


Fichero PDF a imagen en Java
Convierte documentos PDF a formatos de imagen como JPEG, PNG o TIFF en Java usando el método toBufferedImages de IronPDF. Carga un archivo PDF, llama a toBufferedImages para obtener una lista de objetos BufferedImage, luego escribe cada imagen en el disco usando ImageIO. Toda la conversión toma menos de diez líneas de código Java funcional.
Inicio rápido: Convertir PDF a imágenes en Java
-
Añada la dependencia IronPDF a su proyecto Maven: ```xml :title=pom.xml
com.ironsoftware ironpdf 2024.9.1 -
Cargue su documento PDF:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));JAVA - Convertir a imágenes y guardar:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }JAVA
Cómo convertir PDF en imagen en Java
- Instalar la biblioteca Java de IronPDF
- Cargar un archivo PDF usando
PdfDocument.fromFile() - Llamar a
toBufferedImages()para obtener unaList - Establecer dimensiones de salida con
ToImageOptionssi es necesario - Escribir cada imagen en disco usando
ImageIO.write()
¿Qué es la conversión de PDF a imagen y por qué es necesaria?
La conversión de PDF a imagen convierte cada página de un documento PDF en un archivo de imagen independiente (JPEG, PNG o TIFF) que se puede mostrar, incrustar o procesar sin un visor de PDF. Las bibliotecas estándar de Java no proporcionan un mecanismo incorporado para esto, lo que lo convierte en un punto de dolor persistente para los desarrolladores que necesitan vistas previas de documentos, generadores de miniaturas o canalizaciones de archivo.
Los usos comunes incluyen generar vistas previas de miniaturas para sistemas de gestión de documentos, producir capturas de pantalla a nivel de página para aplicaciones web y extraer contenido visual para informes o presentaciones. IronPDF maneja toda la complejidad del renderizado internamente, por lo que el código de la aplicación se mantiene corto y la salida es precisa píxel a píxel independientemente de las fuentes, gráficos vectoriales o campos de formulario en el PDF de origen. Para la operación inversa de colocar imágenes en un PDF, consulte la guía de cómo convertir imagen a PDF.
¿Qué es IronPDF for Java y cómo ayuda?
IronPDF for Java es una biblioteca para crear, leer y editar archivos PDF en proyectos basados en Maven. Los desarrolladores lo usan para generar PDFs a partir de HTML, modificar documentos existentes y extraer contenido sin Adobe Acrobat o cualquier visor de PDF instalado en el servidor.
La biblioteca admite encabezados y pies de página personalizados, firmas digitales, creación de formularios, protección por contraseña y renderizado multihilo. Su función de PDF a imagen expone una API clara a través de dos sobrecargas de toBufferedImages: una que convierte cada página con configuraciones por defecto, y otra que acepta un objeto ToImageOptions y un PageSelection para controlar la resolución y el rango de páginas. Para una visión general completa de las funciones, visita la documentación de IronPDF for Java. Para la referencia completa del API, consulta la referencia de API de Java.
Más allá de la conversión básica, IronPDF es compatible con renderizado de HTML a PDF, marcas de agua personalizadas, fondos y primeros planos, y creación de formularios. También envía artefactos de Maven en el repositorio Sonatype Maven Central, por lo que la gestión de dependencias sigue flujos de trabajo estándar de Maven o Gradle.
¿Qué requisitos previos necesito antes de empezar?
Antes de comenzar, confirme que lo siguiente esté en su lugar:
- Java instalado con la ruta configurada en las Variables de Entorno. Consulte la guía de instalación de Java oficial.
- Un IDE de Java instalado; Eclipse o IntelliJ funcionan bien. Descarga Eclipse o IntelliJ IDEA.
- Maven integrado con el IDE. Consulte este tutorial de configuración de Maven para IntelliJ.
- Claves de licencia configuradas antes de implementar en un entorno de producción.
¿Cómo se instala IronPDF for Java?
Una vez que todos los requisitos previos están en su lugar, la instalación es una única declaración de dependencia de Maven. Para los pasos detallados de configuración, consulte la documentación para comenzar.
Abre JetBrains IntelliJ IDEA y crea un nuevo proyecto Maven.
Crear un nuevo proyecto Maven
Aparece una nueva ventana. Introduzca el nombre del proyecto y haga clic en Finalizar.
Nombre del nuevo proyecto
Después de hacer clic en Finalizar, el nuevo proyecto se abre con pom.xml mostrado por defecto. Agrega las siguientes dependencias a ese archivo. La entrada opcional de SLF4J suprime el ruido de los log de desarrollo; elimínalo si tu proyecto ya incluye un framework de registro.
Nuevo Proyecto: pom.xml predeterminado
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>Una vez que las dependencias se añaden a pom.xml, un ícono de sincronización de Maven aparece en la esquina superior derecha del editor.
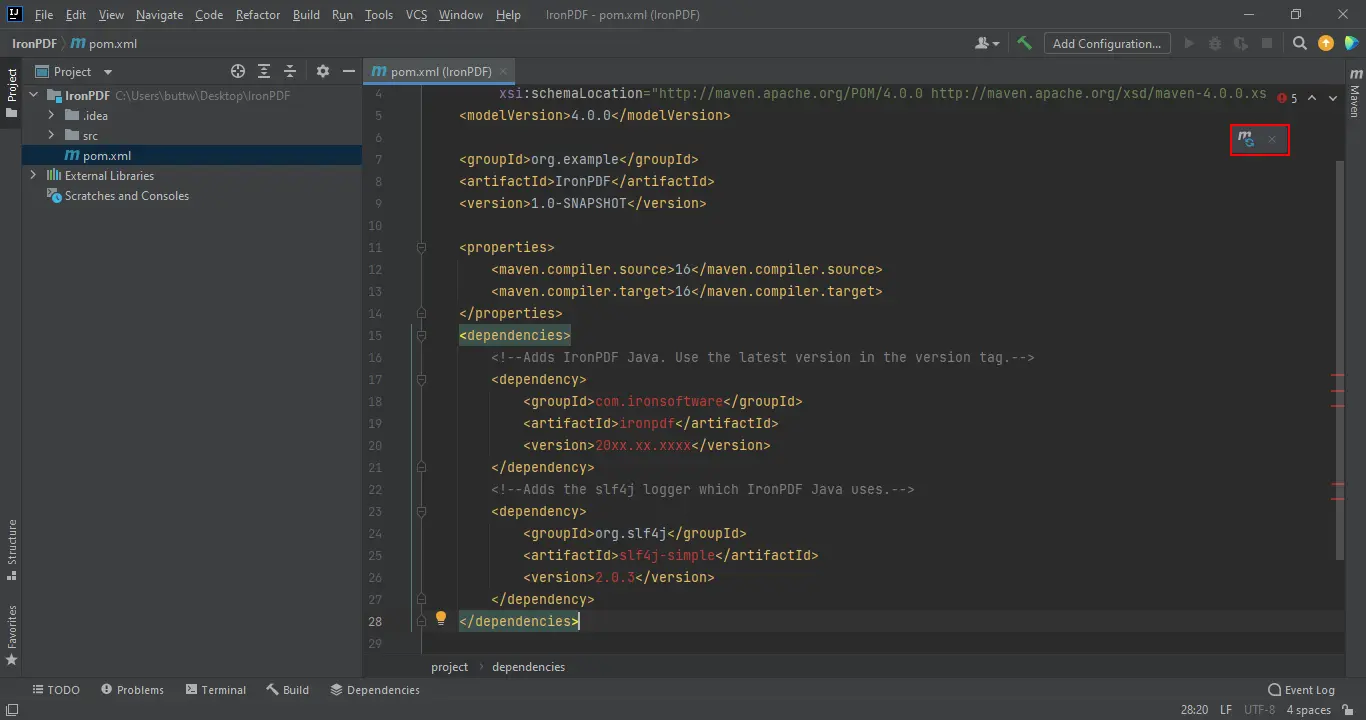
Dependencias de Maven añadidas
Haz clic en el icono de sincronización para descargar el JAR de IronPDF. El tiempo de descarga depende de la velocidad de conexión, generalmente menos de dos minutos. Después de la instalación, revisa la referencia de API de Java para ver todos los métodos y opciones de configuración disponibles. Para los objetivos de implementación en la nube, IronPDF tiene guías probadas para AWS, Azure, y Google Cloud.
¿Cómo convierto archivos PDF en imágenes con IronPDF?
Llamar a toBufferedImages en un objeto PdfDocument produce un List<BufferedImage> donde cada elemento corresponde a una página PDF en orden ascendente por número de página. El resultado puede escribirse en disco, pasarse a una tubería de procesamiento de imágenes, o devolverse directamente a una respuesta web.
IronPDF también convierte URLs y cadenas HTML a PDF en tiempo real, por lo que es posible capturar cualquier página web o documento HTML renderizado como imágenes en una sola tubería sin un paso de renderizado separado.
¿Cómo convierto un documento PDF existente en imágenes?
toBufferedImages acepta un argumento opcional ToImageOptions para controlar las dimensiones de salida y un argumento PageSelection para dirigirse a páginas específicas. Cuando no se pasan argumentos, todas las páginas se convierten a su resolución natural.
El ejemplo a continuación convierte todas las páginas de un PDF a archivos PNG, usando ToImageOptions para limitar cada imagen de salida a 800x500 píxeles:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}Las imágenes resultantes se guardan en assets/images/ con nombres de archivo numéricos empezando en 1. Cree esa carpeta antes de ejecutar el programa, ya que ImageIO.write no crea directorios faltantes. Las llamadas setImageMaxHeight y setImageMaxWidth establecen límites superiores en cada dimensión; IronPDF preserva la relación de aspecto original y no estira la imagen.
ImageIO.write de "PNG" a "JPEG" y actualice la extensión del archivo en consecuencia.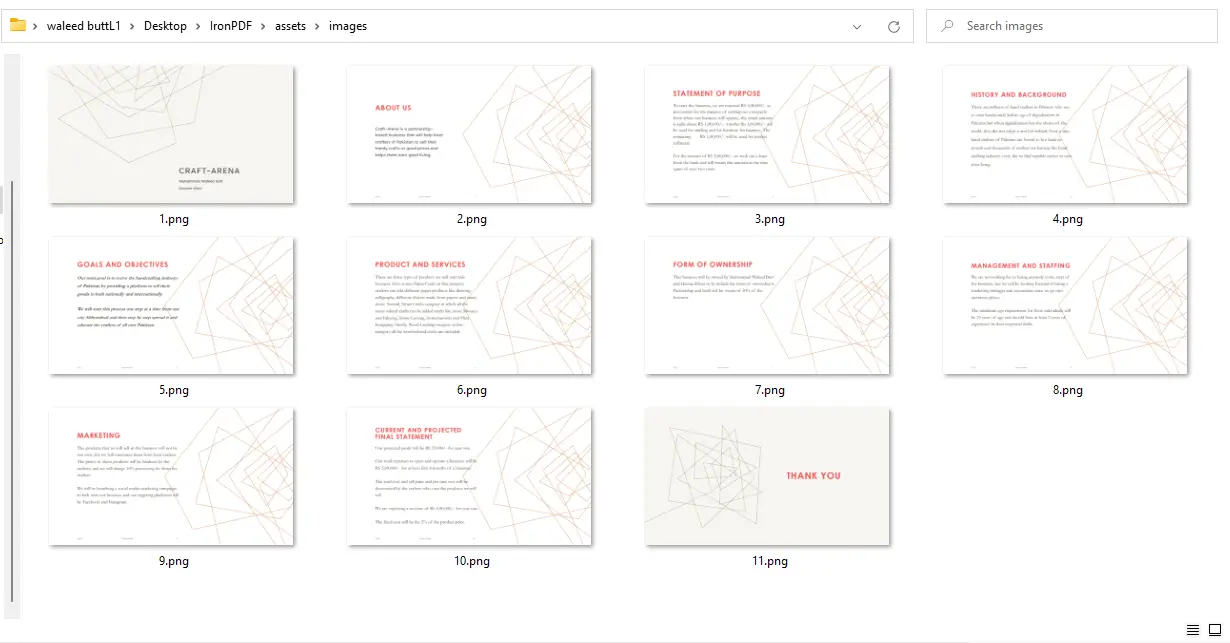
Salida de PDF a Imágenes - 11 archivos PNG, uno por página
Para más ejemplos de conversión, visita la página de ejemplos de rasterización de PDF.
¿Cómo convierto una URL en imágenes usando IronPDF?
PdfDocument.renderUrlAsPdf obtiene la URL, la renderiza con el motor Chromium incorporado y devuelve un PdfDocument que se puede pasar inmediatamente a toBufferedImages. Esto hace que sea sencillo capturar cualquier página web accesible públicamente como una serie de imágenes.
El ejemplo a continuación renderiza una página de producto de Amazon a un PDF y luego guarda cada página resultante como un archivo PNG:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}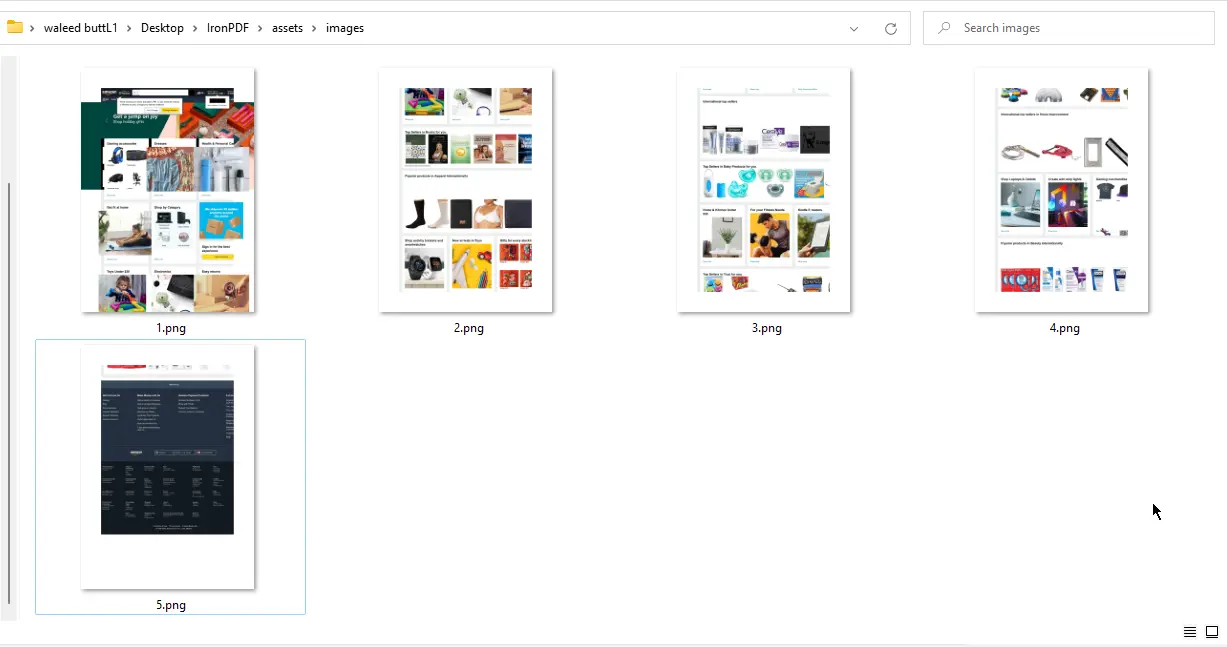
Salida de URL a Imágenes - 5 archivos PNG
Para páginas que requieren autenticación o cookies de sesión antes de renderizar, vea la guía de inicios de sesión en sitios web.
renderUrlAsPdf aplica el mismo soporte de CSS y JavaScript que un navegador de escritorio moderno. Las páginas que dependen de JavaScript del lado del cliente para cargar el contenido se renderizarán correctamente, incluidas las aplicaciones de una sola página.¿Cómo convierto determinadas páginas en imágenes?
PageSelection proporciona varios métodos de fábrica para dirigir un subconjunto de páginas en lugar de todo el documento. Esto es útil cuando solo se necesita extraer una página de portada, una sección de resumen o un rango de páginas conocido.
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}PageSelection.singlePage(0) se dirige solo a la primera página, lo que es útil para generar una miniatura de portada. PageSelection.pageRange(1, 4) extrae las páginas dos a cinco usando índices basados en cero. Ambos devuelven un List<BufferedImage>, por lo que el patrón de bucle es idéntico independientemente de cuántas páginas se seleccionen.
PageSelection están basados en cero: la primera página es 0, la segunda es 1, y así sucesivamente. Pasar un índice fuera de rango lanza un IndexOutOfBoundsException en tiempo de ejecución.¿Cuáles son los siguientes pasos para la conversión de Java PDF a Imagen?
Esta guía cubrió tres patrones comunes: convertir todas las páginas de un PDF existente, capturar una URL como un conjunto de imágenes de página, y extraer un rango de páginas específico. IronPDF maneja el control de resolución y la selección de formato a través de ToImageOptions y ImageIO, manteniendo el código de llamada corto y predecible.
Para continuar construyendo con IronPDF for Java, explore estos recursos relacionados:
- Ejemplos de rasterización en Java - muestras de código adicionales de PDF a imagen
- Extraer imágenes y texto de un PDF - extraer imágenes incrustadas de archivos PDF existentes
- Comprimir PDFs en Java - reducir el tamaño del archivo antes del almacenamiento o transmisión
- Marcas de agua personalizadas - sellar imágenes de salida o PDFs con una marca de agua antes de guardar
- Documentación de IronPDF for Java - referencia completa de API y guías de configuración
IronPDF for Java es gratuito para desarrollo. Se requiere una licencia para el despliegue comercial. Comienza tu prueba gratuita o ver las opciones de licencia para ver cuál plan se ajusta a tu proyecto.
¿Listo para ver qué más puede hacer IronPDF? Consulta la página de tutoriales de IronPDF for Java completa.
Preguntas Frecuentes
¿Cómo convierto un archivo PDF en imágenes PNG en Java?
Cargue el PDF usando PdfDocument.fromFile(), llame a toBufferedImages() para obtener una lista de objetos BufferedImage que representan cada página, luego use ImageIO.write() para guardar cada imagen como un archivo PNG.
¿Qué formatos de imagen son compatibles al convertir páginas de PDF?
El método toBufferedImages de IronPDF devuelve objetos BufferedImage. Puede guardar estos en cualquier formato compatible con la clase ImageIO de Java, incluyendo PNG, JPEG y TIFF.
¿Puedo convertir solo páginas específicas de un PDF en imágenes?
Sí. Pase un argumento PageSelection a toBufferedImages. Use PageSelection.singlePage(0) para convertir una página o PageSelection.pageRange(1, 4) para convertir un rango. Los índices de página son basados en cero.
¿Cuáles son los casos de uso comunes para la conversión de PDF a imagen en Java?
Los casos de uso comunes incluyen generar vistas previas en miniatura para sistemas de gestión de documentos, producir capturas de pantalla a nivel de página para aplicaciones web, extraer contenido visual para presentaciones y archivar documentos como archivos de imagen para sistemas que no admiten la renderización de PDF.
¿Cómo añado IronPDF a mi proyecto Maven?
Agregue la siguiente dependencia dentro del bloque
¿Puedo convertir una URL directamente en archivos de imagen?
Sí. Llame a PdfDocument.renderUrlAsPdf(url) para renderizar la página usando el motor Chromium integrado, luego pase el PdfDocument resultante a toBufferedImages para obtener una lista de imágenes de página.
¿Cómo controlo la resolución de la imagen de salida?
Cree una instancia de ToImageOptions, llame a setImageMaxHeight() y setImageMaxWidth() para establecer dimensiones máximas, luego páselo como el primer argumento a toBufferedImages. IronPDF preserva la relación de aspecto y no estira la imagen.


¿Aún desplazándote?
¿Quieres una prueba rápida?
ejecutar una muestra Mira cómo tu HTML se convierte en PDF.













