
Pandas Python的數據科學指南
Pandas是 Python 程式語言中流行的資料分析工具,以其易用性和處理表格資料的多功能性而聞名。 本指南將帶您了解使用 Pandas 的基本知識,重點介紹實際範例和高效的資料處理與分析技術。
理解 DataFrame:Pandas 的核心
1. 在 Pandas 中存取數據
Pandas的主要結構是 DataFrame,它是用於資料分析和操作的強大工具。 首先,讓我們來探討如何存取DataFrame中的資料。
1.1 從 CSV 檔案載入數據
例如,如果您有一個包含資料的 CSV 文件,您可以將其載入到 DataFrame 中並開始對其進行操作。 以下程式碼示範如何從 CSV 檔案載入資料:
import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')1.2 存取列數據
載入完成後,有多種方法可以存取 DataFrame 中的資料。 您可以使用列名存取列資料。 例如,以下程式碼存取名為"data"的欄位中的資料:
# Access data from a column named 'data'
column_data = df['data']# Access data from a column named 'data'
column_data = df['data']1.3 存取行數據
同樣,您也可以使用行索引或條件存取行資料:
# Accesses the first row of the DataFrame
row_data = df.loc[0]# Accesses the first row of the DataFrame
row_data = df.loc[0]2. 處理資料框中的空值
資料分析中常見的問題之一是處理空值。 Pandas 提供了強大的方法來處理這些問題。 程式碼會將空值填入指定的值,或者您可以刪除包含空值的行或列。 以下是一個如何填充空值的程式碼範例:
# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)3. 建立和操作列
資料框(DataFrame)的靈活性體現在允許建立新列。 無論是新建整數列還是從現有資料派生的列,過程都很簡單。 以下是向 DataFrame 新增列的範例:
# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10您也可以根據條件篩選資料。 例如,如果您想要建立一個新列,其中包含名為"column_named_data"的欄位中大於某個特定值的資料:
# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]進階資料處理技術
1. 資料分組與匯總
Pandas 擅長資料分組和聚合。 以下程式碼使用groupby方法按指定列對資料進行分組,並計算平均值、總和等聚合函數:
# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()2. 日期和時間數據
在許多資料集中,日期和時間的處理至關重要。 如果你的 DataFrame 包含日期列,Pandas 可以簡化按日期篩選、按月或按年聚合等任務。以下是一個基本範例:
# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])3. 自訂資料操作
對於更複雜的資料處理需求,Pandas 允許您編寫自訂函數並將其應用於您的 DataFrame。 這對於需要語言整合查詢方法的場景尤其有用。
def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)數據視覺化與展示
Pandas 可以很好地與 Matplotlib 和 Seaborn 等資料視覺化函式庫整合。 以視覺化格式顯示資料可以像以下原始程式碼所示那樣簡單:
import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()在 Python 中將IronPDF與 Pandas 整合以增強資料分析
正如我們之前討論過的,Pandas 是 Python 中用於資料操作和分析的強大工具。 IronPDF是由Iron Software開發的函式庫,它提供了額外的功能,可以提升資料分析工作流程,尤其是在處理 PDF 內容時,從而完善自身的功能。
IronPDF:概述
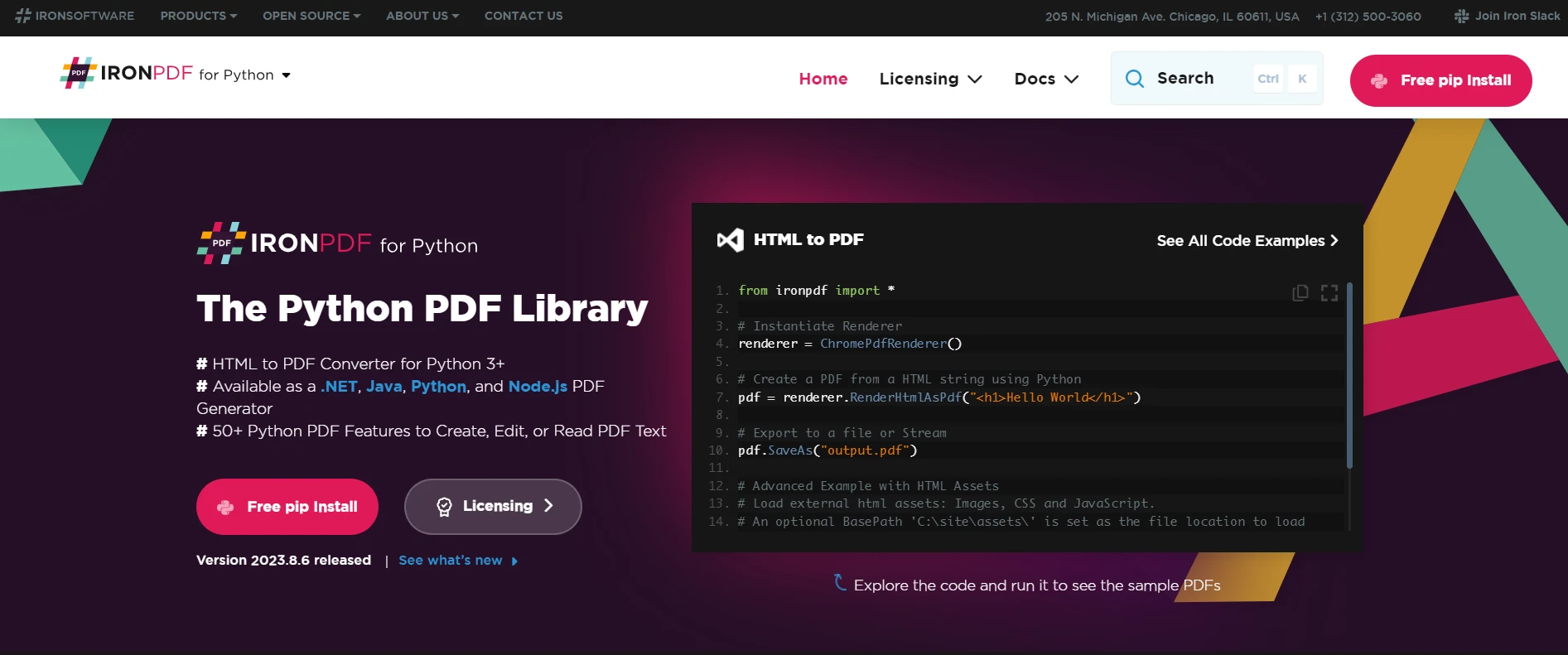
IronPDF是一個功能強大的 Python PDF 庫,用於在 Python 專案中建立、編輯和提取 PDF 內容。 它旨在跨多個平台運行,包括 Windows、Mac、Linux 和雲端環境,使其成為各種 Python 專案的理想選擇。 該程式庫在處理 PDF 文件方面功能尤其強大,可提供流暢的體驗和高效的處理,這對於處理 PDF 資料的開發人員來說至關重要。
與熊貓的協同作用
將IronPDF與 Pandas 集成,為更高級的數據處理和報告開闢了可能性。 想像這樣的分析工作流程:您使用 Pandas 進行資料處理和分析,然後使用IronPDF將結果和視覺化無縫轉換為專業格式的 PDF 報告。 這種整合可以顯著簡化資料分析結果的共享和展示過程。
結論
總之,雖然 Pandas 為資料分析提供了基礎,但整合IronPDF為 Python 中的資料分析工作流程增添了新的維度。 這種組合不僅提高了資料處理和分析過程的效率,而且顯著改善了資料的呈現和共享方式,使其成為基於 Python 的資料分析師和科學家的寶貴資產。
IronPDF供有興趣在購買前了解其功能的用戶使用。
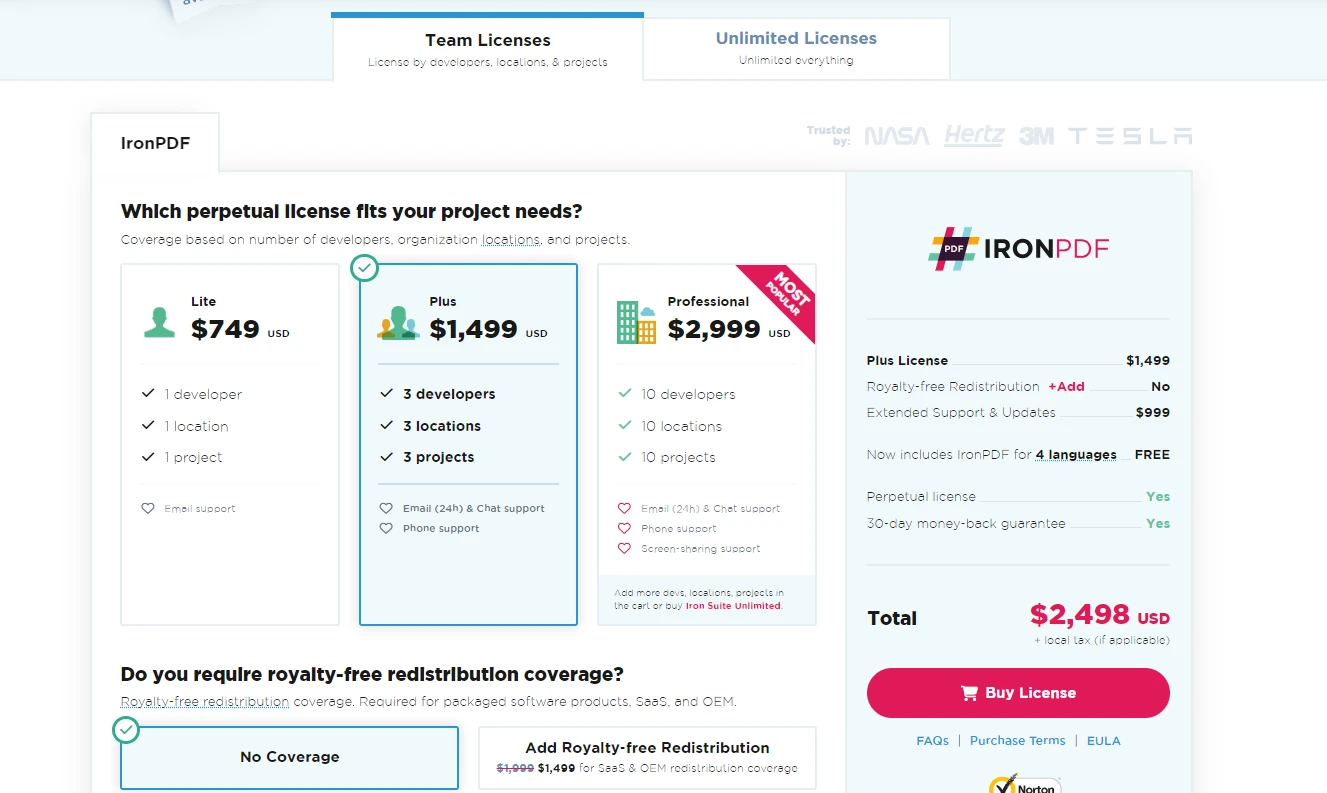
對於希望獲得完整授權的用戶, IronPDF允許用戶選擇最符合其專案需求和預算的方案。
















