
Dask Python(开发人员如何使用)
Python 是进行数据分析和机器学习的强大语言,但是处理大型数据集对于数据分析来说可能具有挑战性。 这就是 Dask 派上用场的地方。 Dask 是一个开源库,提供高级并行化用于分析,能够在超出单机内存容量的大数据集上进行高效计算。在本文中,我们将研究 Dask 库的基本用法,以及另一个非常有趣的 PDF 生成库,名为 IronPDF,由 Iron Software提供,用于生成 PDF 文档。
为什么使用 Dask?
Dask 旨在将您的 Python 代码从单台笔记本扩展到大型集群。 它与流行的 Python 库,如 NumPy、pandas 和 scikit-learn,无缝集成,实现并行执行而无需显著的代码更改。
Dask 的关键特性
1.并行计算: Dask 允许您同时执行多个任务,从而显著加快计算速度。 2.可扩展性:它可以将大于内存的数据集分成更小的块并并行处理,从而处理这些数据集。 3.兼容性:与现有的 Python 库配合良好,可以轻松集成到您当前的工作流程中。 4.灵活性:提供高级集合,如 Dask DataFrame、任务图、Dask Array、Dask Cluster 和 Dask Bag,分别模拟 pandas、NumPy 和列表。
开始使用 Dask
安装
您可以使用 pip 安装 Dask:
pip install dask[complete]pip install dask[complete]基本用法
这是一个简单的示例,展示 Dask 如何并行化计算:
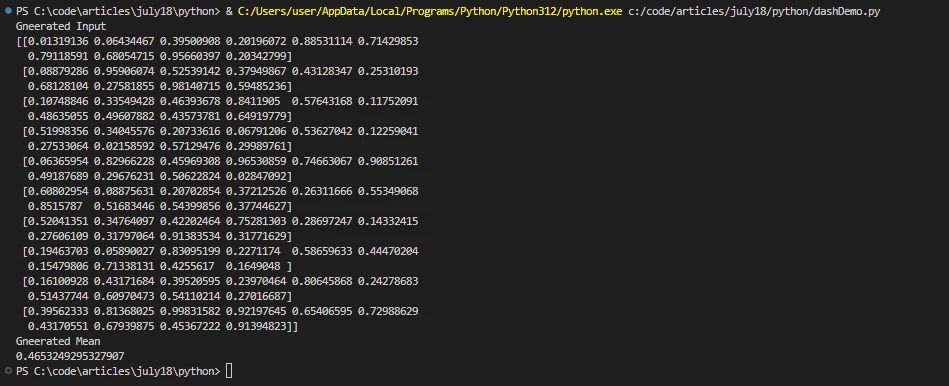
import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)import dask.array as da
# Create a large Dask array
x = da.random.random((10, 10), chunks=(10, 10))
print('Generated Input')
print(x.compute())
# Perform a computation
result = x.mean().compute()
print('Generated Mean')
print(result)在此示例中,Dask 创建一个大数组并将其分解为更小的块。 方法compute()触发并行计算并返回结果。 任务图在内部用于实现 Python Dask 中的并行计算。
输出
Dask DataFrame
Dask DataFrame 类似于 pandas DataFrame,但旨在处理大于内存的数据集。 以下是一个例子:
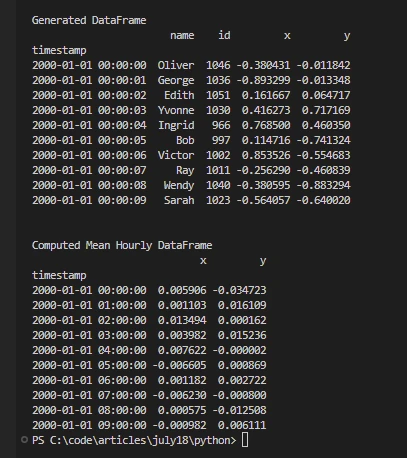
import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))import dask
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute mean hourly resampled DataFrame
print('\nComputed Mean Hourly DataFrame')
print(df[["x", "y"]].resample("1h").mean().head(10))代码展示了 Dask 处理时间序列数据、生成合成数据集并通过利用其并行处理能力以多个 Python 进程、分布式调度程序和多核计算资源进行聚合计算(如每小时平均值)的能力。
输出
最佳实践
1.从小规模开始:先从小数据集入手,了解 Dask 的工作原理,然后再逐步扩大规模。 2.使用仪表盘: Dask 提供了一个仪表盘来监控计算的进度和性能。 3.优化块大小:选择合适的块大小,以平衡内存使用和计算速度。
IronPDF 简介
IronPDF 是一个强大的 Python 库,旨在使用 HTML、CSS、图像和 JavaScript 创建、编辑和签署 PDF 文档。 它强调性能效率,同时最小化内存使用。 关键特性包括:
- HTML 转 PDF 转换:利用 Chrome 的 PDF 渲染功能,轻松将 HTML 文件、字符串和 URL 转换为 PDF 文档。 *跨平台支持:*可在 Windows、Mac、Linux 和各种云平台上的 Python 3+ 无缝运行。 它也与 .NET、Java、Python 和 Node.js 环境兼容。 编辑和签名:自定义 PDF 属性,应用密码和权限等安全措施,并无缝添加数字签名。 页面模板和设置:通过页眉、页脚、页码、可调节边距、自定义纸张尺寸和响应式设计来定制 PDF 布局。 标准符合性:**严格遵守 PDF/A 和 PDF/UA 等 PDF 标准,确保与 UTF-8 字符编码兼容。 还支持高效管理图像、CSS 样式表和字体等资产。
安装
pip install ironpdf
pip install daskpip install ironpdf
pip install dask使用 IronPDF 和 Dask 生成 PDF 文档
前提条件
- 确保安装了 Visual Studio Code。
- 安装了Python版本3。
首先,让我们创建一个Python文件以添加我们的脚本。
打开Visual Studio Code并创建文件,daskDemo.py。
安装所需的库:
pip install dask
pip install ironpdfpip install dask
pip install ironpdf然后添加以下 Python 代码,以演示 IronPDF 和 Dask Python 包的用法:
import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
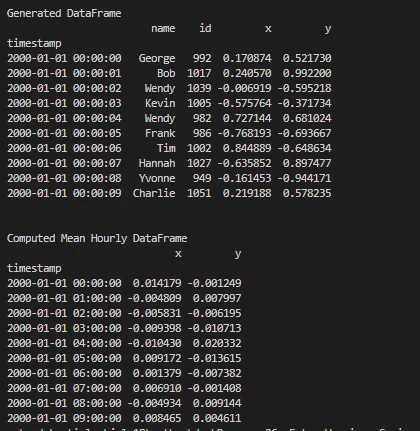
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")import dask
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"
# Generate a synthetic timeseries DataFrame
df = dask.datasets.timeseries()
print('\nGenerated DataFrame')
print(df.head(10))
# Compute the mean hourly DataFrame
dfmean = df[["x", "y"]].resample("1h").mean().head(10)
print('\nComputed Mean Hourly DataFrame')
print(dfmean)
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Create HTML content for the PDF
content = "<h1>Awesome Iron PDF with Dask</h1>"
# Add generated DataFrame to the content
content += "<h2>Generated DataFrame (First 10)</h2>"
rows = df.head(10)
for i in range(10):
row = rows.iloc[i]
content += f"<p>{str(row[0])}, {str(row[2])}, {str(row[3])}</p>"
# Add computed mean DataFrame to the content
content += "<h2>Computed Mean Hourly DataFrame (First 10)</h2>"
for i in range(10):
row = dfmean.iloc[i]
content += f"<p>{str(row[0])}</p>"
# Render the HTML content as PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Save the PDF to a file
pdf.SaveAs("DemoIronPDF-Dask.pdf")代码解释
此代码片段集成了 Dask 用于数据处理和 IronPDF 用于 PDF 生成。 它展示了:
- Dask集成:使用
dask.datasets.timeseries()生成合成时间序列DataFrame (df)。 打印前10行(dfmean)。 - IronPDF使用:使用
License.LicenseKey设置IronPDF许可证密钥。 创建包含生成和计算的DataFrames的标题和数据的HTML字符串(pdf),最终保存PDF为"DemoIronPDF-Dask.pdf"。
此代码结合了 Dask 在大规模数据操作方面的能力和 IronPDF 将 HTML 内容转换为 PDF 文档的功能。
输出

IronPDF 许可证
IronPDF 许可证密钥允许用户在购买前查看其广泛功能。
在使用IronPDF包之前,将许可证密钥放在脚本开头:
from ironpdf import *
# Apply your license key
License.LicenseKey = "key"from ironpdf import *
# Apply your license key
License.LicenseKey = "key"结论
Dask 是一个多用途的工具,可以显著增强您在 Python 中的数据处理能力。 通过启用并行和分布式计算,它允许您高效地处理大型数据集,并无缝集成到您现有的 Python 生态系统中。 IronPDF 是一个功能强大的 Python 库,用于使用 HTML、CSS、图像和 JavaScript 创建和操作 PDF 文档。 它提供 HTML 到 PDF 的转换、PDF 编辑、数字签名以及跨平台支持等功能,使其适用于 Python 应用程序中的各种文档生成和管理任务。
这两个库结合起来,允许数据科学家执行高级数据分析和科学操作,然后使用 IronPDF 将输出结果存储为标准 PDF 格式。
















