
fastparquet python(開發人員工作原理)
fastparquet 是一個針對 Parquet 檔案格式設計的 Python 程式庫,常用於大資料工作流程中。 它與其他基於 Python 的資料處理工具如 Dask 和 Pandas 整合得很好。 讓我們來探索它的功能並看看一些程式碼範例。 稍後在本文中,我們還將了解從 Iron Software 的 IronPDF,這是一個用於生成 PDF 的程式庫。
fastparquet 概覽
fastparquet 高效且支持多種 Parquet 功能。 它的一些主要功能包括:
讀取和寫入 Parquet 檔案
輕鬆從 Parquet 檔案和其他資料檔案中讀取和寫入。
與 Pandas 和 Dask 的整合
無縫地與 Pandas DataFrame 和 Dask 進行平行處理。
壓縮支持
支援在資料檔案中使用 gzip、snappy、brotli、lz4 和 zstandard 等多種壓縮演算法。
高效儲存
using parquet 欄式檔案格式和元資料檔案指向檔案,優化大資料集的儲存和檢索。
安裝
您可以使用 pip 安裝 fastparquet:
pip install fastparquetpip install fastparquet或使用 conda:
conda install -c conda-forge fastparquetconda install -c conda-forge fastparquet基本用法
這是一個簡單的範例,讓您入門 fastparquet。
寫入 Parquet 檔案
您可以將 Pandas DataFrame 寫入 Parquet 檔案:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")輸出
![]()
讀取 Parquet 檔案
您可以將 Parquet 檔案讀取到 Pandas DataFrame 中:
import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())輸出

顯示 Parquet 檔案的元資料
import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
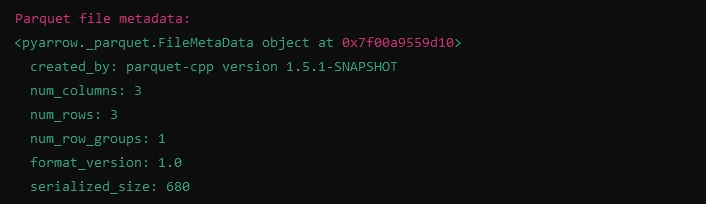
print("Parquet file metadata:")
print(meta)import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)輸出
進階功能
使用 Dask 進行平行處理
fastparquet 與 Dask 整合良好,以平行處理大型資料集:
import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)自定義壓縮
在寫入 Parquet 檔案時,您可以指定不同的壓縮演算法:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')介紹 IronPDF
IronPDF 是一個強大的 Python 程式庫,用於生成、修改和數位簽章從 HTML、CSS、圖像和 JavaScript 衍生的 PDF 文件。 它在保持低記憶體佔用的同時,擁有卓越的性能。 以下是其主要功能:
1. HTML 到 PDF 的轉換
using IronPDF 將 HTML 檔案、HTML 字串和 URL 轉換為 PDF 文件。 例如,使用 Chrome PDF 渲染器輕鬆將網頁渲染為 PDF。
2. 跨平台支持
在 Windows、Mac、Linux 和各種雲端平台上與 Python 3+ 相容。 IronPDF 也適用於 .NET、Java、Python 和 Node.js 環境。
3. 編輯和簽名
修改文件屬性,使用密碼保護和權限提升安全性,並在您的 PDF 中整合數位簽章。
4. 頁面模板和設置
使用自定義的頁眉、頁腳、頁碼和可調整的邊距來定制 PDF。 它支持響應式佈局並可接受自訂的紙張尺寸。
5. 標準合規
符合 PDF 標準如 PDF/A 和 PDF/UA。 它能有效處理 UTF-8 字元編碼並管理資產,例如圖像、CSS 樣式表和字型。
使用 IronPDF 和 fastparquet 生成 PDF 文件
IronPDF for Python 先決條件
- IronPDF 依賴於 .NET 6.0 作為基礎技術。 因此,請確保在您的系統上安裝了.NET 6.0 執行環境。
- Python 3.0+:確保您已安裝 Python 版本 3 或以上。
- pip:安裝 Python 套件安裝工具pip,以安裝 IronPDF 套件。
安裝
pip install fastparquet pandas ironpdf
程式碼範例
以下程式碼範例展示了 fastparquet 與 IronPDF 在 Python 中的使用方法:
import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
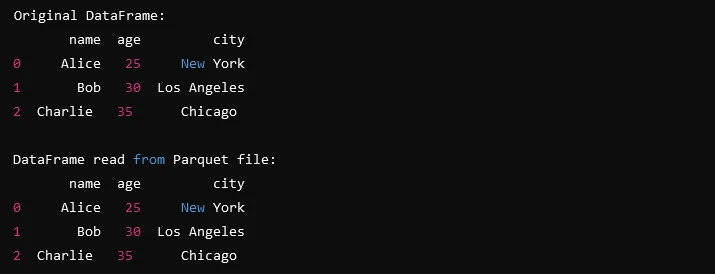
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")程式碼說明
此程式碼片段展示了如何使用多個 Python 程式庫來操控資料並從 HTML 內容生成 PDF 文件。
導入和設置:導入資料操作、讀寫 Parquet 檔案和生成 PDF 所需的程式庫。
設置授權金鑰:設置 IronPDF 的授權金鑰以啟用其完整功能。
建立範例 DataFrame:定義一個範例 DataFrame(
df),包含個人資訊(姓名、年齡、城市)。將 DataFrame 寫入 Parquet:將 DataFrame
df寫入名為example.parquet的 Parquet 檔案。從 Parquet 檔案中讀取:將 Parquet 檔案(
example.parquet)中的資料讀回 DataFrame(df_read)。- 從 HTML 生成 PDF:
- 使用 IronPDF 初始化一個 ChromePdfRenderer 實例。
- 構建一個 HTML 字串(
<p>),顯示原始 DataFrame(df)和從 Parquet 檔案讀取的 DataFrame(df_read)。 - 使用 IronPDF 將 HTML 內容渲染為 PDF 文件。
- 將生成的 PDF 文件儲存為
Demo-FastParquet.pdf。
該程式碼展示了一個 FastParquet 的範例程式碼,將資料處理能力與 PDF 生成結合起來,使其可用於建立基於儲存在 parquet 檔案中的資料的報告或文件。
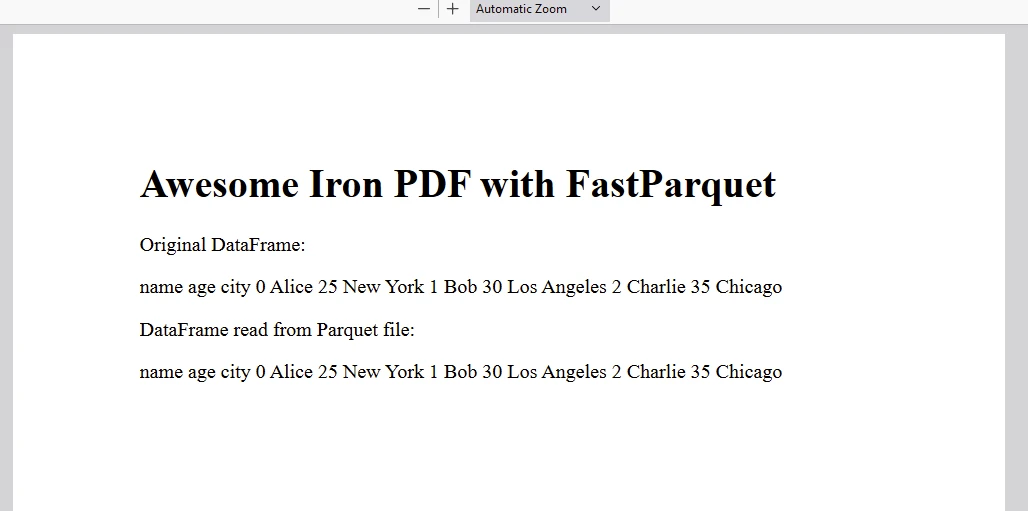
輸出
輸出 PDF
IronPDF 授權
有關授權資訊,請存取 IronPDF 授權頁面。
在使用 IronPDF 套件之前,將 License Key 放在腳本的開頭:
from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"結論
fastparquet 是一個強大且高效的程式庫,用於在 Python 中處理 parquet 檔案。 其與 Pandas 和 Dask 的整合使其成為處理基於 Python 的大資料工作流程中大型資料集的絕佳選擇。 IronPDF 是一個健壯的 Python 程式庫,可方便從 Python 應用程式中直接建立、操作和渲染 PDF 文件。 它簡化了將 HTML 內容轉換為 PDF 文件、建立互動式表單,以及執行各種 PDF 操作(如合併文件或新增水印)等任務。 IronPDF 與現有的 Python 框架和環境無縫整合,為開發人員提供了一個動態生成和自定義 PDF 文件的多功能解決方案。 與 fastparquet 一起,IronPDF 能夠實現無縫的 parquet 文件格式資料操作和 PDF 生成。
















