
PDFtoText in Python: 一个逐步教程
PDF 文件是最受欢迎的数字文档格式之一。 它们因其在不同系统中的兼容性和能够保持复杂文档格式的能力而受到青睐。
在数据管理中,将 PDF 文档转换为可编辑格式或提取文本进行分析是非常宝贵的。 此转换过程使企业和个人能够挖掘和利用静态文档中原本封锁的数据。
Python 凭借其广泛的库生态系统,提供了一种可访问且强大的方法来操作 PDF 文件。 无论是提取数据、转换 PDF 文件,还是自动化生成报表,Python 的简洁性和丰富的工具使其成为 PDF 处理任务的首选语言。
什么是 IronPDF?
IronPDF 是一个全面的 Python 开发者 PDF 渲染库,以促进与 PDF 文件的交互。 它提供了一套强大的工具,允许在 Python 编程环境内创建、操作和转换 PDF 文档。
IronPDF 架起了 Python 脚本的简易性与 PDF 处理所需的文档管理功能之间的桥梁,从而使开发者能够直接将 PDF 功能集成到他们的应用程序中。
系统要求和安装指南
在安装 IronPDF 之前,确保您的系统符合以下要求:
- 系统上安装了 Python 3.x。
- 使用 pip(Python 包安装器)进行便捷安装的途径。
- 如果您在 Windows 系统上运行,需要 .NET Framework,因为 IronPDF 依赖于 .NET 来运行。
一旦确认您的系统满足这些要求,您可以使用 pip 安装 IronPDF。打开命令行或终端并运行以下命令:
pip install ironpdf
请确保您使用的是最新版本的 IronPDF for Python 库。 此命令将在您的 Python 环境中下载并安装 IronPDF 库及所有必需的依赖项。
将 PDF 转换为文本:分步教程
步骤 1:导入 IronPDF
from ironpdf import *from ironpdf import *此代码片段以一个 import 语句开始,将 IronPDF 库中的所有必要组件引入到您的 Python 脚本中。 这对于访问 IronPDF 提供的允许您处理 PDF 文件的类和方法至关重要。
步骤 2:设置日志记录
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.AllLogger.EnableDebugging = True:启用IronPDF库中的调试功能以跟踪操作,这对于故障排除至关重要。
Logger.LogFilePath = "Custom.log":指定调试信息将写入的日志文件的路径和名称。 确保目录可写。
- Logger.LoggingMode = Logger.LoggingModes.All:设置日志模式以记录所有事件,包括信息级日志、警告和错误。 这种全面的日志记录有助于调试。
步骤 3:加载 PDF 文档
# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")# Load an existing PDF document
pdf = PdfDocument.FromFile("content.pdf")PdfDocument.FromFile("content.pdf"):通过创建PdfDocument对象将名为"content.pdf"的 PDF 文件加载到环境中。
- pdf 变量现在保存您的 PDF 文档,并允许您执行各种操作。
步骤 4:从整个文档中提取文本
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)pdf.ExtractAllText():从文档中提取所有文本内容。 然后文本存储在变量 all_text 中。
- print(all_text):将提取的文本打印到控制台,验证文本提取过程。
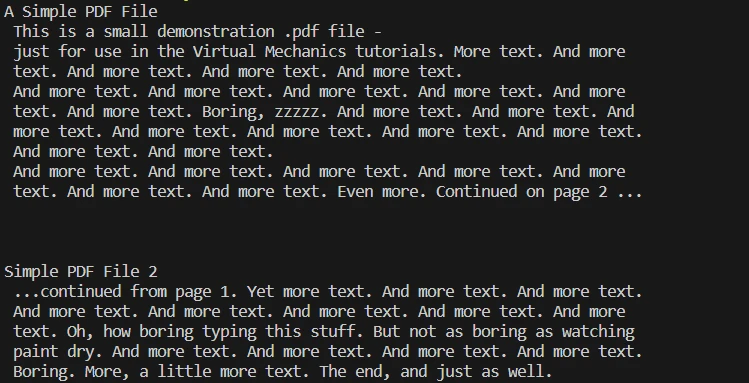
步骤 5:从特定页面提取文本
# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)# Load an existing PDF document (already loaded, but shown for clarity)
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Print the extracted text from the specific page
print(page_text)PdfDocument.FromFile("content.pdf"):演示了提取文本需要 PDF 文件对象( PdfDocument对象)。 如果文档已在连续脚本中加载,此行就没有必要。
pdf.ExtractTextFromPage(1):从 PDF 的第二页(索引 1)提取文本。
- 示例假设您将打印提取的文本以验证操作:print(page_text)。
本教程为开发者提供了一个明确的路径,通过在 Python 中使用 IronPDF 库将 PDF 文件的内容转换为文本,无论您是需要处理整个文档还是仅仅是单个页面。
完整代码片段
这是您可以使用的完整代码:
from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import *
# Add your License key here
License.LicenseKey = "License-Code"
# Enable debugging for IronPDF
Logger.EnableDebugging = True
# Specify the log file path
Logger.LogFilePath = "Custom.log"
# Set logging mode to log all events
Logger.LoggingMode = Logger.LoggingModes.All
# Load an existing PDF document
pdf = PdfDocument.FromFile("sample.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)PDF 文件的高级功能
将 PDF 文件转换为其他格式
IronPDF 不仅处理文本提取。 它的一大功能是能够将 PDF 文件转换为其他格式,这对于以不同媒介分享和展示信息特别有用。
打印和管理 PDF 文档
直接从 Python 管理 PDF 文件的打印任务在涉及物理文档时非常有价值。 IronPDF 提供了这一功能,只需几条命令即可简化数字到物理的过程。
处理扫描的 PDF 文件
对于扫描的 PDF 文件,IronPDF 提供了专门的方法来提取文本,这可能是一个具有挑战性的任务,因为内容是图像而不是可选择的文本。 这拓宽了该库在更广泛文档管理任务中的实用性。
PDF 处理技术的演变
PDF 处理技术已经迅速演变,从简单的文本提取到复杂的数据处理和更具交互性的文档操作。 重点正在转向自动化、人工智能和基于云的服务,支持更动态和智能的文档处理解决方案。
IronPDF 很可能会随着这些前沿技术的发展而发展,以保持相关性和强大。
结论:使用 IronPDF 精简您的工作流程
IronPDF 简化了将 PDF 转换为文本的过程,并简化了工作流程,使其对于开发者和企业来说是一个有价值的资源。
IronPDF 因其能够无缝集成到 Python 环境中、从标准和扫描 PDF 中强大的文本提取以及保持原始文档格式的高保真度而脱颖而出。
该库的日志记录和调试功能进一步帮助开发可靠的 PDF 操作应用程序。
在将 PDF 转换为文本后,接下来的步骤包括利用提取的数据。 这可能意味着将文本集成到数据库中,执行数据分析,将其馈送到报表工具中,或用于机器学习。
随着文本数据以更易访问的格式存在,处理和使用此信息的可能性显著扩展,打开了通往新见解和操作效率的大门。
IronPDF 提供 30 天免费试用,让您在承诺之前探索和评估其全部功能。 此试用期是开发者亲身体验 IronPDF 如何简化其 PDF 工作流程的极好机会。
常见问题解答
如何在Python中从PDF中提取文本?
您可以使用IronPDF在Python中从PDF中提取文本。使用PdfDocument.FromFile('filename.pdf')加载PDF文档,并使用pdf.ExtractAllText()提取文本。
使用IronPDF进行PDF处理的优势是什么?
IronPDF提供强大的文本提取、文档操作和转换工具,无缝集成到Python环境中。其高级功能包括处理扫描的PDF和将PDF转换为其他格式。
如何在Python中安装IronPDF?
要安装IronPDF,请确保您已安装Python 3.x和pip。在命令行或终端中运行命令pip install ironpdf。
IronPDF能否处理扫描的PDF文件?
是的,IronPDF具有专门的方法来从扫描的PDF文件中提取文本,支持处理内容为图像形式的文档。
在Python中使用IronPDF的系统要求是什么?
使用IronPDF,您需要Python 3.x、pip(Python包安装器),如果您使用的是Windows系统,还需要.NET框架。
如何使用IronPDF将PDF转换为其他格式?
IronPDF允许您利用其转换方法,将PDF转换为各种格式,提高Python应用程序中的文档管理灵活性。
IronPDF有免费试用版吗?
是的,IronPDF提供30天免费试用,允许开发者在购买前探索和评估其功能。
为什么在使用IronPDF时日志记录很重要?
IronPDF中的日志记录是必不可少的,因为它有助于跟踪操作、排除问题以及记录所有事件,包括信息级日志、警告和错误,有助于调试。
IronPDF如何提升Python中的工作流自动化?
IronPDF通过简化PDF到文本的转换以及实现Python项目的无缝集成来提升工作流自动化,从而提高生产力和运营效率。
















