
msgpack python(開發人員工作原理)
MessagePack是一種高效的二進位序列化格式,允許在多種語言之間進行資料交換。 它類似於 JSON,但速度更快、體積更小。 Python 中的msgpack函式庫提供了處理此格式所需的工具,它既提供了 CPython 綁定,也提供了純 Python 實作。
MessagePack 的主要特性
1.效率: MessagePack 的設計目標是在速度和大小上都比 JSON 更有效率。它透過二進位格式(msgpack 規範)來實現這一點,從而減少了與 JSON 等基於文字的格式相關的開銷。 2.跨語言支援: MessagePack 支援多種程式語言,使其成為需要在不同的系統和語言之間共享資料的應用程式的理想選擇。 3.相容性: Python 中的 msgpack 函式庫與 Python 2 和 Python 3 以及 CPython 和 PyPy 實作皆相容。 4.自訂資料類型: MessagePack 允許對自訂資料類型進行打包和解包,並提供進階解包控制,這對於複雜的應用程式非常有用。
安裝
在開始讀取和寫入 MessagePack 資料之前,您需要安裝msgpack庫,這可以透過 pip 完成:
pip install msgpackpip install msgpack基本用法
以下是一個使用 MessagePack 進行資料序列化和反序列化的簡單範例:
import msgpack
# Serialize key-value pairs or file-like object
data = {'key': 'value', 'number': 42}
packed_data = msgpack.packb(data, use_bin_type=True)
# Deserialize data
unpacked_data = msgpack.unpackb(packed_data, raw=False)
print(unpacked_data)import msgpack
# Serialize key-value pairs or file-like object
data = {'key': 'value', 'number': 42}
packed_data = msgpack.packb(data, use_bin_type=True)
# Deserialize data
unpacked_data = msgpack.unpackb(packed_data, raw=False)
print(unpacked_data)進階功能
1.串流解包: MessagePack 支援串流解包,它可以從單一串流解包多個物件。 這對於處理大型資料集或連續資料流非常有用。
import msgpack
from io import BytesIO
# Create a buffer for streaming data
buf = BytesIO()
for i in range(100):
buf.write(msgpack.packb(i))
buf.seek(0)
# Unpack data from the buffer
unpacker = msgpack.Unpacker(buf)
for unpacked in unpacker:
print(unpacked)import msgpack
from io import BytesIO
# Create a buffer for streaming data
buf = BytesIO()
for i in range(100):
buf.write(msgpack.packb(i))
buf.seek(0)
# Unpack data from the buffer
unpacker = msgpack.Unpacker(buf)
for unpacked in unpacker:
print(unpacked)2.自訂資料類型:您可以為自訂資料類型定義自訂打包和解包函數。例如,要處理 datetime 自訂資料類型:
import datetime
import msgpack
def encode_datetime(obj):
"""Encode datetime objects for MessagePack serialization."""
if isinstance(obj, datetime.datetime):
return {'__datetime__': True, 'as_str': obj.strftime('%Y%m%dT%H:%M:%S.%f')}
return obj
def decode_datetime(obj):
"""Decode datetime objects after MessagePack deserialization."""
if '__datetime__' in obj:
return datetime.datetime.strptime(obj['as_str'], '%Y%m%dT%H:%M:%S.%f')
return obj
# Serialize data with custom datetime support
data = {'time': datetime.datetime.now()}
packed_data = msgpack.packb(data, default=encode_datetime)
# Deserialize data with custom datetime support
unpacked_data = msgpack.unpackb(packed_data, object_hook=decode_datetime)
print(unpacked_data)import datetime
import msgpack
def encode_datetime(obj):
"""Encode datetime objects for MessagePack serialization."""
if isinstance(obj, datetime.datetime):
return {'__datetime__': True, 'as_str': obj.strftime('%Y%m%dT%H:%M:%S.%f')}
return obj
def decode_datetime(obj):
"""Decode datetime objects after MessagePack deserialization."""
if '__datetime__' in obj:
return datetime.datetime.strptime(obj['as_str'], '%Y%m%dT%H:%M:%S.%f')
return obj
# Serialize data with custom datetime support
data = {'time': datetime.datetime.now()}
packed_data = msgpack.packb(data, default=encode_datetime)
# Deserialize data with custom datetime support
unpacked_data = msgpack.unpackb(packed_data, object_hook=decode_datetime)
print(unpacked_data)IronPDF簡介
IronPDF是一個功能強大的 Python 庫,旨在利用 HTML、CSS、圖像和JavaScript創建、編輯和簽署 PDF。 它提供商業級的效能,同時佔用記憶體極少。 主要特點包括:
HTML 轉 PDF
將 HTML 檔案、HTML 字串和 URL 轉換為 PDF。 例如,使用 Chrome PDF 渲染器將網頁渲染為 PDF。
跨平台支援
與各種.NET平台相容,包括.NET Core、 .NET Standard和.NET Framework。 它支援 Windows、Linux 和 macOS。
編輯和簽署
設定屬性,使用密碼和權限添加安全性,並為您的 PDF 應用數位簽章。
頁面模板和設置
使用頁首、頁尾、頁碼和可調整的邊距自訂 PDF。 支援響應式佈局和自訂紙張尺寸。
標準合規性
符合 PDF 標準,例如 PDF/A 和 PDF/UA。 支援 UTF-8 字元編碼,並可處理圖像、CSS 和字體等資源。
使用IronPDF和 msgpack 產生 PDF 文檔
import msgpack
import datetime
from ironpdf import *
# Apply your license key for IronPDF
License.LicenseKey = "key"
# Serialize data
data = {'key': 'value', 'number': 42}
packed_data = msgpack.packb(data, use_bin_type=True)
# Deserialize data
unpacked_data = msgpack.unpackb(packed_data, raw=False)
print(unpacked_data)
# Custom Data Types
def encode_datetime(obj):
"""Encode datetime objects for MessagePack serialization."""
if isinstance(obj, datetime.datetime):
return {'__datetime__': True, 'as_str': obj.strftime('%Y%m%dT%H:%M:%S.%f')}
return obj
def decode_datetime(obj):
"""Decode datetime objects after MessagePack deserialization."""
if '__datetime__' in obj:
return datetime.datetime.strptime(obj['as_str'], '%Y%m%dT%H:%M:%S.%f')
return obj
datat = {'time': datetime.datetime.now()}
packed_datat = msgpack.packb(datat, default=encode_datetime)
unpacked_datat = msgpack.unpackb(packed_datat, object_hook=decode_datetime)
print(unpacked_datat)
# Render a PDF from a HTML string using Python
renderer = ChromePdfRenderer()
content = "<h1>Awesome Iron PDF with msgpack</h1>"
content += "<h3>Serialize data</h3>"
content += f"<p>{data}</p>"
content += f"<p> msgpack.packb(data, use_bin_type=True):</p><p>{packed_data}</p>"
content += "<h3>Deserialize data</h3>"
content += f"<p> msgpack.unpackb(packed_data, raw=False):</p><p>{unpacked_data}</p>"
content += "<h3>Encode Custom Data Types</h3>"
content += f"<p>{datat}</p>"
content += f"<p> msgpack.packb(datat, default=encode_datetime):</p><p>{packed_datat}</p>"
pdf = renderer.RenderHtmlAsPdf(content)
pdf.SaveAs("Demo-msgpack.pdf") # Export to a fileimport msgpack
import datetime
from ironpdf import *
# Apply your license key for IronPDF
License.LicenseKey = "key"
# Serialize data
data = {'key': 'value', 'number': 42}
packed_data = msgpack.packb(data, use_bin_type=True)
# Deserialize data
unpacked_data = msgpack.unpackb(packed_data, raw=False)
print(unpacked_data)
# Custom Data Types
def encode_datetime(obj):
"""Encode datetime objects for MessagePack serialization."""
if isinstance(obj, datetime.datetime):
return {'__datetime__': True, 'as_str': obj.strftime('%Y%m%dT%H:%M:%S.%f')}
return obj
def decode_datetime(obj):
"""Decode datetime objects after MessagePack deserialization."""
if '__datetime__' in obj:
return datetime.datetime.strptime(obj['as_str'], '%Y%m%dT%H:%M:%S.%f')
return obj
datat = {'time': datetime.datetime.now()}
packed_datat = msgpack.packb(datat, default=encode_datetime)
unpacked_datat = msgpack.unpackb(packed_datat, object_hook=decode_datetime)
print(unpacked_datat)
# Render a PDF from a HTML string using Python
renderer = ChromePdfRenderer()
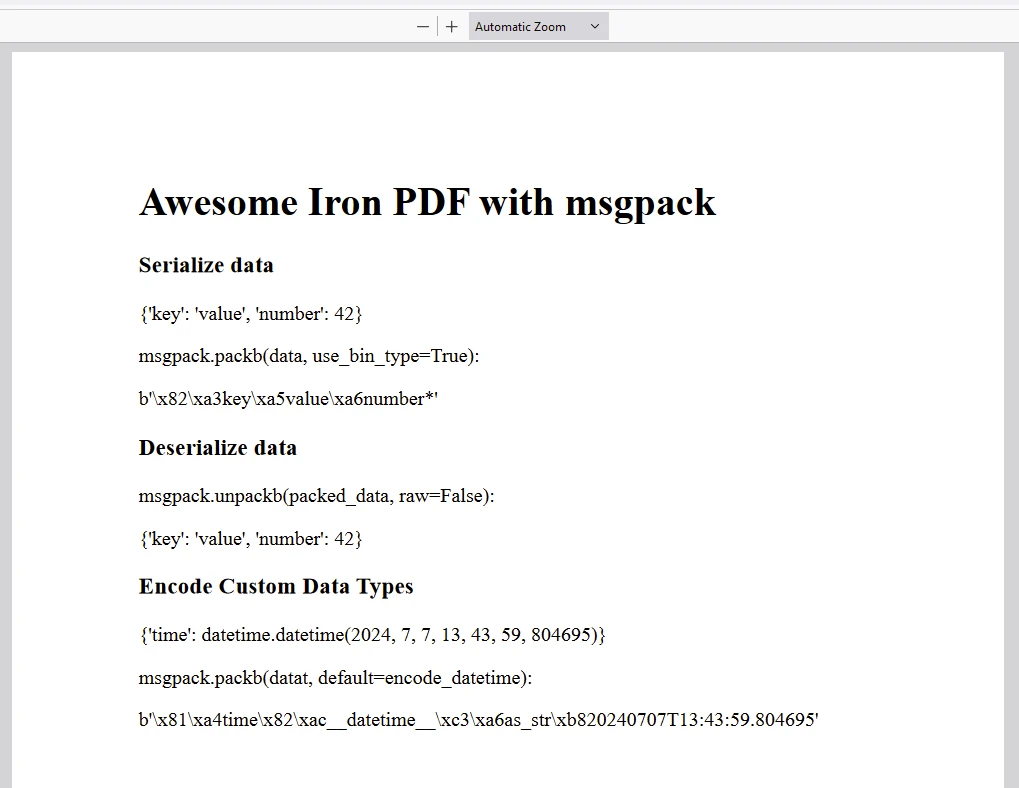
content = "<h1>Awesome Iron PDF with msgpack</h1>"
content += "<h3>Serialize data</h3>"
content += f"<p>{data}</p>"
content += f"<p> msgpack.packb(data, use_bin_type=True):</p><p>{packed_data}</p>"
content += "<h3>Deserialize data</h3>"
content += f"<p> msgpack.unpackb(packed_data, raw=False):</p><p>{unpacked_data}</p>"
content += "<h3>Encode Custom Data Types</h3>"
content += f"<p>{datat}</p>"
content += f"<p> msgpack.packb(datat, default=encode_datetime):</p><p>{packed_datat}</p>"
pdf = renderer.RenderHtmlAsPdf(content)
pdf.SaveAs("Demo-msgpack.pdf") # Export to a file程式碼解釋
該腳本演示了 msgpack 與IronPDF的集成,用於序列化和反序列化數據,以及從 HTML 內容創建 PDF 文件。
分解
1.使用 msgpack 序列化資料:
* 使用 @@--CODE-708--CODE-709--CODE-709 將 Python 資料(本例為字典)轉換為二進位格式 (`packed_data`)。2.使用 msgpack 反序列化資料:
* 使用 `msgpack.unpackb()` 和 `raw=False` 將二進位資料 `packed_data` 轉換回 Python 資料 (`unpacked_data`)。3.自訂資料類型處理:
* 定義自訂編碼 (`encode_datetime`) 和解碼 (`decode_datetime`) 函數,以便在使用 msgpack 進行序列化和反序列化期間處理日期時間物件。4.用於產生 PDF 的 HTML 內容:
* 建立一個包含以下內容的 HTML 字串 (`content`):
* 詳細說明序列化資料的標題和子部分(`data` 和 `packed_data`)。
* 反序列化資料(`unpacked_data`)。
* 自訂資料類型序列化(`datat` 和 `packed_datat`)。5.使用IronPDF產生 PDF:
* 使用IronPDF (ChromePdfRenderer)從建構的 HTML 內容(`content`)產生 PDF 文件(`pdf`)。6.保存 PDF 檔案:
* 將產生的 PDF 文件儲存為"Demo-msgpack.pdf"。輸出

IronPDF許可
IronPDF需要 Python 許可證金鑰才能運作。 IronPDF for Python 提供免費試用許可證金鑰,使用戶能夠在購買前體驗其豐富的功能。
在使用IronPDF軟體包之前,請將許可證密鑰放在腳本的開頭:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"結論
MessagePack 是 Python 中用於高效資料序列化的強大工具。 它緊湊的二進位格式、跨語言支援以及處理自訂資料類型的能力,使其成為各種應用的通用選擇。 無論您是在進行不同系統之間的資料交換,還是優化資料處理任務的效能,MessagePack 都能提供強大的解決方案。
IronPDF是一個功能強大的 Python 庫,旨在直接從 Python 應用程式建立、操作和渲染 PDF 文件。 它簡化了諸如將 HTML 轉換為 PDF、建立互動式 PDF 表單以及執行各種文件操作(如合併和分割 PDF 文件)等任務。 IronPDF與現有 Web 技術無縫集成,為開發人員提供了一套強大的工具集,用於生成動態 PDF,從而提高文件管理和演示任務的效率。
















