
PDF Sırasıyla Metin Çıkarma
Bu kılavuz, IronPDF'i kullanarak PDF belgelerinden art arda metin çıkarmanın inceliklerini gösterecektir. Python ortamınızı ayarlamaktan, PDF metin çıkarması için ilk Python programınızı çalıştırmaya kadar her şeyi kapsayacaktır.
PDF'den Metin Nasıl Satır Satır Çıkarılır
- PDF dosyasından metin çıkarmak için Python kütüphanesini indirin ve yükleyin.
- Tercih ettiğiniz IDE'de bir Python projesi oluşturun.
- Metin içeriği almak için istenilen PDF dosyasını yükleyin.
- Dahili kütüphane işlevini kullanarak PDF'yi döngüye alın ve metni art arda çıkarın.
- Çıkarılan metni bir dosyaya kaydedin.
IronPDF PDF Python Kütüphanesi
IronPDF, Python'da PDF dosyaları ile çalışmanızı sağlayan kullanışlı bir araçtır. Bunu, PDF dosyalarını okuma, oluşturma ve düzenlemeyi erişilebilir kılan yardımcı bir asistan olarak düşünün. Bir PDF belgesinden içerik çıkarmayı, yeni bilgiler eklemeyi veya bir web sayfasını PDF formatına dönüştürmeyi amaçlıyor olun, IronPDF kapsamlı çözümler sunar. Bu, ücretli bir yazılım paketi olmakla birlikte, satın almadan önce keşfetmeniz için bir deneme sürümü sunar.
Betik koduna dalmadan önce Python ortamınızı ayarlamak esastır. Bu adım adım kılavuz, ortamınızı yapılandırmanıza, Visual Studio Code'da yeni bir Python projesi oluşturmanıza ve IronPDF kütüphane ortamı yapılandırmanızı sağlamanıza yardımcı olacaktır.
Python'u İndirin ve Yükleyin: Eğer Python'u yüklemediyseniz, resmi Python web sitesinden en yeni sürümü indirin. Belirli işletim sisteminiz için kurulum talimatlarını izleyin.
Python Kurulumunu Kontrol Edin: Terminalinizi veya komut isteminizi açın ve python --version yazın. Bu komut, kurulumun başarılı olduğunu onaylayarak yüklü Python sürümünü yazdırmalıdır.
pip'i Güncelleyin: Pip, Python paket yükleyicisidir. pip install --upgrade pip çalıştırarak güncel olduğundan emin olun.
Visual Studio Code'da Yeni Bir Python Projesi Oluşturma
Visual Studio Code'u İndirin: Eğer sahibi değilseniz, resmi web sitesinden indirin.
Python Uzantısını Yükleyin: Visual Studio Code'u açın ve Eklentiler Pazarına gidin. Microsoft'un Python uzantısını arayın ve yükleyin.
Yeni Bir Klasör Oluşturun: Python projenizi bulundurmak istediğiniz yeni bir klasör oluşturun. Bir ad verin, PDF_Text_Extractor gibi anlamlı bir şey.
Klasörü VS Code'da Açın: Klasörü Visual Studio Code'a sürükleyin veya Dosya > Klasörü Aç menü seçeneğini kullanarak klasörü açın.
Bir Python Dosyası Oluşturun: VS Code Gezgini panelinde sağ tıklayın ve Yeni Dosya'yı seçin. Dosyayı main.py veya benzer bir ad verin. Bu dosya Python programınızı barındıracaktır.
 Visual Studio Code'da yeni Python dosyası oluştur
Visual Studio Code'da yeni Python dosyası oluştur
IronPDF Kütüphane Gereksinimi ve Kurulumu
IronPDF, PDF'lerden metin içeriği alma konusunda esastır. İşte nasıl kurulacağı:
VS Code'da Terminal Açın: VS Code içinde terminal açmak için Terminal > Yeni Terminal gidin.
IronPDF'i Yükleyin: Terminalde aşağıdakini çalıştırarak, IronPDF'in en son sürümünü yükleyin:
pip install ironpdf
Bu işlem, IronPDF kütüphanesini ve gerekli tüm modülleri alır ve yükler.
 IronPDF paketi kurun
IronPDF paketi kurun
Ve işte bu kadar! Python ortamınızı başarıyla ayarladınız, Visual Studio Code içinde yeni bir proje oluşturduğunuz ve IronPDF kütüphanesini yüklediniz.
PDF'den Metin Satır Satır Çıkarma
Lisans Anahtarını Uygulama
Devam etmeden önce, IronPDF lisans anahtarınızı uyguladığınızdan emin olun.
from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"YOUR-LICENSE-KEY-HERE öğesini gerçek IronPDF lisans anahtarınızla değiştirin. Bu lisans, projeniz için tüm kütüphane özelliklerinin kilidini açmanıza izin verir.
PDF Dosya Formatını Yükleme
Mevcut bir PDF dosyasını Python programınıza yüklemeniz gerekiyor. Bunu IronPDF'ün PdfDocument.FromFile yöntemi ile gerçekleştirebilirsiniz.
pdfFileObj = PdfDocument.FromFile("content.pdf")pdfFileObj = PdfDocument.FromFile("content.pdf")"content.pdf" okumak istediğiniz PDF dosyasını ifade eder. Bu yüklenen PDF dosyası, bir PDF okuyucu veya PDF dosyası nesnesi olarak kullanılan pdfFileObj değişkeninde saklanır, pdfFileObj.
Tüm PDF Belgesinden Metin Çıkarma
PDF dosyasındaki tüm metin verilerini bir kerede almak istiyorsanız, ExtractAllText yöntemini kullanabilirsiniz.
all_text = pdfFileObj.ExtractAllText()all_text = pdfFileObj.ExtractAllText()ExtractAllText yöntemi burada gösterim amacıyla kullanılır. Bu yöntem, PDF dosyasındaki tüm metni çıkarıp all_text adlı bir değişkende depolar.
Belirli bir PDF Sayfasından Metin Çıkarma
IronPDF, belirli bir sayfadan metin çıkarmayı ExtractTextFromPage yöntemi ile mümkün kılar. Bu yöntem bazı sayfalardan sadece metne ihtiyaç duyduğunuzda faydalıdır.
page_2_text = pdfFileObj.ExtractTextFromPage(1)page_2_text = pdfFileObj.ExtractTextFromPage(1)Burada, ikinci sayfadan metin çıkarıyoruz; bu, 1 indeksine karşılık gelir.
Çıkarılan Metni Yazmak İçin Bir Metin Dosyasını Başlatma
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:with open("extracted_text.txt", "w", encoding='utf-8') as text_file:Metin verilerini kaydetmek için 'extracted_text.txt' adında bir dosya açın. Python'ın yerleşik open fonksiyonu bu iş için kullanılır, dosya modu "yazma" ("w") olarak ayarlanır, Unicode karakterleri yönetmek için encoding='utf-8' kullanılır.
Satır Satır Metin Çıkarması için Her Sayfayı Döngüye Alın
for i in range(0, pdfFileObj.get_Pages().Count):for i in range(0, pdfFileObj.get_Pages().Count):Yukarıdaki kod, IronPDF'ün tüm sayfa numarasını almak için get_Pages().Count kullanarak PDF dosyasındaki her bir sayfada döngü yapar.
Metin Çıkarın ve Satırlara Bölün
page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')Her sayfa için tüm metni almak üzere ExtractTextFromPage yöntemi kullanılır ve ardından Python'ın split yöntemi ile satırlara ayrılır. Bu, döngü yapılabilecek satırların bir listesini oluşturur.
Çıkarılan Satırları Metin Dosyasına Yazın
for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')Burada, kod satırlar listesindeki her satırdan geçer, bunu konsola yazdırır ve ardından her satırdan sonra bir satır sonu karakteri (\n) ekleyerek düzgün bir şekilde formatlandırmak için dosyaya yazar.
Tam Kodu
İşte kapsamlı uygulama:
from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')Çıktı
Visual Studio Code terminalinde aşağıdaki komutu yazarak Python dosyasını çalıştırın:
python main.pypython main.pyBu sonuç terminalde gösterilecektir:
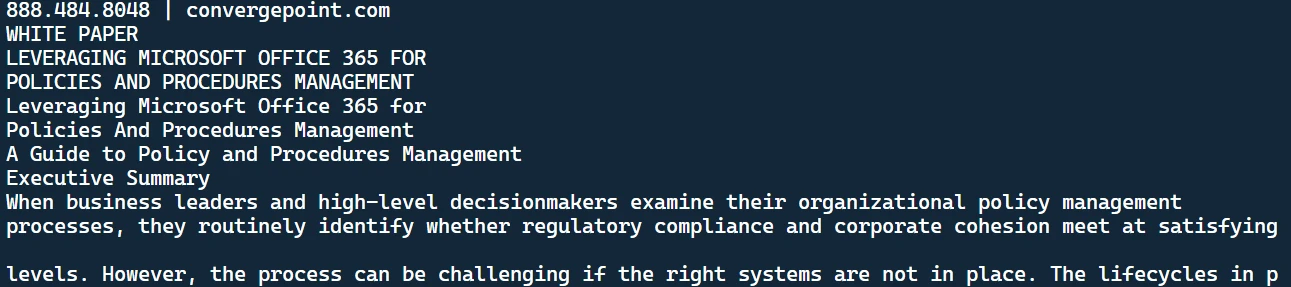 Çıkarılan metin
Çıkarılan metin
Bu, PDF dosyasından alınan metindir. Ayrıca dizininizde oluşturan bir metin belgesi göreceksiniz.
 TXT dosyasında saklanan çıkarılan metin
TXT dosyasında saklanan çıkarılan metin
Bu metin dosyasında, geri alınmış ve sıralı olarak sunulan metin formatını bulacaksınız.
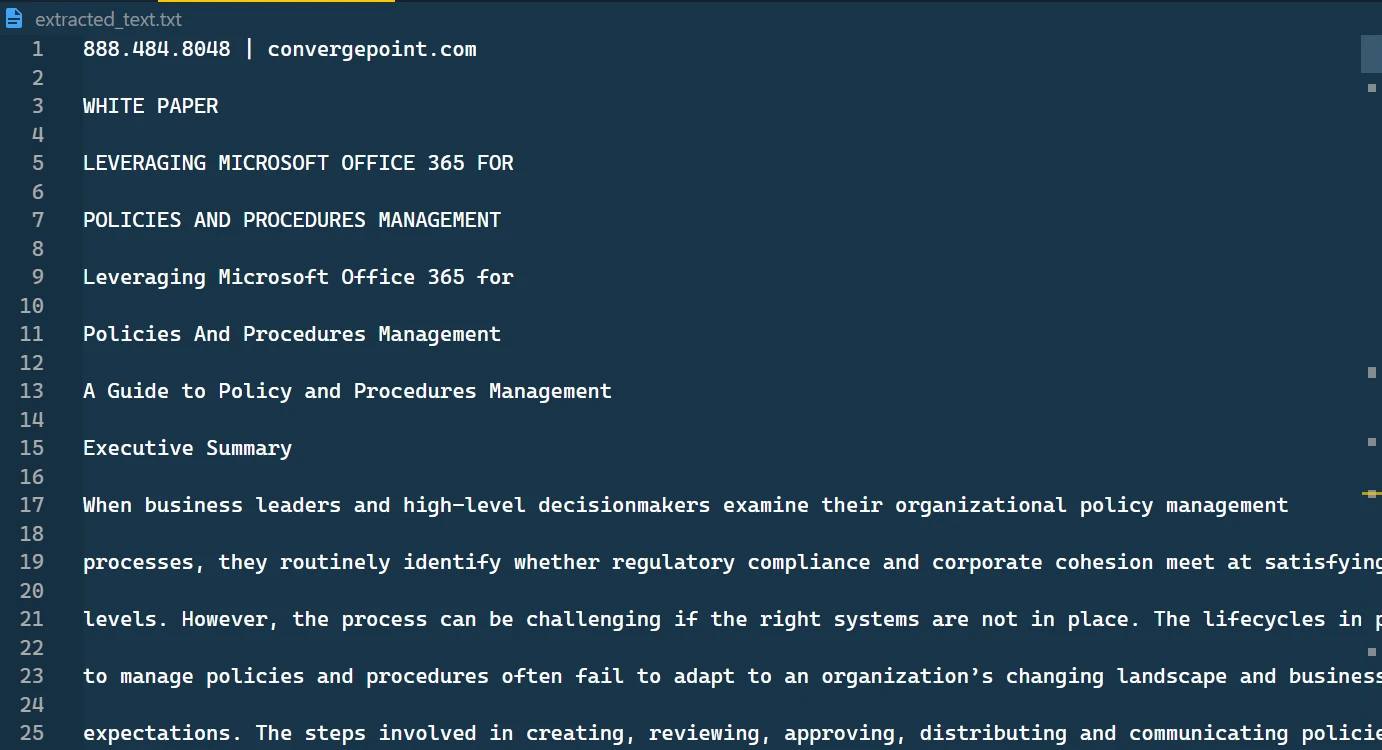 Çıkartılan metin dosyası içeriği
Çıkartılan metin dosyası içeriği
Sonuç
Sonuç olarak, IronPDF ve Python kullanarak PDF dosyalarından metin çıkarmak, belgenin tamamından, belirli sayfalardan veya hatta satır satır metin çekerek sağlam ve basit bir yaklaşımdır. Bu elde edilen metni bir metin dosyasına kaydetmenin ek avantajı, gelecekteki işlemler için verileri etkili bir şekilde yönetmenizi ve kullanmanızı sağlar. IronPDF, yalnızca metin çıkarmanın ötesinde bir dizi işlevsellik sunarak PDF'lerle çalışmada paha biçilmez bir araç olduğunu kanıtlar. IronPDF kullanarak Python'da PDF'yi Metne dönüştürebilirsiniz.
Ayrıca, etkileşimli PDF'ler oluşturma, etkileşimli formları doldurma ve gönderme, PDF dosyalarını birleştirme ve bölme, PDF dosyalarından metin ve resim çıkarma, PDF dosyalarının içinde metin arama, PDF'leri görüntülere dönüştürme, yazı tipi boyutunu, kenarlığı ve arka plan rengini değiştirme ve PDF dosyalarını dönüştürme gibi görevler IronPDF araç seti ile yapılabilir.
IronPDF açık kaynak Python kütüphanesi değildir. Projeleriniz için IronPDF kullanmayı düşünüyorsanız, paketin lisansı $999 ile başlamaktadır. Ancak, yatırım konusunda netlik ihtiyacınız varsa, IronPDF özelliklerini ayrıntılı olarak keşfetmek için bir ücretsiz deneme sunar.
Sıkça Sorulan Sorular
Python kullanarak bir PDF'ten metin nasıl çıkarırım?
IronPDF'yi kullanarak, Python'da PDF dosyalarından metin çıkartabilirsiniz. Bu, PdfDocument.FromFile yöntemini kullanarak PDF'yi yüklemeyi ve sayfalarda döngü yaparak metni satır satır çıkarmayı içerir.
Python'da PDF'lerden metin çıkarmaya başlamak için ne gereklidir?
Python'da PDF'lerden metin çıkarmak için bilgisayarınıza Python ve pip yoluyla yüklenmiş IronPDF kütüphanesi gereklidir. Visual Studio Code gibi bir IDE, komut dosyalarınızı yazmak ve çalıştırmak için önerilir.
IronPDF belirli bir PDF sayfasından metin çıkartabilir mi?
Evet, IronPDF'nin ExtractTextFromPage yöntemi ile belirli bir PDF sayfasından sayfa indeksini belirterek metin çıkartabilirsiniz.
Python'da çıkartılan metni bir dosyaya nasıl kaydedebilirim?
IronPDF kullanarak metin çıkardıktan sonra, Python'un dosya işleme yöntemlerini kullanarak çıkartılan metin satırlarını bir metin dosyasına yazarak kaydedebilirsiniz.
IronPDF metin çıkartmanın dışında hangi ek özellikler sunar?
IronPDF birçok özellikle PDF oluşturma, düzenleme, dönüştürme, PDF belgelerini birleştirme ve ayırma, resim çıkartma ve PDF'leri diğer dosya formatlarına dönüştürme gibi.
Python projemde IronPDF'nin lisansını nasıl alırım?
IronPDF lisansını almak için, Python betiğinizde License.LicenseKey özelliği ile lisans anahtarınızı belirleyin, bu, kütüphanenin tüm işlevselliğini açar.
IronPDF'yi satın almadan önce denemem mümkün mü?
Evet, IronPDF, tüm özelliklerini satın almadan önce denemene olanak tanıyan bir deneme sürümü sunar.
PDF metin çıkartma sırasında sorun yaşarsam ne yapmalıyım?
IronPDF'nin düzgün bir şekilde kurulduğundan ve lisanslandığından ve Python ortamınızın doğru bir şekilde ayarlandığından emin olun. Yaygın sorunları çözümlemek için belgeleri veya destek kaynaklarını inceleyin.
IronPDF kullanarak bir PDF'yi görsele dönüştürebilir miyim?
Evet, IronPDF tüm belgeyi veya belirli sayfaları, görüntü dosyasına dönüştürmeye olanak tanıyan PDF'leri rasterize etme işlevselliği sağlar.
Python metin çıkartma komut dosyamı nasıl çalıştırabilirim?
Komut dosyanızı yazdıktan sonra, main.py dosya adınızdaki main.py 'yi çalıştırarak IDE'nin terminalinde python main.py komutunu çalıştırabilirsiniz.
















