Python 中的 Scrapy (開發人員的工作原理)
在網路資料抓取和文件產生領域,有效性和效率至關重要。 要從網站提取資料並將其轉換為專業水準的文檔,就需要將強大的工具和框架無縫整合。
接下來是 Scrapy,一個 Python 中的網路爬蟲框架,以及IronPDF,這兩個強大的庫協同工作,以優化線上資料的提取和動態PDF的創建。
借助 Python 中的 Scrapy(一款頂級的網頁爬蟲和抓取庫),開發人員現在可以輕鬆瀏覽複雜的網絡,並快速、精確地提取結構化資料。 憑藉其強大的 XPath 和 CSS 選擇器以及非同步架構,它是抓取任何複雜程度任務的理想選擇。
相反, IronPDF是一個功能強大的.NET庫,支援以程式設計方式建立、編輯和操作 PDF 文件。 IronPDF為開發人員提供了一套完整的解決方案,透過其強大的 PDF 創建工具(包括 HTML 到 PDF 轉換和 PDF 編輯功能),可以產生動態且美觀的 PDF 文件。
本文將帶您了解Scrapy Python與IronPDF的無縫集成,並向您展示此動態組合如何改變網頁抓取和文件創建的方式。 我們將展示這兩個函式庫如何協同工作,以簡化複雜的任務並加快開發工作流程,從使用 Scrapy 從網頁抓取資料到使用IronPDF動態產生 PDF 報告。
歡迎探索網路爬蟲和文件產生的可能性,我們將使用IronPDF來充分利用 Scrapy。

非同步架構
Scrapy 使用的非同步架構能夠同時處理多個請求。 這提高了效率,加快了網頁抓取速度,尤其是在處理複雜的網站或大量資料時。
堅固的爬行管理
Scrapy 具有強大的爬蟲流程管理功能,例如自動 URL 過濾、可設定的請求調度和整合的 robots.txt 指令處理。 開發者可以調整爬蟲行為,以滿足自身需求並確保遵守網站準則。
XPath 和 CSS 選擇器
Scrapy 允許使用者使用 XPath 和 CSS 選擇器在 HTML 頁面中導覽和選擇項目。 這種適應性使得資料擷取更加精確可靠,因為開發人員可以精確地針對網頁上的特定元素或模式。
物品管道
開發者可以使用 Scrapy 的專案管道,為抓取的資料指定可重複使用的元件,以便在匯出或儲存之前對其進行處理。透過執行清洗、驗證、轉換和去重等操作,開發者可以確保提取資料的準確性和一致性。
內建中介軟體
Scrapy 中預先安裝的許多中間件元件提供了諸如自動 cookie 處理、請求限制、使用者代理程式輪替和代理程式輪替等功能。 這些中間件元素易於配置和自訂,可提高抓取效率並解決常見問題。
可擴展架構
透過建立自訂中間件、擴充和管道,開發人員可以藉助 Scrapy 的模組化和可擴充架構,進一步個人化和擴展其功能。 由於其適應性強,開發人員可以輕鬆地將 Scrapy 整合到他們當前的流程中,並對其進行修改以滿足他們獨特的抓取需求。
使用 Python 建立和配置 Scrapy
安裝 Scrapy
使用pip安裝 Scrapy,執行以下命令:
pip install scrapypip install scrapy蜘蛛的定義
要定義你的爬蟲,請在 spiders/ 目錄下建立一個新的 Python 檔案(例如 example.py)。 這裡提供了一個從 URL 中提取資訊的基本爬蟲範例:
import scrapy
class QuotesSpider(scrapy.Spider):
# Name of the spider
name = 'quotes'
# Starting URL
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
# Iterate through each quote block in the response
for quote in response.css('div.quote'):
# Extract and yield quote details
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
# Identify and follow the next page link
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)import scrapy
class QuotesSpider(scrapy.Spider):
# Name of the spider
name = 'quotes'
# Starting URL
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
# Iterate through each quote block in the response
for quote in response.css('div.quote'):
# Extract and yield quote details
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
# Identify and follow the next page link
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)配置設定
若要設定 Scrapy 專案的參數,例如使用者代理、下載延遲和管道,請編輯 settings.py 檔案。以下範例展示如何變更使用者代理程式並使管道正常運作:
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Set user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
# Configure pipelines
ITEM_PIPELINES = {
'myproject.pipelines.MyPipeline': 300,
}入門
使用 Scrapy 和IronPDF需要將 Scrapy 強大的網頁抓取功能與 IronPDF 的動態 PDF 生成功能結合。 下面我將逐步指導您如何設定 Scrapy 項目,以便您可以從網站提取資料並使用IronPDF建立包含這些資料的 PDF 文件。
IronPDF是什麼?
IronPDF是一個功能強大的.NET庫,用於以程式設計方式使用 C#、 .NET和其他.NET語言建立、編輯和更改 PDF 文件。 由於它為開發人員提供了動態創建高品質 PDF 的廣泛功能集,因此是許多程式的熱門選擇。
IronPDF的特點
PDF 產生:使用IronPDF,程式設計師可以建立新的 PDF 文檔,或將現有的 HTML 元素(如標籤、文字、圖像和其他文件格式)轉換為 PDF。 此功能對於動態建立報表、發票、收據和其他文件非常有用。
HTML 轉 PDF 轉換: IronPDF可讓開發人員輕鬆地將 HTML 文件(包括JavaScript和 CSS 中的樣式)轉換為 PDF 檔案。 這使得可以從網頁、動態生成的內容和 HTML 模板創建 PDF 文件成為可能。
PDF 文件的修改和編輯: IronPDF提供了一套全面的功能,用於修改和更改預先存在的 PDF 文件。 開發人員可以合併多個 PDF 文件,將它們拆分成單獨的文檔,刪除頁面,並添加書籤、註釋和浮水印等功能,以根據自己的需求自訂 PDF。
如何安裝IronPDF
確保計算機上已安裝 Python 後,使用 pip 安裝IronPDF。
pip install ironpdf
使用IronPDF的 Scrapy 項目
要定義你的爬蟲,請在 Scrapy 專案的爬蟲目錄中建立一個新的 Python 檔案(例如 myproject/myproject/spiders)。 以下是一個從 URL 中提取引用的基本爬蟲程式碼範例:
import scrapy
from IronPdf import *
class QuotesSpider(scrapy.Spider):
name = 'quotes'
# Web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
title = quote.css('span.text::text').get()
content = quote.css('span small.author::text').get()
quotes.append((title, content)) # Append quote to list
# Generate PDF document using IronPDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
# Generate HTML content for PDF using extracted quotes
html_content = "<html><head><title>Quotes</title></head><body>"
for title, content in quotes:
html_content += f"<h2>{title}</h2><p>Author: {content}</p>"
html_content += "</body></html>"
return html_contentimport scrapy
from IronPdf import *
class QuotesSpider(scrapy.Spider):
name = 'quotes'
# Web page link
start_urls = ['http://quotes.toscrape.com']
def parse(self, response):
quotes = []
for quote in response.css('div.quote'):
title = quote.css('span.text::text').get()
content = quote.css('span small.author::text').get()
quotes.append((title, content)) # Append quote to list
# Generate PDF document using IronPDF
renderer = ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(self.get_pdf_content(quotes))
pdf.SaveAs("quotes.pdf")
def get_pdf_content(self, quotes):
# Generate HTML content for PDF using extracted quotes
html_content = "<html><head><title>Quotes</title></head><body>"
for title, content in quotes:
html_content += f"<h2>{title}</h2><p>Author: {content}</p>"
html_content += "</body></html>"
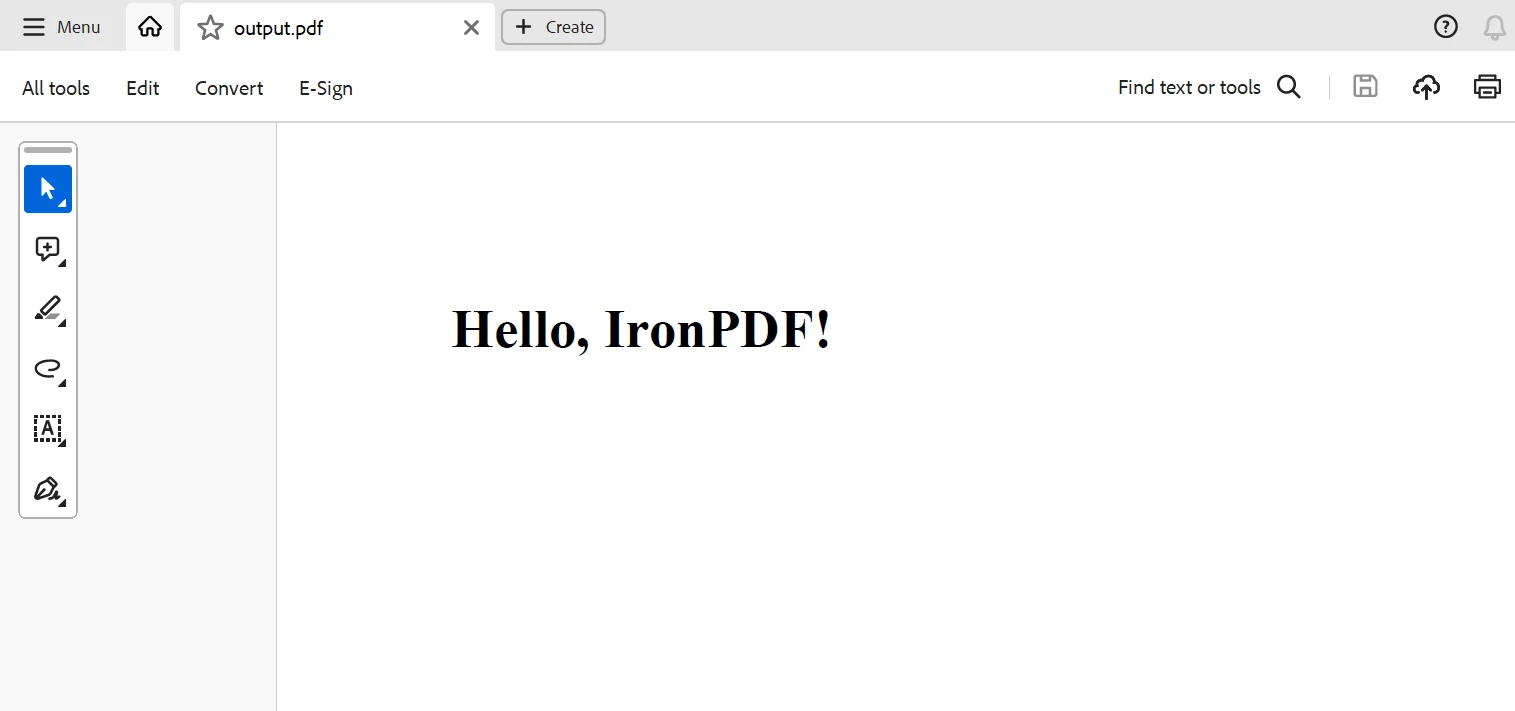
return html_content在上面使用IronPDF的 Scrapy 專案程式碼範例中, IronPDF正在使用 Scrapy 擷取的資料建立PDF 文件。
在這裡,爬蟲的 parse 方法從網頁中收集引用,並使用 get_pdf_content 函數建立 PDF 文件的 HTML 內容。隨後,使用IronPDF將此 HTML 內容渲染為 PDF 文檔,並儲存為 quotes.pdf。
結論
總而言之,Scrapy 和IronPDF的結合為開發人員提供了一個強大的選擇,可以自動執行網頁抓取活動並即時產生 PDF 文件。 IronPDF 靈活的 PDF 生成功能與 Scrapy 強大的網路爬蟲和抓取功能相結合,可輕鬆從任何網頁收集結構化數據,並將提取的數據轉換為專業品質的 PDF 報告、發票或文件。
透過使用 Scrapy Spider Python,開發人員可以有效地駕馭互聯網的複雜性,從多個來源檢索訊息,並以系統化的方式進行整理。 Scrapy 的靈活框架、非同步架構以及對 XPath 和 CSS 選擇器的支持,使其具備管理各種網路抓取活動所需的靈活性和可擴展性。
IronPDF包含終身許可證,捆綁購買價格相當合理。 軟體包物超所值,只需 $799(一次性購買即可用於多個系統)。 持有許可證的使用者可享有全天候線上技術支援。 有關費用的更多詳情,請瀏覽網站。 請造訪此頁面以了解更多關於Iron Software產品的資訊。
常見問題解答
如何將Scrapy與PDF生成工具集成?
您可以通過先使用Scrapy從網站提取結構化數據,然後使用IronPDF將其轉換為動態PDF文檔來將Scrapy與PDF生成工具進行整合。
抓取數據並將其轉換為PDF的最佳方式是什麼?
最好的方式是使用Scrapy高效地提取數據,然後使用IronPDF從提取的內容生成高質量的PDF。
如何在 Python 中將 HTML 轉換為 PDF?
雖然IronPDF是一個.NET庫,您可以通過像Python.NET這樣的互操作性解決方案來使用Python來使用IronPDF的轉換方法將HTML轉換為PDF。
使用Scrapy進行網頁抓取有哪些優勢?
Scrapy提供了異步處理、強大的XPath和CSS選擇器以及可自定義的中間件等優勢,這些功能簡化了從複雜網站中提取數據的過程。
我可以自動將網路數據創建為PDF嗎?
可以,您可以通過整合Scrapy進行數據提取和IronPDF進行PDF生成來自動化網路數據創建為PDF的過程,從抓取到文檔創建的工作流程無縫銜接。
中間件在Scrapy中的角色是什麼?
Scrapy中的中間件允許您控制和自定義請求和響應的處理,實現自動URL過濾和用戶代理輪換等功能以提高抓取效率。
如何在Scrapy中定義爬蟲?
要在Scrapy中定義爬蟲,請在項目的spiders目錄中創建一個新的Python文件,並實現擴展scrapy.Spider的類,包含如parse等方法以處理數據提取。
IronPDF為什麼是生成PDF的合適選擇?
IronPDF是一個合適的PDF生成選擇,因為它提供了HTML到PDF轉換、動態PDF創建、編輯和操作的全面功能,滿足各種文檔生成需求的多功能性。
如何增強網路數據提取和PDF創建?
通過使用Scrapy進行高效數據抓取和IronPDF將提取的數據轉換為專業格式的PDF文件來增強網路數據提取和PDF創建。