xml2js npm(开发者如何使用)
开发人员可以通过在Node.js中将XML2JS与IronPDF结合使用,轻松将XML数据解析和PDF创建功能集成到他们的应用程序中。 作为一个受欢迎的Node.js包,XML2JS使将XML数据转化为JavaScript对象变得容易,便于对XML内容进行编程式操作和使用。 反之,IronPDF专注于从HTML生成高质量的PDF文档,可调整页面大小、边距和页眉,包括动态创建的内容。
开发人员现在可以使用XML2JS和IronPDF,从XML数据源动态创建PDF报告、发票或其他可打印材料。 为了在Node.js应用程序中自动化文档生成流程,并确保在管理基于XML的数据用于PDF输出时的准确性和灵活性,此集成利用了两个库的优势。
什么是xml2js?
一个称为XML2JS的Node.js包使解析和创建简单的XML(可扩展标记语言)到JavaScript对象转换器变得更简单。 通过提供解析XML文件或文本并将其转换为结构化JavaScript对象的方法,它使处理XML文档变得更轻松。 此过程通过提供仅管理XML属性、文本内容、命名空间、合并属性或键入属性以及其他XML特定特征的选项,为应用程序赋予了解释和使用XML数据的自由。
该库可以处理大型XML文档或需要非阻塞解析的情况,因为它支持同步和异步解析操作。 此外,XML2JS提供了在将XML转换为JavaScript对象期间验证和解决错误的机制,以保证数据处理操作的稳定性和可靠性。 综上所述,Node.js应用程序经常使用XML2JS来集成基于XML的数据源、配置软件、改变数据格式以及简化自动化测试过程。
由于以下功能,XML2JS是处理Node.js应用程序中的XML数据的灵活且不可或缺的工具:
XML解析
借助XML2JS,开发人员可以通过简化将XML字符串或文件处理为JavaScript对象的过程,更快速地访问和处理XML数据,使用知名的JavaScript语法。
JavaScript对象转换
凭借其将XML数据顺畅地转换为结构化JavaScript对象的能力,使在JavaScript应用程序中处理XML数据变得简单。
可配置选项
XML2JS提供多种配置选项,允许您改变XML数据解析和转换为JavaScript对象的方式。 这包括管理命名空间、文本内容、属性和其他东西。
双向转换
通过其双向转换能力,实现双向的数据更改,使JavaScript对象能够转变回简单的XML字符串。
异步解析
该库支持异步解析进程,可有效处理大型XML文档,且不会干扰应用程序的事件循环。
错误处理
为了在XML解析和转换过程中处理可能出现的验证问题和解析错误,XML2JS提供了强大的错误处理方法。
与Promises的集成
它很好地与JavaScript Promises集成,使异步代码模式变得更清晰易于处理。
自定义解析钩子
开发人员可以通过创建自定义解析钩子,获得拦截和改变XML解析行为的特殊选项,提高数据处理流程的灵活性。
创建和配置xml2js
要在Node.js应用程序中使用XML2JS,首先需要安装库并进行配置以满足需求。 这是一个详细的安装和创建XML2JS的指南。
安装XML2JS npm
先确保已安装npm和Node.js。可以通过npm安装XML2JS:
npm install xml2jsnpm install xml2jsXML2JS的基本用法
这是一个简单的例子,展示如何使用XML2JS将XML文本解析为JavaScript对象:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
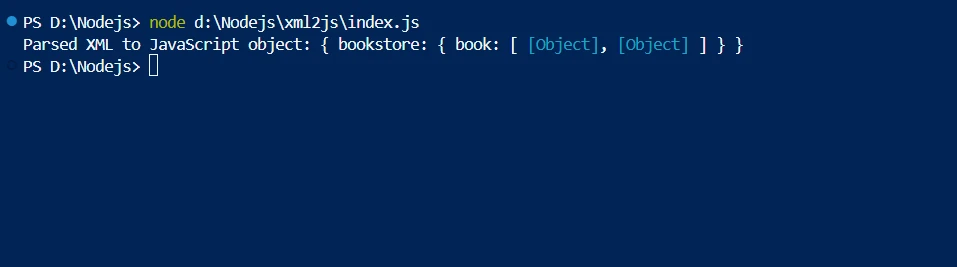
console.log('Parsed XML to JavaScript object:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object:', result);
});
配置选项
XML2JS提供了一系列配置选项和默认设置,让您可以改变解析的行为。 这是一个关于如何为XML2JS设置默认解析设置的例子:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});处理异步解析
XML2JS 支持异步解析,这对于管理大型XML文档而不阻塞事件循环非常有用。这里是一个关于如何使用async/await语法的例子:
const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);开始
在Node.js应用程序中使用IronPDF和XML2JS,首先必须读取XML数据,然后从处理后的内容创建PDF文档。 这是一个详细的教程,将帮助您安装和配置这些库。
什么是 IronPDF?
IronPDF库是一个强大的Node.js库,用于处理PDF。 它旨在将HTML内容转换为质量卓越的PDF文档。 它简化了将HTML、CSS和其他JavaScript文件转为格式良好的PDF的过程,而不会破坏原始的在线内容。 这对需要生成动态、可打印文件(如发票、认证和报告)的web应用程序非常有帮助。
IronPDF具有多种功能,包括可自定义的页面设置、页眉、页脚,以及插入字体和图像的能力。 它支持复杂的布局和样式,以确保所有测试输出的PDF符合指定的设计。 此外,IronPDF控制HTML内的JavaScript执行,允许动态和互动内容的准确渲染。
IronPDF的功能
从 HTML 生成 PDF
将HTML、CSS和JavaScript转换为PDF。 支持两个现代 Web 标准:媒体查询和响应式设计。 适合使用HTML和CSS动态装饰PDF发票、报告和文件。
PDF 编辑
可以在现有的 PDF 添加文本、图像和其他材料。 从PDF文件中提取文本和图像。 将多个PDF合并为一个文件。将PDF文件分割成几个独立的文件。 添加页眉、页脚、注释和水印。
性能和可靠性
在工业环境下,高性能和可靠性是可取的设计属性。 轻松处理大型文档集。
安装IronPDF
要在Node.js项目中获得处理PDF的工具,安装IronPDF包。
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdf解析XML和生成PDF
举例来说,让我们生成一个名为example.xml的基本XML文件:
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>创建generatePdf.js Node.js脚本,该脚本读取XML文件,使用XML2JS将其解析为JavaScript对象,然后使用IronPDF从解析数据的结果对象创建PDF。
// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
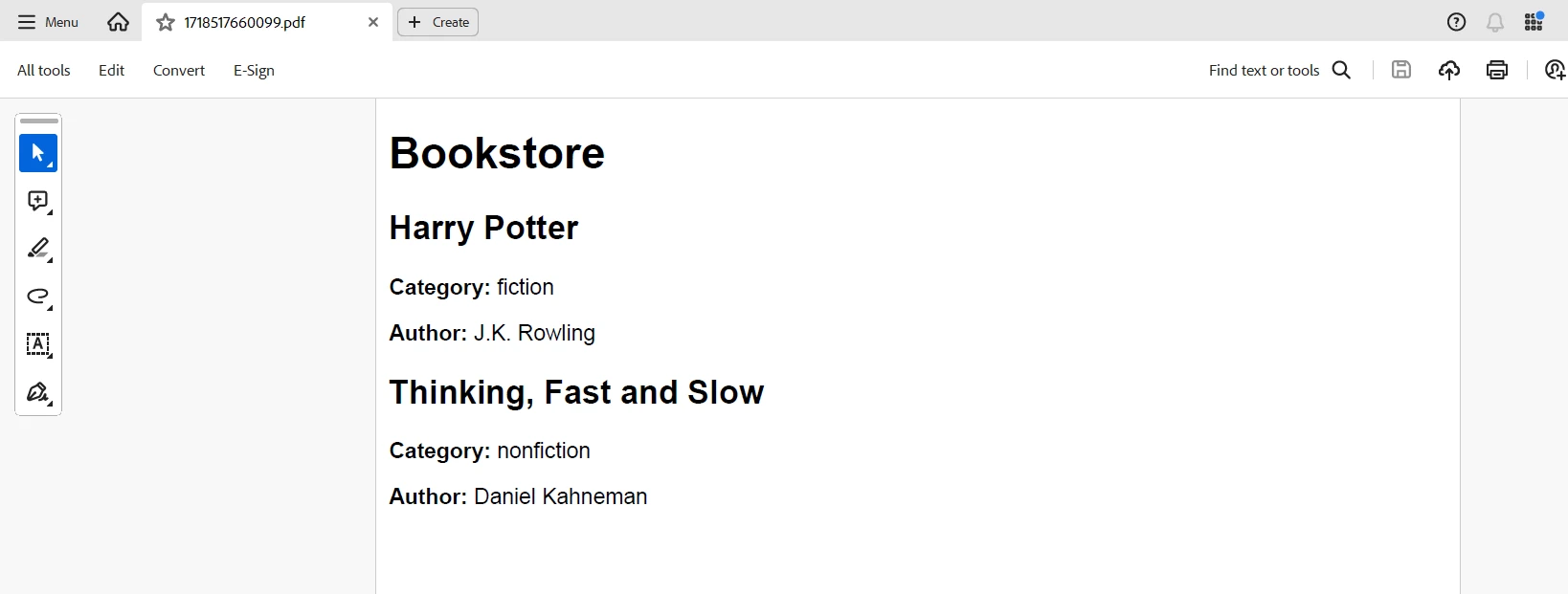
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
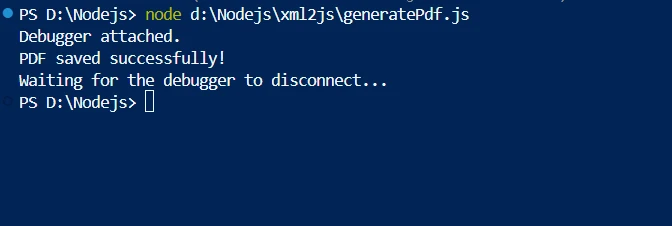
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();在Node.js应用程序中结合IronPDF和XML2JS,可轻松将XML数据转换并解析多个文件为PDF文档。 使用XML2JS,XML文件先使用Node.js的fs模块读取后,其XML内容被解析为JavaScript对象。 随后,使用处理过的数据动态生成PDF基础的HTML文本。
脚本首先从文件读取XML文本,并使用xml2js将其解析为JavaScript对象。 从解析的数据对象中,定制函数创建HTML内容,使用所需的元素进行结构化,例如书店的作者和标题。 随后,这个HTML用IronPDF渲染为PDF缓冲区。 生产的PDF然后被保存到文件系统。
利用IronPDF的高效HTML到PDF转换和XML2JS的强大XML解析能力,此方法提供了一种从Node.js应用程序中的XML数据创建PDF的简化方式。 这种关联使得能够将动态XML数据转换为可打印和格式良好的PDF文档。 这使得它非常适合需要从XML来源自动化生成文档的应用程序。
结论
总而言之,XML2JS和IronPDF在Node.js应用程序中共同提供了一种强大且灵活的方法来将XML数据转为高质量的PDF文文件。 使用XML2JS有效地将XML解析为JavaScript对象,使数据提取和操作变得简单。 在解析数据后,它可以动态变为HTML文本,然后IronPDF很容易将其转换为格式良好的PDF文件。
对于需要从XML数据源自动创建报告、发票和认证等文档的应用程序,这个组合特别有用。 通过利用两个库的优势,开发人员可以确保PDF输出的准确性和美观性,简化工作流程,并提升Node.js应用程序处理文件生成任务的能力。
IronPDF 提供了更多的功能并提高了开发效率,同时利用Iron Software的高度灵活的系统和套件。
当许可选项明确且具体到项目时,开发人员更容易选择最佳模型。 这些功能使开发人员能够以易于使用、高效和一致的方式解决各种问题。