LoopBack node js(开发者如何使用)
通过 IronPDF 的流畅集成提供了一个完整的解决方案,用于在 LoopBack 框架应用程序中动态生成 PDF。IronPDF 是一个用于以编程方式创建 PDF 文档的库,结合使用 LoopBack,这是一个用于构建 API 的 Node.js 框架。具有模型创建、数据源验证、远程方法和访问控制等功能,LoopBack 框架使 API/网页开发变得更容易,而 IronPDF 则通过更复杂的 PDF 生成能力来增强它。
开发人员可以通过这个集成从多个来源(包括外部 API 和数据库)提取数据来实时创建 PDF。 这使得可以创建自定义记录或业务领域对象以满足项目需求,例如发票、证书、报告等。 由于LoopBack是异步的,它补充了IronPDF的功能,能够很好地处理PDF生成任务,而不会干扰事件循环,确保响应性和最佳性能。
要开始使用 LoopBack 和 IronPDF,首先使用 LoopBack 的 CLI 工具创建一个新项目,并使用 npm 将 IronPDF 作为依赖项安装。 利用 LoopBack 的中间件和远程方法功能来响应客户端请求即时创建 PDF,简单地实现了集成。 总而言之,这种集成使开发人员能够有效地处理 LoopBack 应用程序内的各种文档生成需求。
什么是 LoopBack Node.js?
名为 LoopBack 的强大 Node.js 框架被创造用于简化创建 API 并将它们连接到不同数据源的过程。 凭借 LoopBack,一个 StrongLoop 的产品,开发人员可以轻松设计出可伸缩且适应性强的应用程序。从根本上来说,LoopBack 是在 express 框架之上构建的,并且基于模型驱动开发方法论,这让程序员可以创建表示其应用程序域的数据模型。 关系数据库如 MySQL 和 PostgreSQL,NoSQL 数据库如 MongoDB,以及外部 REST API 和 SOAP 服务,都可以轻松与这些模型集成。
LoopBack 独特之处在于它通过基于给定模型自动生成 RESTful 端点来简化 API 开发过程。 此外,LoopBack 内置了验证、权限和认证的支持,让程序员可以保护其 API 并保证数据的完整性。 因为 LoopBack 的中间件架构基于 Express.js,所以它具有可扩展性和灵活性,使得开发人员可以与已有中间件一起使用,或者创建自定义中间件来满足特定需求。
无论您是在创建一个简单的 REST API 还是一个复杂的微服务架构,LoopBack 都具备加速开发并生成可靠、可扩展解决方案所需的能力和工具。 由于其详实的文档和活跃的社区,开发人员在创建先进的在线和移动应用程序时经常选择它。

LoopBack 的特性
-模型驱动架构: LoopBack 通过允许开发人员通过基于模式的方法定义数据模型,从而支持模型驱动开发。 可以用模型来表示多种数据源,包括数据库、REST API 和 SOAP 服务。 -数据源无关性:关系数据库(MySQL、PostgreSQL)、NoSQL 数据库(MongoDB)、外部 REST API 和 SOAP 服务只是 LoopBack 支持的众多数据源中的几个例子。 -自动生成 REST API: LoopBack 使用预定义的模型在 API Explorer 中自动创建 RESTful API 端点,从而减少样板代码并加快开发速度。 -内置身份验证和授权支持: LoopBack 提供对这些功能的内置支持,使开发人员能够将基于角色的访问控制 (RBAC)、用户身份验证和其他安全措施集成到他们的 API 中。 -中间件和远程方法:为了改变 API 端点的行为,开发人员可以使用 LoopBack 提供中间件和远程方法。 虽然远程方法提供了可以通过 HTTP 远程调用的自定义功能,但中间件功能可以拦截并修改请求和响应。
- LoopBack 的命令行界面 (CLI): LoopBack 包含一个强大的 CLI 工具,可以简化创建模型和控制器、构建新项目和执行迁移等典型活动。 -与 LoopBack 组件集成: LoopBack 简化了组件的使用,这些组件是可重用的模块,提供电子邮件发送、文件存储和身份验证功能。 这使得开发人员无需从头开始为他们的应用程序添加新功能。
- LoopBack Explorer:开发人员可以使用 LoopBack 集成的 API Explorer 工具交互式地检查和测试 API 端点。 这有助于进行调试并理解 API 的可能性。
创建和配置 LoopBack Node.js JS
您可以使用以下步骤在 Node.js 中设置和构建 LoopBack 应用程序:
安装 LoopBack CLI
安装 LoopBack 命令行接口(CLI),它提供了构建和管理 LoopBack 应用程序的资源,这是第一步。使用 npm 全局安装它:
npm install -g @loopback/clinpm install -g @loopback/cli创建一个新的 LoopBack 应用程序
使用 CLI 来创建一个全新的核心 LoopBack 应用程序。 打开您希望构建应用程序的目录并在其中执行命令:
lb4 applb4 app只需按照提示提供关于您应用程序的信息,如其名称和目录以及您希望启用的功能。
您将被提示提供以下信息:
1.项目名称:输入您的应用程序名称,例如my-loopback-app 。 2.项目描述:(可选)描述您的应用程序。 3.项目根目录:接受默认目录或指定其他目录。 4.应用程序类名:接受默认的应用程序。 5.启用 Prettier:选择是否启用 Prettier 进行代码格式化。 6.启用 TSLINT:选择是否启用 TSLint 进行代码检查。 7.启用 Mocha:选择是否启用 Mocha 来运行测试。
CLI 将生成项目结构并安装所需的依赖项。
浏览项目结构
您的项目目录将具有以下结构:
my-loopback-app/
├── src/
│ ├── controllers/
│ ├── models/
│ ├── repositories/
│ ├── index.ts
│ ├── application.ts
│ └── ...
├── package.json
├── tsconfig.json
└── ...定义模型
要指定您的数据结构,请手动开发模型或使用 LoopBack CLI。 模型可以通过多种数据结构和来源进行支持,代表应用程序中的对象。 例如,运行以下命令以生成一个名为 Product 的新模型:
lb4 modellb4 model要指定模型的属性和连接,请遵循说明。
创建控制器
要处理创建 PDF 文档的请求,创建一个新的控制器。 在 LoopBack CLI 中使用以下命令创建一个新的控制器:
lb4 controllerlb4 controller要定义控制器的名称和相关模型,只需按照提示进行。假设我们想将控制器的属性名称与 Report 模型关联,并称之为 ReportController。
定义数据源
确定您的模型将与哪些数据源通信。 LoopBack 支持许多数据库,如 MySQL、PostgreSQL、MongoDB 等。 要配置您的数据源,更新 datasources.json 文件或使用 LoopBack CLI。
探索 LoopBack
使用内置的API浏览器工具,可在http://localhost:3000/explorer访问,来调查LoopBack的功能。 您可以在此处探索和测试您的 API 端点。
示例 Ping 控制器代码
import {inject} from '@loopback/core';
import {
Request,
RestBindings,
get,
response,
ResponseObject,
} from '@loopback/rest';
/**
* OpenAPI response for ping()
*/
const PING_RESPONSE: ResponseObject = {
description: 'Ping Response',
content: {
'application/json': {
schema: {
type: 'object',
title: 'PingResponse',
properties: {
greeting: {type: 'string'},
date: {type: 'string'},
url: {type: 'string'},
headers: {
type: 'object',
properties: {
'Content-Type': {type: 'string'},
},
additionalProperties: true,
},
},
},
},
},
};
/**
* A simple controller to bounce back http requests
*/
export class PingController {
constructor(@inject(RestBindings.Http.REQUEST) private req: Request) {}
// Map to `GET /ping`
@get('/ping')
@response(200, PING_RESPONSE)
ping(): object {
// Reply with a greeting, the current time, the url, and request headers
return {
greeting: 'Hello from LoopBack',
date: new Date(),
url: this.req.url,
headers: Object.assign({}, this.req.headers),
};
}
}以上代码的输出。

开始
我们将首先创建一个示例应用程序,该应用程序使用 LoopBack Node.js 和 IronPDF 创建具有动态生成信息的 PDF 文档。 这是一个包含详细说明的分步手册。
什么是 IronPDF?
IronPDF 是一个应用程序库,开发它是为了简化创建、编辑和维护 PDF。 通过此应用程序,开发人员可以从 HTML 文档中提取文本和图像、应用页眉和水印、合并多个 PDF 文档,以及执行多种其他活动。 IronPDF 的用户友好型 API 和全面的文档,使开发人员能够轻松自动创建高质量的 PDF 文档。 无论是用于准备发票、报告还是文档,IronPDF 都提供所有功能和能力来改善文档工作流程并提供一流的用户体验。
IronPDF的功能
- HTML 转 PDF 是一个简单快捷的过程,可用于任何 HTML 内容,包括 CSS 和 JavaScript。
- PDF 文件合并:为了简化文档管理工作,可以将多个 PDF 文档合并为一个 PDF 文件。 -文本和图像提取:从 PDF 文件中提取文本和图像,以便进行额外的数据分析或处理。 -水印:出于安全或品牌推广的原因,您可以向 PDF 页面添加文字或图片水印。 -添加页眉和页脚: PDF 文档的页眉和页脚允许您添加自定义消息或页码。
安装 IronPDF
要启用IronPDF功能,请使用节点包管理器安装所需的Node.js包。
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdf将 LoopBack 与 IronPDF Node.js 整合
在创建的控制器文件(report.controller.js)中实现以下逻辑,以使用IronPDF创建PDF文档:
import {inject} from '@loopback/core';
import {Request, RestBindings, get, response} from '@loopback/rest';
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF license key, if needed
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({licenseKey: ''});
/**
* Controller handling PDF generation
*/
export class ReportController {
constructor(@inject(RestBindings.Http.REQUEST) private req: Request) {}
@get('/generate-pdf', {
responses: {
'200': {
description: 'PDF file',
content: {'application/pdf': {schema: {type: 'string', format: 'binary'}}},
},
},
})
async generatePdf(): Promise<Buffer> {
// HTML content to be converted to PDF
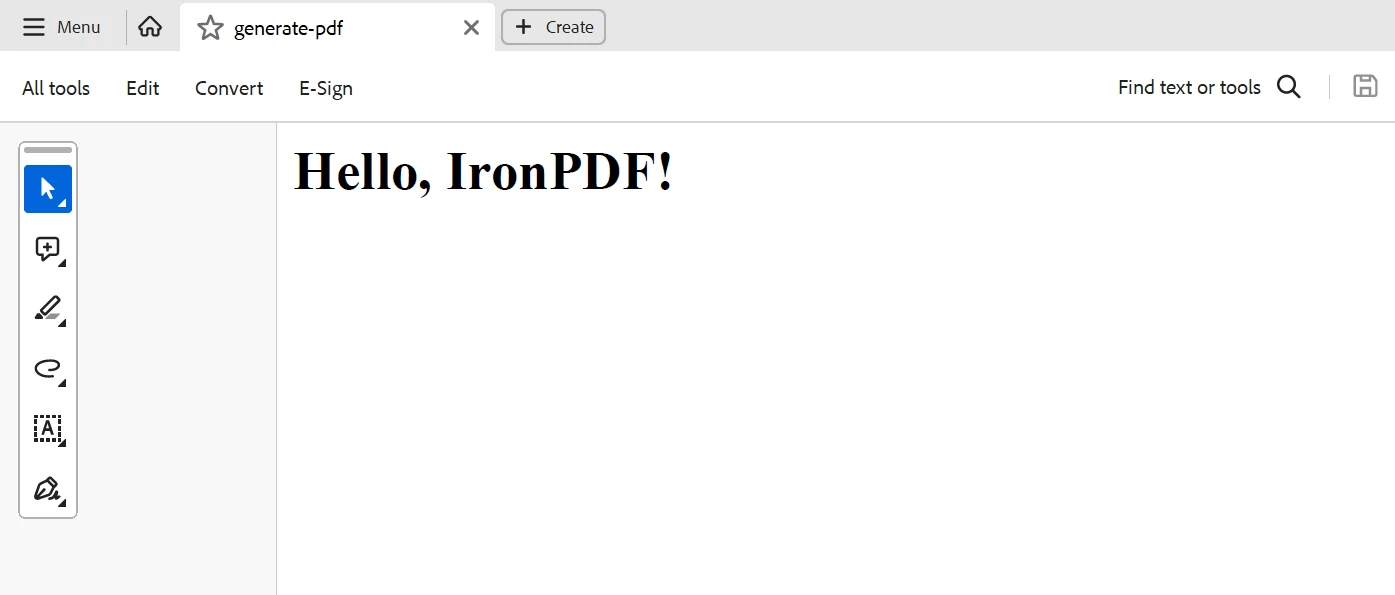
const htmlContent = '<html><body><h1>Hello, IronPDF!</h1></body></html>';
// Generate PDF from HTML
const pdf = await IronPdf.PdfDocument.fromHtml(htmlContent);
// Get the PDF as a Buffer
const pdfBuffer = await pdf.saveAsBuffer();
// Return the PDF buffer to serve as a downloadable file
return pdfBuffer;
}
}报告实例的创建和PDF生成由ReportController处理。 使用IronPDF将HTML内容转换为PDF缓冲区,并通过generatePdf方法返回。 要将HTML渲染为PDF,generatePdf函数使用IronPDF。 LoopBack 控制器轻松处理此集成。 通过定义/generate-pdf接收来自客户端的HTML内容。 我们在端点内使用 IronPDF 库,将提供的 HTML 信息转换为 PDF。
具体来说,我们使用pdf.saveAsBuffer()生成PDF文件的二进制缓冲区,并使用application/pdf)。 在创建 PDF 时遇到的任何问题都由在 3000 端口监听的服务器检测到并记录。客户端收到的响应是 500 状态码。 这个配置使得从 HTML 内容创建动态 PDF 成为可能,这在为 Web 应用程序创建账单、报告或其他文档时很有用。
结论
最后,将 IronPDF 与 LoopBack 4 的整合为在线应用程序开发提供了一个强大的组合。 使用 LoopBack 4,开发人员可以轻松创建 RESTful API,提供一个强大的框架,使他们可以集中精力于业务逻辑,而不是样板代码。 而 IronPDF 则提供了流畅的 PDF 生成功能,使从 HTML 文本创建动态 PDF 文档成为可能。
此外,LoopBack 4 和 IronPDF 的灵活性和易用性简化了开发流程,使开发人员能够快速制作高质量的应用程序。 由于 LoopBack 4 负责 API 后端访问控制,而 IronPDF 处理 PDF 创建,开发人员可以集中精力于满足业务需求并提供出色的用户体验。
通过将 IronPDF 和< a href="Iron Suite">其他八个库 集成到您的开发栈中,我们可以为客户和终端用户保证功能丰富的高端软件解决方案。 此外,这个强大的基础将优化流程、后端系统和项目。 从每个$799开始,这些技术因其详尽的文档、生机勃勃的在线开发者社区和频繁的更新而非常适合当代软件开发项目。