
HTTPX Python (How It Works: A Guide for Developers)
HTTPX is a modern, fully-featured HTTP client for Python that features synchronous and asynchronous APIs. This library provides high efficiency in handling HTTP requests. Several features of this library expand on traditional libraries like Requests; therefore, it's more powerful because it supports HTTP/2, connection pooling, and cookie management.
Integrated with IronPDF, a comprehensive .NET library for creating and editing all PDF documents, HTTPX can fetch data from web APIs or even websites and turn this fetched data into long, nicely formatted PDF reports. One can produce professional, nice-looking documents with the ability of IronPDF to generate a PDF from HTML, images, and simple text, and even support advanced features, such as adding headers, footers, and watermarks. The integration is complete: from data retrieval to producing reports, it offers an efficient way to communicate insights in polished form.
What is Httpx python?
HTTPX is a modern and next-generation HTTP client for Python that borrows some cool ways of using the popular Requests library and combines it with synchronous and asynchronous API support. It seeks to solve complex HTTP tasks with different advanced functionalities like HTTP/2 support, connection pooling, or even automatic cookie management. HTTPX enables developers to send multiple different HTTP requests simultaneously, speeding up an application's performance in cases where web-based interactions are the major expected functionalities.
It offers excellent interoperability with the Requests library, providing an easy upgrade path for developers wanting to upgrade their HTTP client and access more complex features. HTTPX is a flexible tool for modern Python development; it lends itself well to tasks ranging from simple HTTP queries to more complicated and performance-critical web interactions. HTTPX can do both sync and async requests with socks proxy support connection.
Features of Httpx python
HTTPX in Python provides the most valuable features that extend and enhance HTTP request handling. Here are some of its key features:
Synchronous and Asynchronous APIs:
It supports both synchronous and asynchronous request handling. A developer can apply any of the available options in an application based on their needs.
HTTP/2 Support:
This framework has native support for the HTTP/2 protocol, allowing faster and more efficient communication with servers that support it.
Connection Pooling:
Smart HTTP connection: Reuse already established connections and connection pooling sessions to reduce latency and increase speed for many requests.
Automatic Content Decoding:
It automates decoding a compressed response, usually encoded in gzip, making it much easier to deal with and reducing bandwidth.
Timeouts and Retries:
Define timeout request settings for guaranteed non-blocking requests that go past the request timeout—additional retry mechanisms to deal with transient failures.
WebSockets Support:
It supports WebSocket connections, enabling bidirectional communication between the client and the server over a single, long-lived connection.
Proxy Support:
It has built-in support for HTTP proxies. This will enable requests via intermediary servers for privacy or network management.
Cookie Handling:
The library will handle cookies, keeping track of the session state between requests.
Client Certificate:
Client-side certificates are supported to secure communications with servers that use mutual TLS authentication.
Middleware and Hooks:
It allows customization of request and response handling with middleware and hooks. This provides excellent extensibility for developers to extend the functionality of HTTPX according to their requirements. Requests-compatibility: It is designed to use Requests' API, making it very easy for developers from Requests to switch to the HTTPX project and get many new excellent features and improvements.
Create and config Httpx python.
First, you must install the library and set up an environment to configure HTTPX in Python. The HTTPX project relies on HTTP core and the async library autodetection as dependencies, but they should be installed directly when installing the HTTPX project. There is also a variation of HTTPX as a command line client support that comes along with rich terminal support; however, in this article, we would be strictly focused on HTTPX python. The guide below showcases an example of a simple HTTP GET request. For a more comprehensive API reference, please visit the HTTPX documentation here.
Install HTTPX
First, ensure you have HTTPX installed. You can use the command line client to install:
pip install httpxpip install httpxImport HTTPX and Make a Basic Request
When installed, you can import HTTPX and fire off a simple HTTP GET request as follows:
import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")- A function fetch_data, using an asynchronous context manager inside to open an HTTP client, makes a GET request to a given URL.
- Stores the HTTP response object returned by
httpx.get(url).
Setting Up Advanced Features in HTTPX
Advanced features of HTTPX support a wide array of other configurations, like handling proxies, headers, and timeouts. Here is how to set up HTTPX with more options:
import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")- Timeout: It sets the timeout for the HTTP request to 30 seconds. This is to prevent the request from blocking indefinitely.
- It adds a custom
User-Agentheader to the request{ "User-Agent": "MyApp/1.0" }, identifying the client application. - response.json() - This parses the response content as JSON, assuming the response includes JSON data.

Getting Started
To use HTTPX with Python and IronPDF to generate PDFs. First, you need to configure HTTPX to fetch data from some source, and then IronPDF will create a PDF report from the acquired data. Here is how to do it in detail:
What is IronPDF?
The mighty and robust Python library IronPDF enables the production, editing, and reading of PDFs. It allows programmers to perform many programmatically based operations on PDFs, such as editing already-existing PDFs and converting HTML files into PDF files. IronPDF makes generating high-quality reports in PDF format more straightforward and more flexible. Accordingly, this makes it practical for applications that create and process PDFs dynamically.
HTML to PDF Conversion
IronPDF enables the conversion of any HTML data into a PDF document, regardless of age. This allows the creation of stunning, artistic PDF publications from web content that fully exploit the modern capabilities of HTML5, CSS3, and JavaScript.
Create and Edit PDFs
It is possible to generate new PDF documents containing text, pictures, tables, and other content through a programming language. IronPDF can also open and modify pre-existing PDF documents for additional customization. Any content included in a PDF document may be added, changed, or removed at will.
Complex design and styling
This is achieved through the PDF content styling achieved by CSS, which can handle intricate layouts with various fonts, colors, and other design elements. Besides, handling dynamic content within PDFs is ensured in the place of JavaScript, which shall ease rendering HTML content.
Install IronPDF
IronPDF can be installed with pip. The command to install is as follows:
pip install ironpdfpip install ironpdfCombine httpx with IronPDF for Python
Use HTTPX to Fetch Data From an API or Website. The following example shows how to retrieve data from a fake API in JSON format.
import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
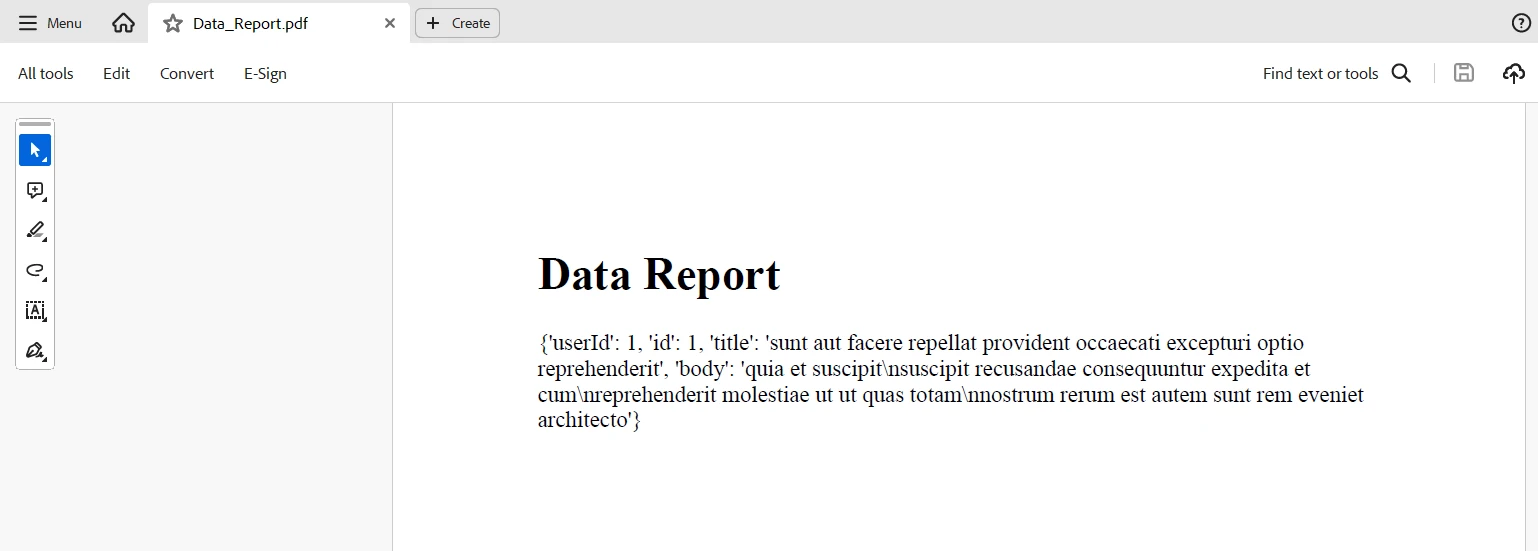
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")- This is designed to synchronously fetch data from web APIs or websites using HTTPX. It is a practical library because it is prepared for both synchronous and asynchronous operations, processing different HTTP requests simultaneously. An example would be hitting a mock API endpoint returning JSON data.
- IronPDF is utilized through Python; a .NET Engine contracted to produce PDF reports with the above-mentioned fetched data. IronPDF can generate PDFs from HTML content and convert this data into structured documents.
- IronPDF Integration: Python allows you to interact with IronPDF. It shall result in developing a PDF document (
pdf) based on dynamically generated HTML content (html_content). Data is fetched through HTTPX. This HTML content will be based on dynamically fetched data; thus, personalized and real-time reports can be obtained.
Conclusion
This HTTPX integration with IronPDF combines two powers into your Python: data retrieval and professional-grade PDF generation. This means HTTPX shall be perfect for fetching data over web APIs or websites since it supports both asynchronous and synchronous styles for handling HTTP requests. On the other hand, IronPDF makes it easy to generate polished and professional-grade PDF reports from fetched data through Python .NET interop, thus adorning this visualization and conveyance of data insights.
It mitigates everything from the most straightforward data retrieval to writing reports, giving flexibility while dealing with many discrete data sources and formats. It empowers the developer to generate detailed PDFs for presentation or documentation or even archive all data analysis findings. All these utilities and Python applications will turn raw data into professionally formatted reports, ensuring productivity and decision-making in any chosen domain.
Integrate IronPDF and IronSoftware products to provide rich, high-end software solutions to your clients and their users. This will streamline project operations and procedures.
In addition to all the basic features, IronPDF has complete documentation, a lively community, and frequent updates. Based on this information, Iron Software is a reliable partner for modern software development projects. Developers can try IronPDF for a free trial to review all its features. Afterward, the license starts at $799 and upwards.
















