
HTTPX Python(如何运作:开发人员指南)
HTTPX 是一个现代的、功能齐全的 Python HTTP 客户端,具有同步和异步 API。这款库在处理HTTP请求时提供了高效率。 该库的几个功能扩展了传统库,如 Requests; 因此,它更加强大,因为支持 HTTP/2、连接池和 cookie 管理。
结合使用 IronPDF,一个全面的 .NET 库,用于创建和编辑所有 PDF 文档,HTTPX 可以从 web API 或甚至网站获取数据,并将这些数据转化为长篇的、格式优美的 PDF 报告。 借助 IronPDF 生成从 HTML、图像、简单文本到高级功能,例如添加页眉、页脚和水印的能力,可以制作出专业而美观的文档。 集成是完整的:从数据检索到报告制作,提供了一种以精美形式传达见解的高效方式。
什么是 Httpx python?
HTTPX 是一个现代的下一代 Python HTTP 客户端,它借鉴了一些使用流行 Requests 库的巧妙方式,并与同步和异步 API 支持结合在一起。 它通过不同的高级功能,如 HTTP/2 支持、连接池,甚至自动 cookie 管理来解决复杂的 HTTP 任务。 HTTPX 使开发人员能够同时发送多个不同的 HTTP 请求,加速应用程序的性能,尤其是网络交互是主要预期功能的情况下。
它提供了与 Requests 库的出色互操作性,为希望升级其 HTTP 客户端并访问更复杂功能的开发人员提供了简便的升级路径。 HTTPX 是现代 Python 开发的灵活工具; 它非常适合从简单的 HTTP 查询到更复杂和性能关键的网络交互任务。 HTTPX 可以在支持 socks 代理连接的情况下执行同步和异步请求。
Httpx python 的功能
Python 中的 HTTPX 提供了最有价值的功能,扩展和增强了 HTTP 请求处理。 以下是其一些关键功能:
同步和异步 API:
支持同步和异步请求处理。 开发人员可以根据需要在应用程序中应用任何可用选项。
HTTP/2 支持:
该框架对 HTTP/2 协议提供原生支持,与支持该协议的服务器进行更快和更高效的通信。
连接池:
智能 HTTP 连接:重用已建立的连接和连接池会话,以减少延迟和提高处理多请求的速度。
自动内容解码:
它可以自动解码通常以 gzip 编码的压缩响应,使其更容易处理并减少带宽。
超时和重试:
定义请求超时设置,确保在请求超时后非阻塞请求 - 额外的重试机制以处理瞬时故障。
Websockets 支持:
支持 WebSocket 连接,使客户端和服务器之间可以通过单个长时间连接进行双向通信。
代理支持:
内置了对 HTTP 代理的支持。 这将允许通过中介服务器发出请求,以实现隐私或网络管理。
Cookie 处理:
该库将处理 cookies,跟踪请求之间的会话状态。
客户端证书:
支持客户端证书,为使用共同 TLS 身份验证的服务器提供安全通信。
中间件和钩子:
允许通过中间件和钩子自定义请求和响应处理。 这为开发人员根据需求扩展 HTTPX 功能提供了出色的可扩展性。 Requests 兼容性:它被设计为使用 Requests API,使得来自 Requests 的开发人员非常容易转向 HTTPX 项目并获得许多新的杰出特性和改进。
创建和配置 Httpx python
首先,您必须安装库,并设置环境以在 Python 中配置 HTTPX。 HTTPX 项目依赖于 HTTP 核心和异步库自动检测作为依赖项,但它们在安装 HTTPX 项目时应该直接安装。 HTTPX 还有一个变体,作为命令行客户端支持,附带丰富的终端支持; 然而,在本文中,我们将严格专注于 HTTPX python。 下方指南展示了一个简单的 HTTP GET 请求的例子。有关更全面的 API 参考,请访问 HTTPX 文档此处。
安装 HTTPX
首先,确保您已安装 HTTPX。 您可以使用命令行客户端进行安装:
pip install httpxpip install httpx导入 HTTPX 并进行基本请求
安装后,您可以导入 HTTPX 并如下发送一个简单的 HTTP GET 请求:
import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")import httpx
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
# Create a client instance to manage HTTP requests
response = httpx.get(url)
# Print response HTTP status codes and content
print(f"Status Code: {response.status_code}")
# Print Unicode Response Bodies
print(f"Response Content: {response.text}")- 使用内部异步上下文管理器的 fetch_data 函数打开 HTTP 客户端,向给定 URL 发出 GET 请求。
- 存储
httpx.get(url)返回的HTTP响应对象。
在 HTTPX 中设置高级功能
HTTPX 的高级功能支持其他配置范围广泛,如处理代理、头信息和超时。 以下是如何使用更多选项设置 HTTPX:
import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")import httpx
def fetch_data_with_config(url):
# Create a client with a timeout and custom headers
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Print response status code and content
print(f"Status Code: {response.status_code}")
print(f"Response Content: {response.json()}")-超时:将 HTTP 请求的超时时间设置为 30 秒。 这是为了防止请求无限期阻塞。
- 它向请求
User-Agent头,以识别客户端应用程序。 - response.json() - 将响应内容解析为 JSON,假如响应中包含 JSON 数据。

开始
使用 HTTPX 和 Python 的 IronPDF 来生成 PDF。 首先,您需要配置 HTTPX 从某个来源获取数据,然后 IronPDF 将根据获取的数据创建 PDF 报告。 以下是如何详细完成的:
什么是 IronPDF?
强大且健壮的 Python 库 IronPDF 能够生成、编辑和读取 PDF。 它允许程序员对 PDF 执行许多基于编程的操作,例如编辑现有的 PDF 文档和将 HTML 文件转换为 PDF。 IronPDF 使在 PDF 格式中生成高质量报告更加简单和灵活。 因此,这使得在动态创建和处理 PDF 的应用程序中具有实用性。
HTML 至 PDF 转换
IronPDF 能够将任何 HTML 数据转换为 PDF 文档,无论其年代。 这允许从 web 内容创建精美艺术化的 PDF 出版物,充分利用 HTML5、CSS3 和 JavaScript 的现代功能。
创建和编辑 PDF
通过编程语言,可以生成包含文本、图片、表格和其他内容的新 PDF 文档。 IronPDF 还可以打开和修改预先存在的 PDF 文档以进行额外的自定义。 可以随意添加、更改或删除 PDF 文档中包含的任何内容。
复杂的设计和样式
这是通过 CSS 实现的 PDF 内容样式来实现的,CSS 可以处理带有各种字体、颜色和其他设计元素的复杂布局。 此外,处理 PDF 中的动态内容时确保在 JavaScript 下进行渲染 HTML 内容。
安装 IronPDF
IronPDF 可以用 pip 安装。安装命令如下:
pip install ironpdfpip install ironpdf将 httpx 和 IronPDF for Python结合使用
使用 HTTPX 从 API 或网站获取数据。以下示例展示如何从伪 API 中以 JSON 格式检索数据。
import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
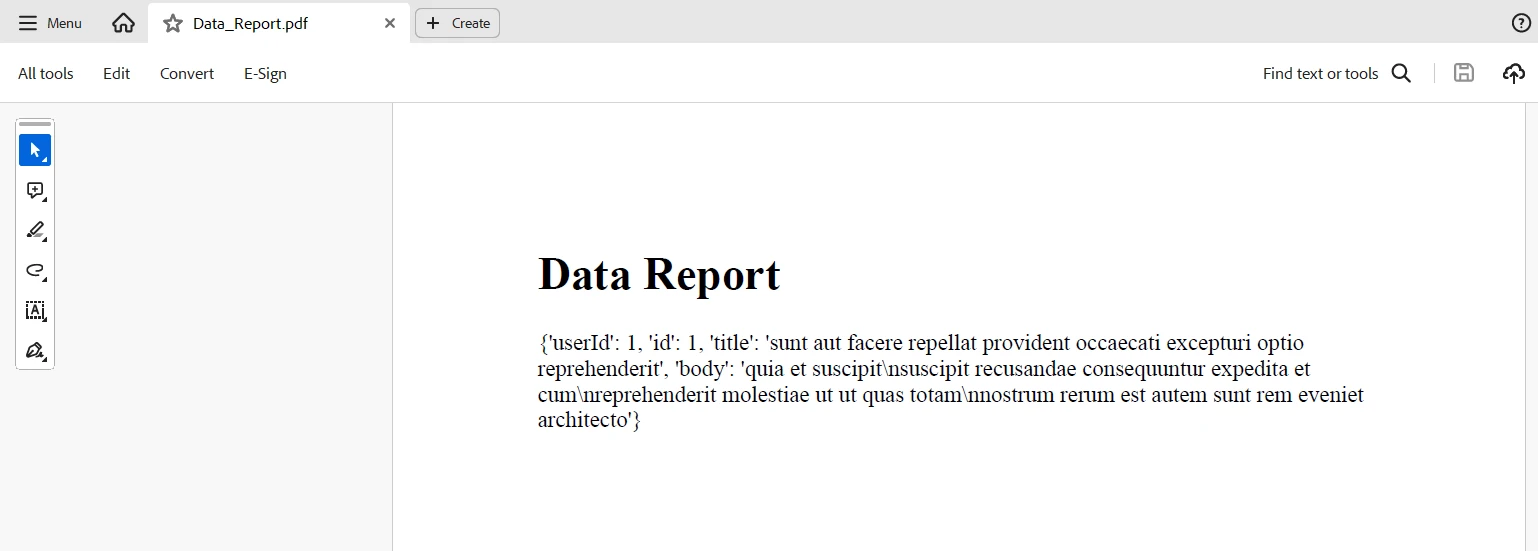
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")import httpx
from ironpdf import ChromePdfRenderer
# Set your IronPDF license key
License.LicenseKey = ""
def fetch_data_with_config(url):
# Create an HTTPX client with added configurations
with httpx.Client(timeout=30, headers={"User-Agent": "MyApp/1.0"}) as client:
response = client.get(url)
return response
# Example usage
url = 'https://jsonplaceholder.typicode.com/posts/1'
response = fetch_data_with_config(url)
# Create a PDF document renderer
iron_pdf = ChromePdfRenderer()
# Create HTML content from fetched data
html_content = f"""
<html>
<head><title>Data Report</title></head>
<body>
<h1>Data Report</h1>
<p>{response.json()}</p>
</body>
</html>"""
# Render the HTML content as a PDF
pdf = iron_pdf.RenderHtmlAsPdf(html_content)
# Save the PDF document
pdf.SaveAs("Data_Report.pdf")
print("PDF document generated successfully.")- 这是设计为使用 HTTPX 同步地从 web API 或网站中获取数据。 这是一个实用的库,因为它准备好了同步和异步操作,同时处理不同的 HTTP 请求。 一个示例是点击返回 JSON 数据的模拟 API 端点。
- IronPDF 通过 Python 使用; 一个以 .NET 引擎委托生成上面提到的获取数据的 PDF 报告。 IronPDF 可以从 HTML 内容生成 PDF,并将此数据转换为结构化文档。
- IronPDF 集成:Python 允许您与 IronPDF 互动。 这将导致开发一个基于动态生成HTML内容 (
html_content) 的PDF文档 (pdf)。 数据通过 HTTPX 获取。 此 HTML 内容将基于动态获取的数据; 因此,可以获得个性化和实时的报告。
结论
此 HTTPX 与 IronPDF 的集成将您的 Python 应用程序结合两大功能:数据获取和专业级 PDF 生成。 这意味着 HTTPX 对于通过 web API 或网站获取数据非常适合,因为它支持异步和同步风格来处理 HTTP 请求。 另一方面,IronPDF 通过 Python .NET 互操作,从获取的数据中生成精美的专业级 PDF 报告变得容易,从而装饰了数据见解的可视化和传递。
它帮助从数据获取到撰写报告一切,提供灵活性以处理不同数据源和格式。 它使开发人员能够生成详细的 PDF,用于演示或文档,甚至存档所有数据分析结果。 所有这些实用程序和 Python 应用程序将把原始数据转换为专业格式的报告,确保任何选择领域的生产力和决策制定。
集成 IronPDF 和 Iron Software 产品,为您的客户及其用户提供丰富的高端软件解决方案。 这将简化项目运营和程序。
除了所有基本功能外,IronPDF 还拥有完整的文档、活跃的社区和频繁的更新。 基于此信息,Iron Software 是现代软件开发项目的可靠合作伙伴。 开发人员可以尝试 IronPDF 免费试用以审查其所有功能。 随后,许可证从$799开始并向上。
















