
fastparquet Python (Geliştiriciler İçin Nasıl Çalışir)
fastparquet, büyük veri iş akışlarında yaygın olarak kullanılan Parquet dosya formatını ele almak için tasarlanmış bir Python kütüphanesidir. Dask ve Pandas gibi diğer Python tabanlı veri işleme araçlarıyla iyi entegre olur. Özelliklerini keşfedelim ve bazı kod örneklerini görelim. Bu makalenin ilerleyen bölümlerinde, IronPDF adlı Iron Software tarafından sunulan PDF oluşturma kütüphanesi hakkında da bilgi edineceğiz.
fastparquet'in Genel Görünümü
fastparquet, verimli ve çok çeşitli Parquet özelliklerini destekler. Bazı temel özellikleri şunlardır:
Parquet Dosyalarını Okuma ve Yazma
Parquet dosyalarından ve diğer veri dosyalarından kolayca okuma ve yazma yapabilirsiniz.
Pandas ve Dask ile Entegrasyon
Parallel işleme için Pandas DataFrames ve Dask ile sorunsuz çalışın.
Sıkıştırma Desteği
Veri dosyalarında gzip, snappy, brotli, lz4 ve zstandard gibi çeşitli sıkıştırma algoritmalarını destekler.
Verimli Depolama
Parquet kolonar dosya formatı ve dosyaya işaret eden metadata dosyası kullanılarak büyük veri kümelerinin veya veri dosyalarının hem depolanması hem de geri alınması için optimize edilmiştir.
Kurulum
fastparquet'i pip kullanarak yükleyebilirsiniz:
pip install fastparquetpip install fastparquetYa da conda kullanarak:
conda install -c conda-forge fastparquetconda install -c conda-forge fastparquetTemel Kullanım
Başlamak için fastparquet ile basit bir örnek.
Parquet Dosyasına Yazma
Bir Pandas DataFrame'i Parquet dosyasına yazabilirsiniz:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")Çıktı
![]()
Parquet Dosyasını Okuma
Bir Parquet dosyasını bir Pandas DataFrame'e okuma yapabilirsiniz:
import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())Çıktı

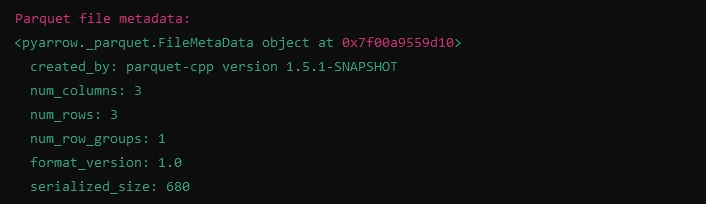
Parquet Dosya Metadata'sını Gösterme
import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)Çıktı
Gelişmiş Özellikler
Parallel İşlem İçin Dask Kullanımı
fastparquet, büyük veri kümelerini parallel işlemek için Dask ile iyi entegre olur:
import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)Sıkıştırmayı Özelleştirme
Parquet dosyalarına yazarken farklı sıkıştırma algoritmalarını belirtebilirsiniz:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')IronPDF Tanıtımı
IronPDF, HTML, CSS, görüntüler ve JavaScript'ten türetilmiş PDF belgeleri oluşturma, değiştirme ve dijital olarak imzalama amacıyla hazırlanmış güçlü bir Python kütüphanesidir. Performansta mükemmel olup, minimum hafıza kullanımı sağlar. İşte ana özellikleri:
1. HTML'den PDF'ye Dönüşüm
IronPDF ile HTML dosyalarını, HTML dizelerini ve URL'leri PDF belgelerine dönüştürün. Örneğin, Chrome PDF renderer kullanarakweb sayfalarını PDF'lere dönüştürün.
2. Platformlar Arası Destek
Windows, Mac, Linux ve çeşitli Bulut Platformlarında Python 3+ ile uyumludur. IronPDF ayrıca .NET, Java, Python ve Node.js ortamlarında da erişilebilirdir.
3. Düzenleme ve İmza
Belgelerin özelliklerini değiştirme, şifre koruma ve izinlerle güvenliği artırma ve PDF'lerinize dijital imzaları entegre etme.
4. Sayfa Şablonları ve Ayarları
Özelleştirilmiş üstbilgiler, altbilgiler, sayfa numaraları ve ayarlanabilir kenar boşlukları ile PDF'leri düzenleyin. Duyarlı düzenleri destekler ve özel kağıt boyutlarını barındırır.
5. Standartlara Uygunluk
PDF/A ve PDF/UA gibi PDF standartlarına uygundur. UTF-8 karakter kodlamasını yönetir ve görüntüler, CSS stiller sayfaları ve yazı tipleri gibi varlıkları etkili bir şekilde yönetir.
IronPDF ve fastparquet Kullanarak PDF Belgeleri Oluşturun
IronPDF Python için Önkabulleri
- IronPDF, teknoloji temelinde .NET 6.0'a güvenir. Bu nedenle, sisteminizde .NET 6.0 runtime'ın yüklü olduğundan emin olun.
- Python 3.0+: Python sürüm 3 veya daha sonrasını yüklendiğinden emin olun.
- pip: IronPDF paketini yüklemek için Python paket yükleyicipip'i yükleyin.
Kurulum
pip install fastparquet pandas ironpdf
Kod Örneği
Aşağıdaki kod örneği Python'da fastparquet ve IronPDF'yi birlikte kullanmayı göstermektedir:
import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
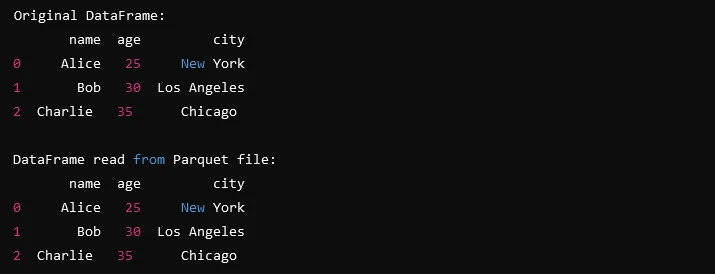
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
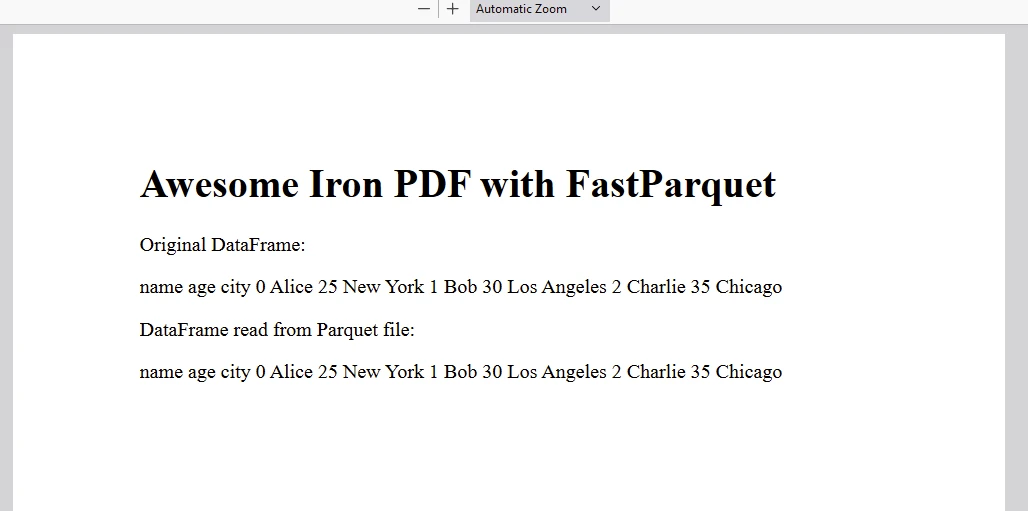
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")Kod Açıklaması
Bu kod parçacığı, birkaç Python kütüphanesini verileri işlemek ve HTML içerikten bir PDF belgesi oluşturmak için nasıl kullanılacağını göstermektedir.
İçe Aktarımlar ve Kurulum: Veri işleme, Parquet dosyalarını okuma ve yazma ve PDF oluşturma için gerekli kütüphaneleri içe aktarın.
Lisans Anahtarını Ayarlama: IronPDF'in tüm özelliklerini etkinleştiren lisans anahtarını ayarlayın.
Örnek DataFrame Oluşturma: Bireylerle ilgili bilgiler (isim, yaş, şehir) içeren bir örnek DataFrame (
df) tanımlayın.DataFrame'i Parquet'e Yazma: DataFrame'i
dfbir Parquet dosyasınaexample.parquetadlı yazın.Parquet Dosyasından Okuma: Verileri Parquet dosyasından (
example.parquet) geri alarak bir DataFrame'e (df_read) okuyun.- HTML'den PDF Oluşturma:
- IronPDF kullanarak bir ChromePdfRenderer örneği başlatın.
- Orijinal DataFrame'i (
df) ve Parquet dosyasından okunan DataFrame'i (df_read) gösteren bir başlık (<h1>) ve paragraflar (<p>) içeren bir HTML dizesi (content) oluşturun. - HTML içeriğini IronPDF kullanarak bir PDF belgesi olarak işleyin.
- Oluşturulan PDF belgesini
Demo-FastParquet.pdfolarak kaydedin.
Kod, FastParquet için örnek bir kodu gösterir; veri işleme yeteneklerini PDF oluşturma ile entegre ederek, parquet dosyalarına dayalı raporlar veya belgeler oluşturmak için yararlı hale getirir.
ÇIKTI
ÇIKTI PDF
IronPDF Lisansı
Lisans bilgileri için IronPDF lisanslama sayfasına gidin.
IronPDF paketini kullanmadan önce Betiğin başına Lisans Anahtarını yerleştirin:
from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"Sonuç
fastparquet, Python'da parquet dosyalarıyla çalışmak için güçlü ve etkili bir kütüphanedir. Pandas ve Dask ile entegrasyonu, Python tabanlı büyük veri iş akışında büyük veri kümelerini yönetmek için harika bir tercih yapar. IronPDF, Python uygulamalarından doğrudan PDF belgeleri oluşturmayı, değiştirmeyi ve işlemeyi kolaylaştıran sağlam bir Python kütüphanesidir. HTML içeriğini PDF belgelerine dönüştürme, etkileşimli formlar oluşturma ve dosyaları birleştirme veya filigran ekleme gibi çeşitli PDF manipülasyonlarını kolaylaştırır. IronPDF mevcut Python çerçeveleri ve ortamlarıyla sorunsuz bir şekilde entegre olur ve geliştiricilere PDF belgelerini dinamik olarak oluşturmak ve özelleştirmek için esnek bir çözüm sunar. fastparquet ile birlikte IronPDF, parquet dosya formatlarında veri işleme ve PDF oluşturmayı sorunsuz bir şekilde sağlar.
IronPDF, geliştiricilerin özelliklerini en iyi şekilde kullanmalarına yardımcı olmak için kapsamlı dokümantasyon ve kod örnekleri sunar. Daha fazla bilgi için lütfen dokümantasyon ve kod örnekleri sayfalarına başvurun.
















