
fastparquet Python (Cómo Funciona Para Desarrolladores)
fastparquet es una biblioteca de Python diseñada para manejar el formato de archivo Parquet, que se utiliza comúnmente en flujos de trabajo de big data. Se integra bien con otras herramientas de procesamiento de datos basadas en Python como Dask y Pandas. Exploremos sus características y veamos algunos ejemplos de código. Más adelante en este artículo, también aprenderemos sobre IronPDF, una biblioteca de generación de PDF de Iron Software.
Descripción general de fastparquet
fastparquet es eficiente y admite una amplia gama de características de Parquet. Algunas de sus características clave incluyen:
Lectura y escritura de archivos Parquet
Lee y escribe fácilmente archivos Parquet y otros archivos de datos.
Integración con Pandas y Dask
Trabaje sin problemas con DataFrames de Pandas y Dask para el procesamiento paralelo.
Soporte de compresión
Admite varios algoritmos de compresión como gzip, snappy, brotli, lz4 y zstandard en archivos de datos.
Almacenamiento eficiente
Optimizado tanto para el almacenamiento como para la recuperación de grandes conjuntos de datos o archivos de datos utilizando el formato de archivo columnar parquet y el archivo de metadatos apuntando al archivo.
Instalación
Puedes instalar fastparquet usando pip:
pip install fastparquetpip install fastparquetO usando conda:
conda install -c conda-forge fastparquetconda install -c conda-forge fastparquetUso básico
Aquí tienes un ejemplo sencillo para comenzar con fastparquet.
Escribir un archivo Parquet
Puedes escribir un DataFrame de Pandas en un archivo Parquet:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")Resultado
![]()
Lectura de un archivo Parquet
Puedes leer un archivo Parquet en un DataFrame de Pandas:
import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())Resultado

Visualización de metadatos de archivos Parquet
import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
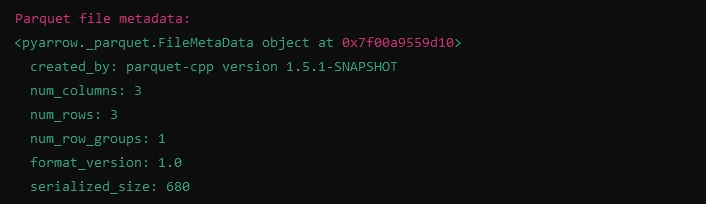
print("Parquet file metadata:")
print(meta)import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)Resultado
Características avanzadas
Uso de Dask para el procesamiento paralelo
fastparquet se integra bien con Dask para manejar grandes conjuntos de datos en paralelo:
import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)Personalización de la compresión
Puedes especificar diferentes algoritmos de compresión al escribir archivos Parquet:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')Presentando IronPDF
IronPDF es una sólida biblioteca de Python diseñada para generar, modificar y firmar digitalmente documentos PDF derivados de HTML, CSS, imágenes y JavaScript. Destaca en rendimiento al mismo tiempo que mantiene un uso mínimo de memoria. Aquí están sus características clave:
1. Conversión de HTML a PDF
Convierte archivos HTML, cadenas HTML y URLs en documentos PDF con IronPDF. Por ejemplo, renderiza sin esfuerzo páginas web en PDFs utilizando el renderizador Chrome PDF.
2. Soporte multiplataforma
Compatible con Python 3+ en Windows, Mac, Linux y varias plataformas en la nube. IronPDF también está disponible para entornos .NET, Java, Python y Node.js.
3. Edición y firma
Modifica propiedades de documentos, mejora la seguridad con protección con contraseña y permisos, e integra firmas digitales en tus PDFs usando IronPDF.
4. Plantillas de página y configuración
Personaliza PDFs con encabezados y pies de página personalizados, números de página y márgenes ajustables. Admite diseños responsivos y acomoda tamaños de papel personalizados.
5. Cumplimiento de estándares
Cumple con estándares PDF como PDF/A y PDF/UA. Maneja codificación de caracteres UTF-8 y gestiona activos como imágenes, hojas de estilo CSS y fuentes de manera efectiva.
Generar documentos PDF con IronPDF y fastparquet
Requisitos previos de IronPDF for Python
- IronPDF se basa en .NET 6.0 como su tecnología subyacente. Por lo tanto, asegúrate de que el runtime .NET 6.0 esté instalado en tu sistema.
- Python 3.0+: Asegúrate de tener instalada la versión 3 o posterior de Python.
- pip: Instala el instalador de paquetes de Python pip para instalar el paquete IronPDF.
Instalación
# Install latest version of the libraries
pip install fastparquet
pip install pandas
pip install ironpdf# Install latest version of the libraries
pip install fastparquet
pip install pandas
pip install ironpdfEjemplo de código
El siguiente ejemplo de código demuestra el uso de fastparquet e IronPDF juntos en Python:
import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
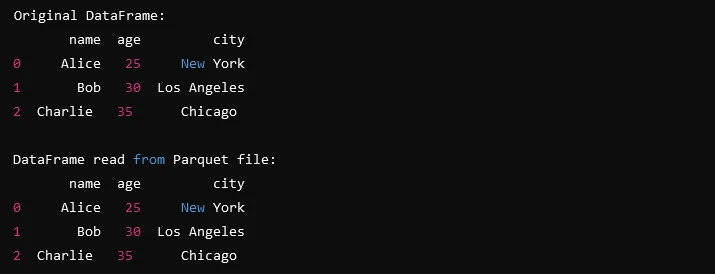
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
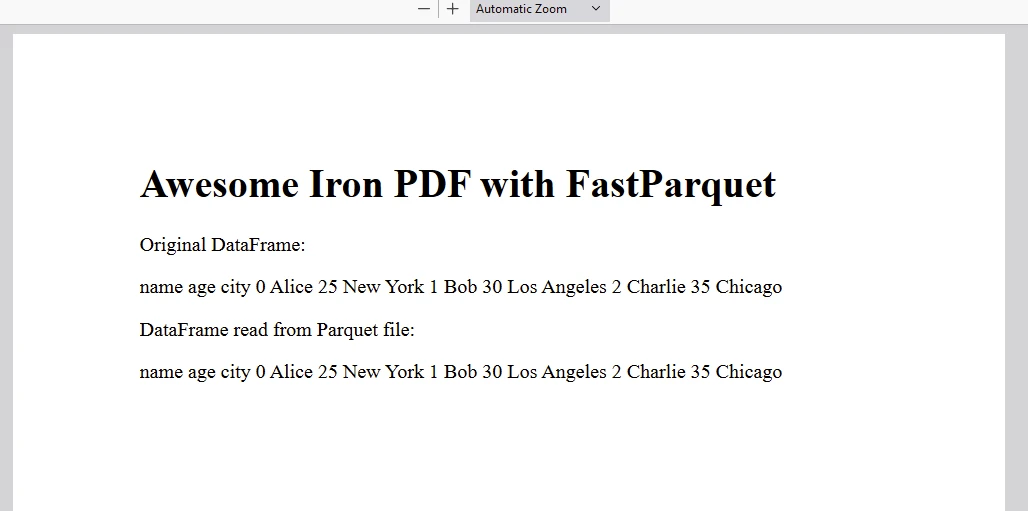
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")Explicación del código
Este fragmento de código demuestra cómo utilizar varias bibliotecas de Python para manipular datos y generar un documento PDF a partir de contenido HTML.
Importaciones y configuración: importe las bibliotecas necesarias para la manipulación de datos, la lectura y escritura de archivos Parquet y la generación de PDF.
Configuración de la clave de licencia: configure la clave de licencia para IronPDF, habilitando sus funciones completas.
Creación de un DataFrame de muestra: Defina un DataFrame de muestra (
df) que contenga información sobre las personas (nombre, edad, ciudad).Escritura de DataFrame en Parquet: escriba el DataFrame
dfen un archivo Parquet llamadoexample.parquet.Lectura desde el archivo Parquet: lee los datos del archivo Parquet (
example.parquet) en un DataFrame (df_read).- Generar PDF a partir de HTML:
- Inicializa una instancia de ChromePdfRenderer usando IronPDF.
- Construya una cadena HTML (
content) que incluya un encabezado (<h1>) y párrafos (<p>) que muestren el DataFrame original (df) y el DataFrame leído del archivo Parquet (df_read). - Renderiza el contenido HTML como un documento PDF usando IronPDF.
- Guarde el documento PDF generado como
Demo-FastParquet.pdf.
El código demuestra un código de ejemplo para FastParquet, integrando capacidades de procesamiento de datos con la generación de PDF, haciéndolo útil para crear informes o documentos basados en datos almacenados en archivos parquet.
PRODUCCIÓN
SALIDA PDF
Licencia de IronPDF
Para obtener información sobre licencias, visita la página de licencias de IronPDF.
Coloca la clave de licencia al inicio del script antes de usar el paquete IronPDF:
from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"Conclusión
fastparquet es una biblioteca poderosa y eficiente para trabajar con archivos parquet en Python. Su integración con Pandas y Dask lo convierte en una excelente opción para manejar grandes conjuntos de datos en un flujo de trabajo de big data basado en Python. IronPDF es una sólida biblioteca de Python que facilita la creación, manipulación y renderización de documentos PDF directamente desde aplicaciones Python. Simplifica tareas como convertir contenido HTML en documentos PDF, crear formularios interactivos y realizar diversas manipulaciones PDF como fusionar archivos o agregar marcas de agua. IronPDF se integra perfectamente con marcos y entornos de Python existentes, proporcionando a los desarrolladores una solución versátil para generar y personalizar documentos PDF dinámicamente. Junto con fastparquet, IronPDF permite una manipulación de datos fluida en formatos de archivos parquet y generación de PDF.
IronPDF ofrece documentación completa y ejemplos de código para ayudar a los desarrolladores a aprovechar al máximo sus características. Para obtener más información, consulta la documentación y las páginas de ejemplo de código.
















