacie PDF
Musisz załadować istniejący plik PDF do swojego programu w języku Python. Można to osiągnąć za pomocą metody PdfDocument.FromFile z IronPDF.
pdfFileObj = PdfDocument.FromFile("content.pdf")pdfFileObj = PdfDocument.FromFile("content.pdf")"content.pdf" odnosi się do pliku PDF, który chcesz przeczytać. Ten załadowany plik PDF jest przechowywany w zmiennej pdfFileObj, używanej jako czytnik PDF lub obiekt pliku PDF pdfFileObj.
Wyodrębnianie tekstu z całego dokumentu PDF
Jeśli chcesz pobrać wszystkie dane tekstowe z pliku PDF jednocześnie, możesz użyć metody ExtractAllText.
all_text = pdfFileObj.ExtractAllText()all_text = pdfFileObj.ExtractAllText()Metoda ExtractAllText została tutaj wykorzystana w celach demonstracyjnych. Ta metoda wyodrębnia cały tekst z pliku PDF i zapisuje go w zmiennej o nazwie all_text.
Pobieranie tekstu z określonej strony pliku PDF
IronPDF umożliwia wyodrębnianie tekstu z określonej strony przy użyciu metody ExtractTextFromPage. Ta metoda jest przydatna, gdy potrzebujesz tylko tekstu z niektórych stron.
page_2_text = pdfFileObj.ExtractTextFromPage(1)page_2_text = pdfFileObj.ExtractTextFromPage(1)W tym przypadku wyodrębniamy tekst z drugiej strony, odpowiadającej indeksowi 1.
Inicjalizacja pliku tekstowego do zapisywania wyodrębnionego tekstu
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:with open("extracted_text.txt", "w", encoding='utf-8') as text_file:Otwórz plik o nazwie "extracted_text.txt", aby zapisać dane tekstowe. W tym celu używana jest wbudowana funkcja Pythona open, ustawiająca tryb pliku na "zapis" ("w"), z encoding='utf-8' do obsługi znaków Unicode.
Przejrzyj każdą stronę w celu wyodrębnienia tekstu linia po linii
for i in range(0, pdfFileObj.get_Pages().Count):for i in range(0, pdfFileObj.get_Pages().Count):Powyższy kod przechodzi cyklicznie przez każdą stronę pliku PDF, wykorzystując funkcję get_Pages().Count biblioteki IronPDF w celu uzyskania całkowitej liczby stron.
Wyodrębnij tekst i podziel go na wiersze
page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')Dla każdej strony używana jest metoda ExtractTextFromPage w celu pobrania całego tekstu, a następnie metoda split w języku Python w celu podzielenia go na wiersze. Wynikiem tego jest lista wierszy, które można przetwarzać w pętli.
Zapisz wyodrębnione wiersze do pliku tekstowego
for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')W tym przypadku kod iteruje przez każdą linię na liście, PRINTując ją w konsoli i zapisując w pliku poprzez dodanie znaku nowej linii (\n) po każdej linii w celu prawidłowego sformatowania tekstu.
Pełny kod
Oto pełna implementacja:
from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')Wynik
Uruchom plik Python, wpisując następujące polecenie w terminalu Visual Studio Code:
python main.pypython main.pyWynik ten zostanie wyświetlony w terminalu:
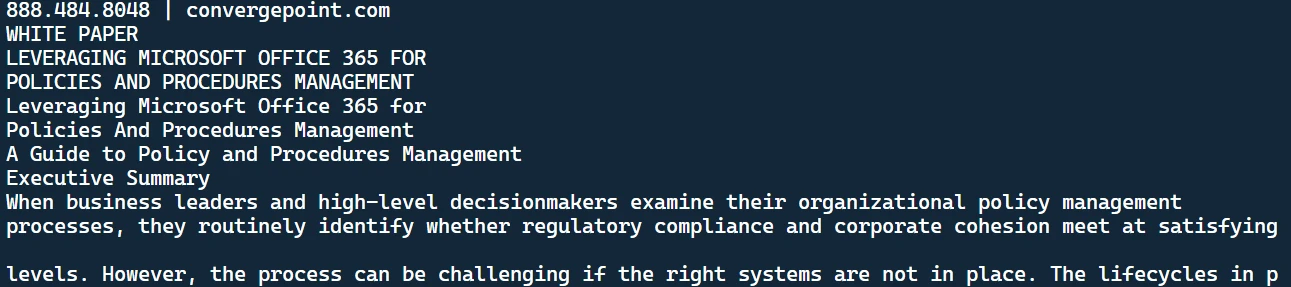 Wyodrębniony tekst
Wyodrębniony tekst
Jest to tekst pobrany z pliku PDF. Zauważysz również dokument tekstowy utworzony w Twoim katalogu.
 Wyodrębniony tekst zapisany w pliku TXT
Wyodrębniony tekst zapisany w pliku TXT
W tym pliku tekstowym znajdziesz pobrany tekst w formacie tekstowym, przedstawiony w kolejności.
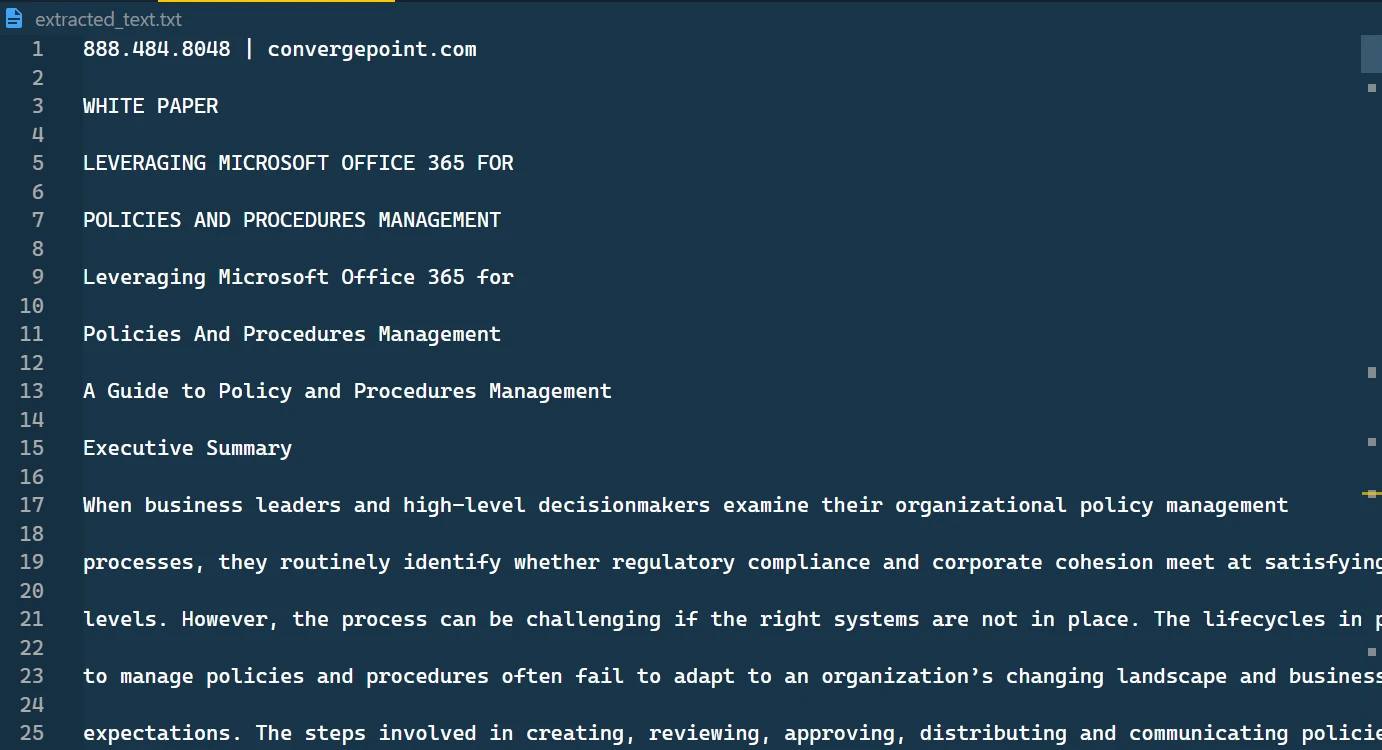 Treść wyodrębnionego pliku tekstowego
Treść wyodrębnionego pliku tekstowego
Wnioski
Podsumowując, wykorzystanie IronPDF i języka Python do wyodrębniania tekstu z plików PDF jest solidnym i prostym podejściem, niezależnie od tego, czy chodzi o pobieranie tekstu z całego dokumentu, konkretnych stron, czy nawet linia po linii. Dodatkową korzyścią wynikającą z zapisywania wyodrębnionego tekstu w pliku tekstowym jest możliwość efektywnego zarządzania danymi i wykorzystywania ich do dalszego przetwarzania. IronPDF okazuje się nieocenionym narzędziem do obsługi plików PDF, oferującym szereg funkcji wykraczających poza zwykłe wyodrębnianie tekstu. Możesz również konwertować pliki PDF na tekst w języku Python przy użyciu IronPDF.
Ponadto tworzenie interaktywnych plików PDF, wypełnianie i przesyłanie interaktywnych formularzy, łączenie i dzielenie plików PDF, wyodrębnianie tekstu i obrazów, wyszukiwanie tekstu w plikach PDF, rasteryzacja plików PDF do obrazów, zmiana rozmiaru czcionki, koloru obramowania i tła oraz konwersja plików PDF to zadania, w których może pomóc zestaw narzędzi IronPDF.
IronPDF nie jest biblioteką Python typu open source. Jeśli rozważasz wykorzystanie IronPDF w swoich projektach, cena licencji na ten pakiet zaczyna się od $799. Jeśli jednak potrzebujesz wyjaśnień dotyczących inwestycji, IronPDF oferuje bezpłatną wersję próbną, która pozwala dokładnie zapoznać się z jego funkcjami.
Często Zadawane Pytania
Jak wyodrębnić tekst z pliku PDF za pomocą języka Python?
Możesz użyć IronPDF do wyodrębniania tekstu z plików PDF w języku Python. Wymaga to załadowania pliku PDF za pomocą metody PdfDocument.FromFile i iteracji przez strony w celu wyodrębnienia tekstu linia po linii.
Co jest potrzebne, aby rozpocząć wyodrębnianie tekstu z plików PDF w języku Python?
Aby wyodrębnić tekst z plików PDF w języku Python, należy zainstalować środowisko Python wraz z biblioteką IronPDF, którą można zainstalować za pomocą pip. Do pisania i wykonywania skryptów zalecane jest środowisko IDE, takie jak Visual Studio Code.
Czy IronPDF może wyodrębnić tekst z określonej strony w pliku PDF?
Tak, IronPDF umożliwia wyodrębnianie tekstu z określonej strony pliku PDF za pomocą metody ExtractTextFromPage poprzez podanie indeksu strony.
Jak mogę zapisać wyodrębniony tekst do pliku w języku Python?
Po wyodrębnieniu tekstu za pomocą IronPDF można go zapisać w pliku, zapisując wyodrębnione linie tekstu do pliku tekstowego przy użyciu metod obsługi plików w języku Python.
Jakie dodatkowe funkcje oferuje IronPDF oprócz wyodrębniania tekstu?
IronPDF oferuje szeroki zakres funkcji, w tym tworzenie, edycję i konwersję plików PDF, łączenie i dzielenie dokumentów PDF, wyodrębnianie obrazów oraz konwersję plików PDF do innych formatów.
Jak uzyskać licencję na IronPDF w moim projekcie w języku Python?
Aby uzyskać licencję na IronPDF, należy ustawić klucz licencyjny w skrypcie Python za pomocą właściwości License.LicenseKey, co odblokowuje pełną funkcjonalność biblioteki.
Czy przed zakupem można wypróbować IronPDF?
Tak, IronPDF oferuje wersję próbną, która pozwala ocenić jego funkcje przed podjęciem decyzji o zakupie pełnej licencji.
Co należy zrobić, jeśli napotkam problemy podczas wyodrębniania tekstu z pliku PDF?
Upewnij się, że IronPDF jest poprawnie zainstalowany i licencjonowany, a Twoje środowisko Python jest prawidłowo skonfigurowane. Zapoznaj się z dokumentacją lub zasobami pomocy technicznej, aby rozwiązać typowe problemy.
Czy mogę przekonwertować plik PDF na obraz za pomocą IronPDF?
Tak, IronPDF oferuje funkcję rasteryzacji plików PDF na obrazy, umożliwiającą konwersję całych dokumentów lub określonych stron na pliki graficzne.
Jak uruchomić skrypt w języku Python do wyodrębniania tekstu z plików PDF?
Po napisaniu skryptu można go uruchomić, wpisując w terminalu środowiska IDE polecenie python main.py, gdzie main.py to nazwa pliku skryptu.
















