
Como extrair texto de um PDF linha por linha
Este guia mostrará as nuances do uso do IronPDF para extrair texto sequencialmente de documentos PDF em Python. Este curso abordará tudo, desde a configuração do seu ambiente Python até a execução do seu primeiro programa Python para extração de texto de PDFs.
Como extrair texto de um PDF linha por linha
- Baixe e instale a biblioteca PDF usando Python para extrair o texto das linhas do arquivo PDF.
- Crie um projeto Python em sua IDE preferida.
- Carregue o arquivo PDF desejado para recuperar o conteúdo textual.
- Percorra o PDF e extraia o texto sequencialmente usando a função integrada da biblioteca.
- Salve o texto extraído em um arquivo.
IronPDF - Biblioteca Python para PDF
IronPDF é uma ferramenta prática que permite trabalhar com arquivos PDF em Python. Considere-o como um assistente útil que torna a leitura, a criação e a edição de arquivos PDF mais acessíveis. Seja para extrair conteúdo de um documento PDF, incluir novas informações ou converter uma página da web para o formato PDF, o IronPDF oferece soluções completas. É um software pago, mas eles oferecem uma versão de avaliação para você experimentar antes de se comprometer com a compra.
Antes de começar a usar o script, é essencial configurar seu ambiente Python. Este guia passo a passo ajudará você a configurar seu ambiente, criar um novo projeto Python no Visual Studio Code e configurar o ambiente da biblioteca IronPDF .
Baixe e instale o Python: Se você ainda não instalou o Python, baixe a versão mais recente no site oficial do Python . Siga as instruções de instalação específicas para o seu sistema operacional.
Verifique a instalação do Python: Abra seu terminal ou prompt de comando e digite python --version . Este comando deve imprimir a versão do Python instalada, confirmando que a instalação foi bem-sucedida.
Atualizar pip: Pip é o instalador de pacotes do Python. Certifique-se de que está atualizado executando pip install --upgrade pip .
Criando um novo projeto Python no Visual Studio Code
Baixe o Visual Studio Code: Se você não o tiver, baixe-o do site oficial .
Instale a extensão Python: Abra o Visual Studio Code e acesse o Marketplace de Extensões. Procure pela extensão Python da Microsoft e instale-a.
Criar uma nova pasta: Crie uma nova pasta onde você deseja armazenar seu projeto Python. Dê um nome relevante, como PDF_Text_Extractor .
Abra a pasta no VS Code: Arraste a pasta para o Visual Studio Code ou use a opção de menu Arquivo > Abrir pasta para abrir a pasta.
Criar um arquivo Python: Clique com o botão direito do mouse no painel Explorador do VS Code e escolha Novo Arquivo . Dê ao arquivo o nome de main.py ou algo semelhante. Este arquivo conterá seu programa em Python.
 Crie um novo arquivo Python no Visual Studio Code.
Crie um novo arquivo Python no Visual Studio Code.
Requisitos e configuração da biblioteca IronPDF
O IronPDF é essencial para recuperar conteúdo textual de PDFs. Veja como instalá-lo:
Abrir Terminal no VS Code: Você pode abrir um terminal dentro do VS Code acessando Terminal > Novo Terminal .
Instale o IronPDF: No terminal, execute o seguinte comando para instalar a versão mais recente do IronPDF:
pip install ironpdf
Este processo baixa e instala a biblioteca IronPDF juntamente com quaisquer módulos necessários.
 Instale o pacote IronPDF
Instale o pacote IronPDF
E pronto! Você configurou com sucesso seu ambiente Python, criou um novo projeto no Visual Studio Code e instalou a biblioteca IronPDF .
Extrair texto de um PDF linha por linha
Aplicando a chave de licença
Antes de prosseguir, certifique-se de inserir sua chave de licença do IronPDF .
from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"Substitua YOUR-LICENSE-KEY-HERE pela sua chave de licença IronPDF real. Esta licença permite desbloquear todas as funcionalidades da biblioteca para o seu projeto.
Carregando o formato de arquivo PDF
Você precisa carregar um arquivo PDF existente em seu programa Python. Você pode alcançar isso com o método PdfDocument.FromFile do IronPDF.
pdfFileObj = PdfDocument.FromFile("content.pdf")pdfFileObj = PdfDocument.FromFile("content.pdf")"content.pdf" refere-se ao arquivo PDF que você deseja ler. Este arquivo PDF carregado é armazenado na variável pdfFileObj, usado como um leitor de PDF ou o objeto de arquivo PDF pdfFileObj.
Extraindo texto de um documento PDF inteiro
Se você quiser capturar todos os dados de texto do arquivo PDF de uma vez, pode usar o método ExtractAllText.
all_text = pdfFileObj.ExtractAllText()all_text = pdfFileObj.ExtractAllText()O método ExtractAllText é usado aqui para fins de demonstração. Este método extrai todo o texto do arquivo PDF e o armazena em uma variável chamada all_text.
Extraindo texto de uma página específica de um PDF
O IronPDF permite extração de texto de uma página específica usando o método ExtractTextFromPage. Esse método é útil quando você precisa apenas do texto de algumas páginas.
page_2_text = pdfFileObj.ExtractTextFromPage(1)page_2_text = pdfFileObj.ExtractTextFromPage(1)Aqui, estamos extraindo o texto da segunda página, correspondente ao índice 1.
Inicializando um arquivo de texto para gravar o texto extraído.
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:with open("extracted_text.txt", "w", encoding='utf-8') as text_file:Abra um arquivo chamado "extracted_text.txt" para salvar os dados de texto. A função open embutida do Python é usada para isso, definindo o modo do arquivo para 'escrita' ('w'), com encoding='utf-8' para lidar com caracteres Unicode.
Percorra cada página para extrair o texto linha por linha.
for i in range(0, pdfFileObj.get_Pages().Count):for i in range(0, pdfFileObj.get_Pages().Count):O código acima faz um loop por cada página no arquivo PDF usando o get_Pages().Count do IronPDF para obter o número total de páginas.
Extrair texto e segmentá-lo em linhas
page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')Para cada página, o método ExtractTextFromPage é usado para obter todo o texto e, em seguida, usar o método split do Python para quebrá-lo em linhas. Isso resulta em uma lista de linhas que podem ser percorridas em loop.
Gravar as linhas extraídas em um arquivo de texto
for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')Aqui, o código itera por cada linha da lista de linhas, imprimindo-a no console e escrevendo-a no arquivo, adicionando um caractere de nova linha ( \n ) após cada linha para formatar corretamente o texto.
Código completo
Segue abaixo a implementação completa:
from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')Saída
Execute o arquivo Python digitando o seguinte comando no terminal do Visual Studio Code:
python main.pypython main.pyEste resultado será exibido no terminal:
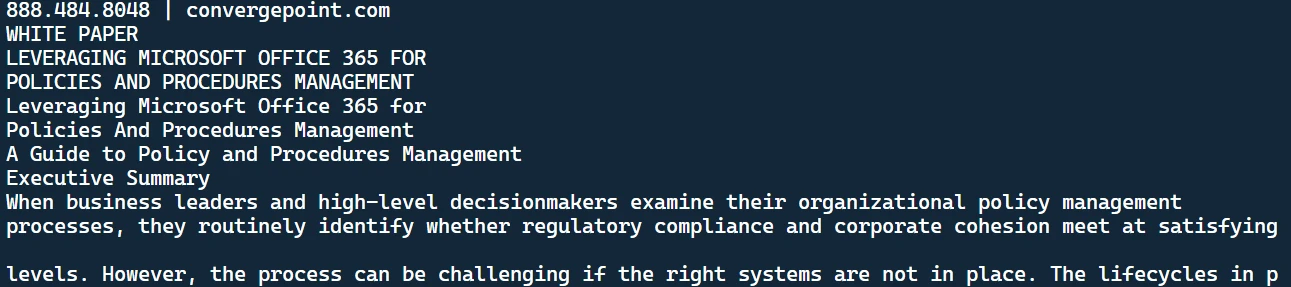 O texto extraído
O texto extraído
Trata-se do texto extraído do arquivo PDF. Você também notará um documento de texto criado em seu diretório.
 O texto extraído está armazenado em um arquivo TXT.
O texto extraído está armazenado em um arquivo TXT.
Neste arquivo de texto, você encontrará o formato do texto recuperado, apresentado sequencialmente.
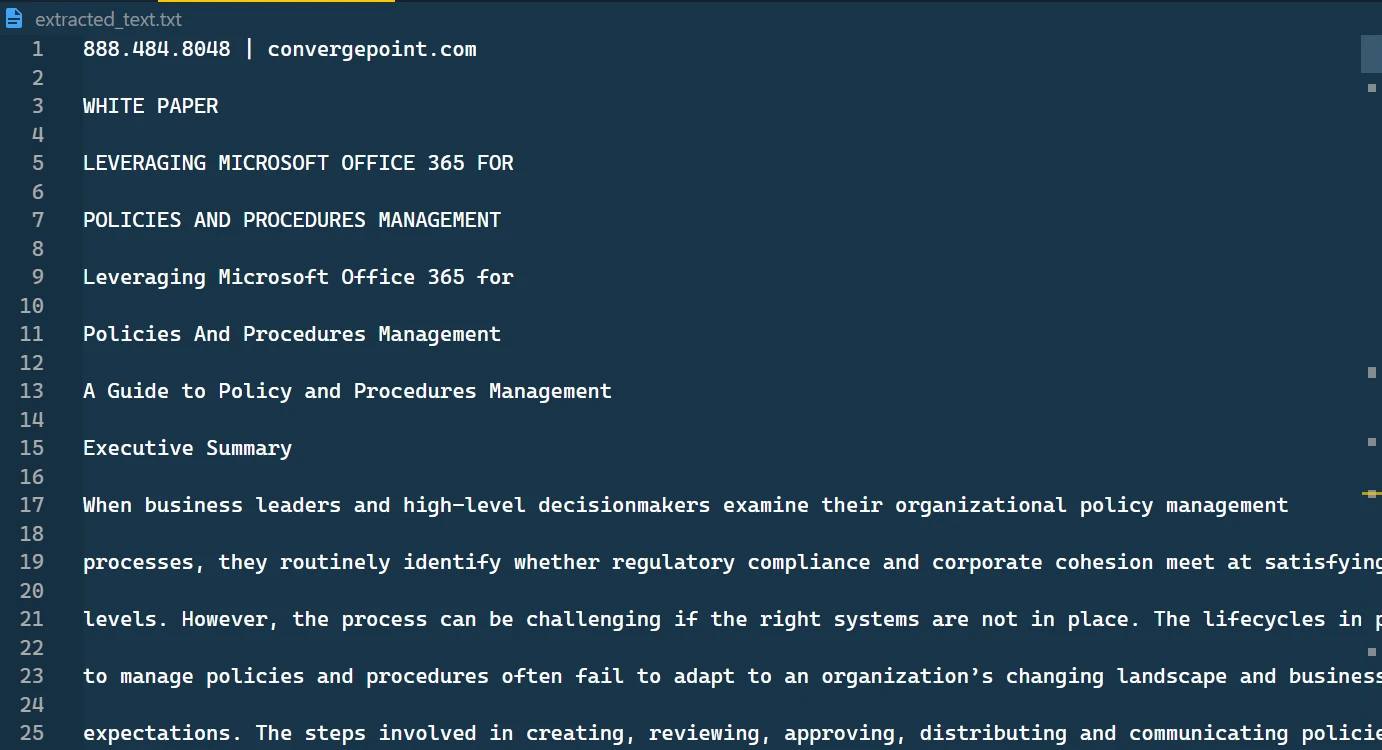 O conteúdo do arquivo de texto extraído
O conteúdo do arquivo de texto extraído
Conclusão
Em resumo, usar IronPDF e Python para extrair texto de arquivos PDF é uma abordagem robusta e direta, seja para extrair texto do documento inteiro, de páginas específicas ou até mesmo linha por linha. A vantagem adicional de salvar o texto extraído em um arquivo de texto permite gerenciar e utilizar os dados de forma eficiente para processamentos futuros. O IronPDF demonstra ser uma ferramenta indispensável no processamento de PDFs, oferecendo uma gama de funcionalidades que vão além da simples extração de texto. Você também pode converter PDF em texto em Python usando o IronPDF.
Além disso, a criação de PDFs interativos, o preenchimento e envio de formulários interativos , a fusão e divisão de arquivos PDF, a extração de texto e imagens , a busca de texto em arquivos PDF, a rasterização de PDFs em imagens , a alteração do tamanho da fonte, da borda e da cor de fundo, e a conversão de arquivos PDF são todas tarefas com as quais o conjunto de ferramentas IronPDF pode ajudar.
IronPDF não é uma biblioteca Python de código aberto. Se você está considerando usar o IronPDF para seus projetos, a licença para o pacote começa em $999. No entanto, se precisar de esclarecimentos sobre o investimento, o IronPDF oferece um período de teste gratuito para que você possa explorar todas as suas funcionalidades.
Perguntas frequentes
Como posso extrair texto de um PDF usando Python?
Você pode usar o IronPDF para extrair texto de arquivos PDF em Python. Isso envolve carregar o PDF com o método PdfDocument.FromFile e iterar pelas páginas para extrair o texto linha por linha.
O que é necessário para começar a extrair texto de PDFs em Python?
Para extrair texto de PDFs em Python, você precisa ter o Python instalado, juntamente com a biblioteca IronPDF, que pode ser instalada via pip. Recomenda-se o uso de uma IDE como o Visual Studio Code para escrever e executar seus scripts.
O IronPDF consegue extrair texto de uma página específica de um PDF?
Sim, o IronPDF permite extrair texto de uma página específica de um PDF usando o método ExtractTextFromPage , especificando o índice da página.
Como posso salvar o texto extraído em um arquivo usando Python?
Após extrair o texto usando o IronPDF, você pode salvá-lo em um arquivo escrevendo as linhas de texto extraídas em um arquivo de texto usando os métodos de manipulação de arquivos do Python.
Além da extração de texto, quais recursos adicionais o IronPDF oferece?
O IronPDF oferece uma ampla gama de recursos, incluindo criação, edição e conversão de PDFs, fusão e divisão de documentos PDF, extração de imagens e conversão de PDFs para outros formatos de arquivo.
Como faço para licenciar o IronPDF no meu projeto Python?
Para licenciar o IronPDF, defina sua chave de licença no script Python usando a propriedade License.LicenseKey , o que desbloqueia todas as funcionalidades da biblioteca.
É possível experimentar o IronPDF antes de comprar?
Sim, o IronPDF oferece uma versão de avaliação que permite testar seus recursos antes de decidir comprar uma licença completa.
O que devo fazer se encontrar problemas durante a extração de texto de um PDF?
Certifique-se de que o IronPDF esteja instalado e licenciado corretamente e que seu ambiente Python esteja configurado adequadamente. Consulte a documentação ou os recursos de suporte para solucionar problemas comuns.
Posso converter um PDF em imagem usando o IronPDF?
Sim, o IronPDF oferece a funcionalidade de rasterizar PDFs em imagens, permitindo converter documentos inteiros ou páginas específicas em arquivos de imagem.
Como faço para executar um script Python para extrair texto de um PDF?
Após escrever seu script, você pode executá-lo digitando python main.py no terminal da sua IDE, onde main.py é o nome do seu arquivo de script.
















