
如何逐行從 PDF 中提取文本
本指南將展示如何使用IronPDF在 Python 中按順序從 PDF 文件中提取文字。 它將涵蓋從設定 Python 環境到執行第一個用於提取 PDF 文字的 Python 程式的所有內容。
如何逐行從 PDF 中提取文本
- 使用 Python 下載並安裝 PDF 庫,從 PDF 文件行中提取文字。
- 在您喜歡的 IDE 中建立一個 Python 專案。
- 載入要檢索文字內容的 PDF 檔案。
- 遍歷 PDF 文件,並使用內建庫的功能按順序提取文字。
- 將提取的文字儲存到文件中。
IronPDF PDF Python庫
IronPDF是一個方便的工具,它允許你在 Python 中處理 PDF 檔案。 您可以把它想像成一個得力的助手,讓您可以輕鬆閱讀、建立和編輯 PDF 文件。 無論您是想從 PDF 文件中提取內容、添加新信息,還是將網頁轉換為 PDF 格式, IronPDF都能提供全面的解決方案。 這是一個付費軟體,但他們提供試用版供您在購買前體驗。
在開始編寫腳本之前,設定 Python 環境至關重要。 本逐步指南將協助您配置環境,在 Visual Studio Code 中建立一個新的 Python 項目,並設定IronPDF庫環境配置。
下載並安裝 Python:如果您還沒有安裝 Python,請從Python 官方網站下載最新版本。 請依照您作業系統對應的安裝說明進行操作。
檢查 Python 安裝:開啟終端機或命令提示符,輸入python --version 。 此指令應列印已安裝的 Python 版本,以確認安裝成功。
更新 pip: pip是 Python 套件安裝程式。 執行pip install --upgrade pip 命令確保它是最新版本。
在 Visual Studio Code 中建立新的 Python 項目
下載 Visual Studio Code:如果您還沒有安裝,請從官方網站下載。
安裝 Python 擴充功能:開啟 Visual Studio Code 並前往擴充市場。 搜尋並安裝微軟提供的Python擴充功能。
建立新資料夾:建立一個新資料夾,用於存放您的 Python 專案。 給它一個相關的名字,例如PDF_Text_Extractor 。
在 VS Code 中開啟資料夾:將資料夾拖曳到 Visual Studio Code 中,或使用"檔案">"開啟資料夾"功能表選項開啟資料夾。
建立 Python 檔案:在 VS Code 資源管理器面板中右鍵單擊,然後選擇"新檔案" 。 將檔案命名為main.py或類似名稱。 這個文件將存放你的Python程式。
如何逐行從 PDF 中提取文本,圖 1:在 Visual Studio Code 中建立新的 Python 文件 在 Visual Studio Code 中建立一個新的 Python 文件
IronPDF庫的要求和安裝
IronPDF對於從 PDF 文件中檢索文字內容至關重要。 以下是安裝方法:
在 VS Code 中開啟終端機:您可以透過前往"終端">"新終端"在 VS Code 中開啟終端。
安裝IronPDF:在終端機中執行以下指令安裝最新版本的IronPDF:
pip install ironpdf
此程序會檢索並安裝IronPDF庫以及任何必要的模組。
 安裝IronPDF軟體包
安裝IronPDF軟體包
就是這樣! 您現在已經成功設定了 Python 環境,在 Visual Studio Code 中建立了一個新項目,並安裝了IronPDF庫。
逐行擷取 PDF 中的文本
應用許可證密鑰
在繼續操作之前,請確保您已套用IronPDF許可證密鑰。
from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"from ironpdf import PdfDocument
# Apply your license key to unlock library features
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"請將 YOUR-LICENSE-KEY-HERE 替換為您的IronPDF實際許可證金鑰。 此許可證可讓您解鎖項目所需的所有庫功能。
載入 PDF 文件格式
你需要將一個現有的 PDF 檔案載入到你的 Python 程式中。 您可以使用IronPDF的 PdfDocument.FromFile 方法來實現此目的。
pdfFileObj = PdfDocument.FromFile("content.pdf")pdfFileObj = PdfDocument.FromFile("content.pdf")"content.pdf"指的是您想要閱讀的PDF檔案。 載入的 PDF 檔案儲存在 pdfFileObj 變數中,用作 PDF 閱讀器或 PDF 文件物件 pdfFileObj。
從整個 PDF 文件中提取文本
如果要一次取得 PDF 檔案中的所有文字數據,可以使用 ExtractAllText 方法。
all_text = pdfFileObj.ExtractAllText()all_text = pdfFileObj.ExtractAllText()這裡使用 ExtractAllText 方法是為了示範目的。 此方法從 PDF 檔案中提取所有文字並將其儲存在名為 all_text 的變數中。
從特定 PDF 頁面中提取文本
IronPDF可以使用 ExtractTextFromPage 方法從特定頁面擷取文字。 當您只需要某些頁面上的文字時,此方法非常有用。
page_2_text = pdfFileObj.ExtractTextFromPage(1)page_2_text = pdfFileObj.ExtractTextFromPage(1)在這裡,我們從第二頁提取文本,對應的索引為 1。
初始化文字檔案以寫入提取的文本
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:with open("extracted_text.txt", "w", encoding='utf-8') as text_file:開啟名為"extracted_text.txt"的文件,儲存文字資料。 Python 內建的 open 函數用於此目的,將檔案模式設為"寫入"( "w" ),並使用 encoding='utf-8' 處理 Unicode 字元。
遍歷每一頁,逐行擷取文字
for i in range(0, pdfFileObj.get_Pages().Count):for i in range(0, pdfFileObj.get_Pages().Count):上面的程式碼使用 IronPDF 的 get_Pages().Count 循環遍歷 PDF 檔案中的每一頁,以取得總頁數。
提取文字並將其分割成行
page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')page_text = pdf.ExtractTextFromPage(i)
lines = page_text.split('\n')對於每一頁,使用 ExtractTextFromPage 方法獲取所有文本,然後使用 Python 的 split 方法將其分成行。 這樣就得到了一個可以循環遍歷的行列表。
將提取的行寫入文字文件
for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')for eachline in lines:
print(eachline)
text_file.write(eachline + '\n')這裡,程式碼遍歷行列表中的每一行,將其列印到控制台,並透過在每一行後添加換行符( \n )將其寫入文件,以正確格式化此文字。
完整程式碼
以下是完整的實施方案:
from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')from ironpdf import PdfDocument
# Apply your license key
License.LicenseKey = "Your-License-Key-Here"
# Load an existing PDF file
pdfFileObj = PdfDocument.FromFile("content.pdf")
# Extract text from the entire PDF file
all_text = pdfFileObj.ExtractAllText()
# Extract text from a specific page in the file (Page 2)
page_2_text = pdfFileObj.ExtractTextFromPage(1)
# Initialize a file object for writing the extracted text
with open("extracted_text.txt", "w", encoding='utf-8') as text_file:
# Get the number of pages in the PDF document
num_of_pages = pdfFileObj.get_Pages().Count
print("Number of pages in given document are ", num_of_pages)
# Loop through each page using the Count property
for i in range(0, num_of_pages):
# Extract text from the current page
page_text = pdfFileObj.ExtractTextFromPage(i)
# Split the text by lines from this page object
lines = page_text.split('\n')
# Loop through the lines and print/write them
for eachline in lines:
print(eachline) # Print each line to the console
# Write each line to the text document
text_file.write(eachline + '\n')輸出
在 Visual Studio Code 終端機中輸入以下命令來執行 Python 檔案:
python main.pypython main.py結果將顯示在終端上:
如何逐行從 PDF 中提取文本,圖 3:提取的文本 提取的文本
這是從 PDF 文件中提取的文本。您還會注意到目錄中建立了一個文字檔案。
 提取的文字儲存在TXT檔案中
提取的文字儲存在TXT檔案中
在這個文字檔案中,您將找到已擷取的文字格式,並按順序呈現。
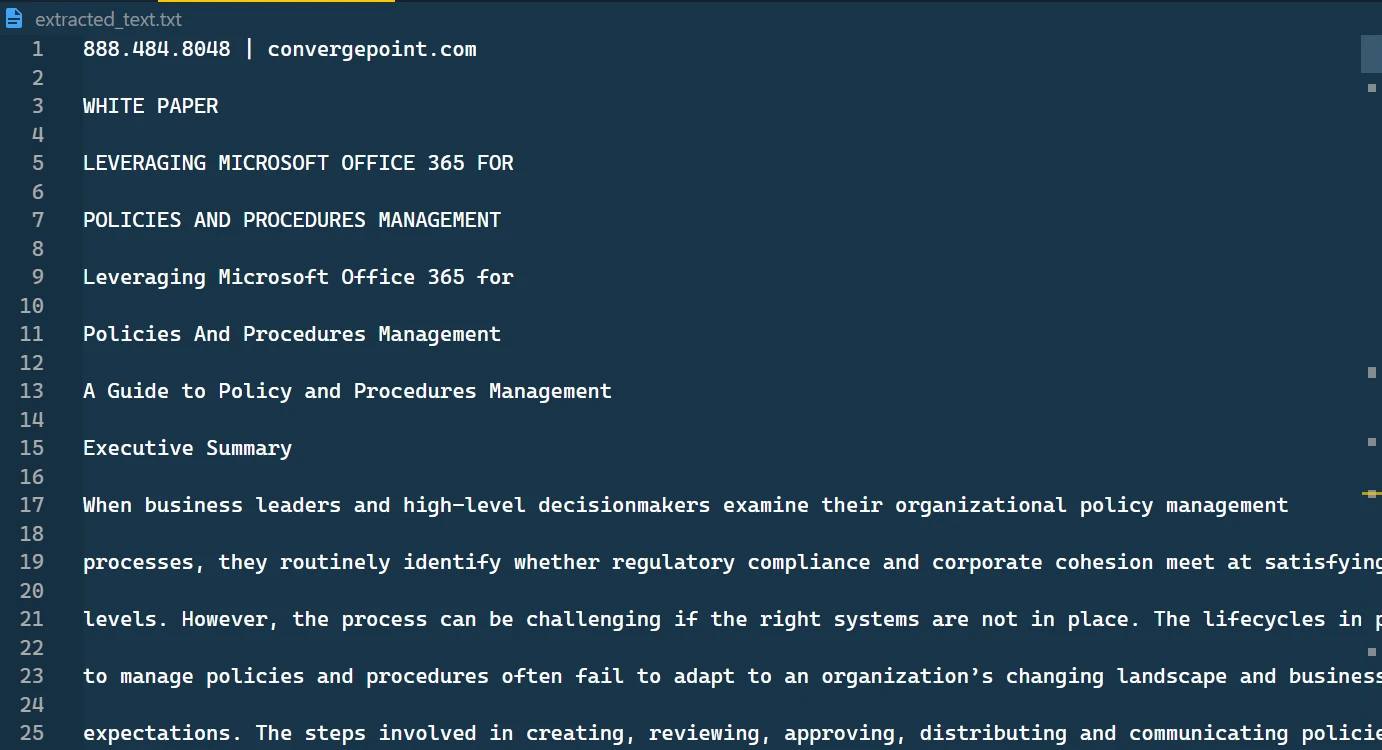 提取的文本文件內容
提取的文本文件內容
結論
總之,使用IronPDF和 Python 從 PDF 文件中提取文字是一種強大而簡單的方法,無論是從整個文件、特定頁面還是逐行提取文字。此外,將擷取的文字儲存到文字檔案中,以便於您有效率地管理和利用這些資料進行後續處理。 IronPDF被證明是處理 PDF 的非常寶貴的工具,它提供的功能遠不止文字擷取。 您也可以使用IronPDF在 Python 中將 PDF 轉換為文字。
此外,IronPDF 工具包還可以幫助完成以下任務:建立互動式 PDF、填寫和提交互動式表單、合併和分割PDF 文件、提取文字和圖像、在 PDF 文件中搜尋文字、將 PDF 柵格化為圖像、更改字體大小、邊框和背景顏色以及轉換IronPDF文件。
IronPDF不是一個開源的 Python 函式庫。 如果您正在考慮在您的專案中使用IronPDF ,則軟體套件的授權從 $799 開始。 不過,如果您需要了解投資詳情, IronPDF提供免費試用版,讓您可以全面了解其功能。
常見問題解答
如何提取 PDF 中的文本使用 Python?
您可以使用 IronPDF 在 Python 中從 PDF 文件中提取文本。這涉及使用 PdfDocument.FromFile 方法加載 PDF,然後迭代頁面逐行提取文本。
在 Python 中開始從 PDF 提取文本需要什麼?
在 Python 中從 PDF 提取文本,您需要安裝 Python 和 IronPDF 庫,這可以通過 pip 安裝。建議使用 Visual Studio Code 等 IDE 來編寫和執行您的腳本。
IronPDF 能否從 PDF 的特定頁面提取文本?
是的,IronPDF 允許您通過指定頁面索引,使用 ExtractTextFromPage 方法從 PDF 的特定頁面提取文本。
如何在 Python 中將提取的文本保存到文件中?
使用 IronPDF 提取文本後,您可以通過 Python 的文件處理方法將提取的文本行寫入文本文件來保存它。
IronPDF 除了文本提取以外還提供哪些其他功能?
IronPDF 提供廣泛的功能,包括創建、編輯和轉換 PDF,合併和拆分 PDF 文檔,提取圖像,以及將 PDF 轉換為其他文件格式。
我如何在我的 Python 項目中啟用 IronPDF 的許可證?
要啟用 IronPDF 許可證,請在 Python 腳本中使用 License.LicenseKey 屬性設置您的許可證密鑰,這將解鎖庫的全部功能。
購買前可以試用 IronPDF 嗎?
是的,IronPDF 提供試用版本,允許您在決定購買完整許可證之前評估其功能。
如果在提取 PDF 文本時遇到問題應該怎麼辦?
確保 IronPDF 已正確安裝和許可,並且您的 Python 環境已正確設置。查閱文檔或支持資源以排除常見問題。
我可以使用 IronPDF 將 PDF 轉換為圖像嗎?
是的,IronPDF 提供將 PDF 光柵化為圖像的功能,允許您將整個文檔或特定頁面轉換為圖像文件。
如何執行 Python 腳本以提取 PDF 文本?
編寫腳本後,可以在 IDE 的終端中運行 python main.py 執行它,其中 main.py 是您的腳本文件名。
















