
fastparquet em Python (Como funciona para desenvolvedores)
fastparquet é uma biblioteca Python projetada para lidar com o formato de arquivo Parquet, comumente usado em fluxos de trabalho de big data. Ele se integra bem com outras ferramentas de processamento de dados baseadas em Python, como Dask e Pandas. Vamos explorar suas funcionalidades e ver alguns exemplos de código. Mais adiante neste artigo, também aprenderemos sobre o IronPDF , uma biblioteca de geração de PDFs da Iron Software .
Visão geral do fastparquet
O fastparquet é eficiente e suporta uma ampla gama de recursos de Parquet. Algumas de suas principais características incluem:
Leitura e escrita de arquivos Parquet
Leia e escreva facilmente em arquivos Parquet e outros arquivos de dados.
Integração com Pandas e Dask
Trabalhe perfeitamente com DataFrames do Pandas e Dask para processamento paralelo.
Suporte de compressão
Suporta diversos algoritmos de compressão, como gzip, snappy, brotli, lz4 e zstandard em arquivos de dados.
Armazenamento eficiente
Otimizado para armazenamento e recuperação de grandes conjuntos de dados ou arquivos de dados usando o formato de arquivo colunar Parquet e arquivo de metadados apontando para o arquivo.
Instalação
Você pode instalar o fastparquet usando o pip:
pip install fastparquetpip install fastparquetOu usando o conda:
conda install -c conda-forge fastparquetconda install -c conda-forge fastparquetUso básico
Aqui está um exemplo simples para você começar a usar o fastparquet.
Escrevendo um arquivo Parquet
Você pode gravar um DataFrame do Pandas em um arquivo Parquet:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")Saída
![]()
Como ler um arquivo Parquet
Você pode ler um arquivo Parquet e armazená-lo em um DataFrame do Pandas:
import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())Saída

Exibindo metadados de arquivo Parquet
import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
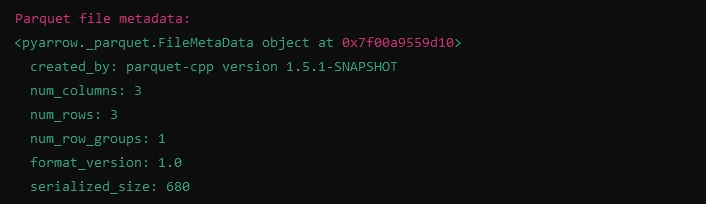
print("Parquet file metadata:")
print(meta)import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)Saída
Recursos avançados
Utilizando Dask para processamento paralelo
O fastparquet integra-se bem com o Dask para lidar com grandes conjuntos de dados em paralelo:
import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)Personalizando a compressão
Você pode especificar diferentes algoritmos de compressão ao gravar arquivos Parquet:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')Apresentando o IronPDF
IronPDF é uma biblioteca Python robusta criada para gerar, modificar e assinar digitalmente documentos PDF derivados de HTML, CSS, imagens e JavaScript. Ele se destaca em desempenho, mantendo ao mesmo tempo uma pegada de memória mínima. Eis suas principais características:
1. Conversão de HTML para PDF
Converta arquivos HTML, strings HTML e URLs em documentos PDF com o IronPDF. Por exemplo, converta páginas da web em PDFs sem esforço usando o renderizador de PDF do Chrome.
2. Suporte multiplataforma
Compatível com Python 3+ em Windows, Mac, Linux e diversas plataformas em nuvem. O IronPDF também está disponível para ambientes .NET, Java, Python e Node.js
3. Edição e Assinatura
Modifique as propriedades do documento, aprimore a segurança com proteção por senha e permissões e integre assinaturas digitais em seus PDFs usando o IronPDF.
4. Modelos de página e configurações
Personalize PDFs com cabeçalhos, rodapés , números de página e margens ajustáveis. Suporta layouts responsivos e acomoda tamanhos de papel personalizados.
5. Conformidade com as normas
Compatível com padrões PDF como PDF/A e PDF/UA. Ele lida com a codificação de caracteres UTF-8 e gerencia recursos como imagens, folhas de estilo CSS e fontes de forma eficiente.
Gere documentos PDF usando IronPDF e fastparquet
Pré-requisitos do IronPDF for Python
- O IronPDF utiliza o .NET 6.0 como tecnologia subjacente. Portanto, certifique-se de que o runtime do .NET 6.0 esteja instalado em seu sistema.
- Python 3.0+: Certifique-se de ter a versão 3 ou posterior do Python instalada.
- pip: Instale o instalador de pacotes Python pip para instalar o pacote IronPDF .
Instalação
pip install fastparquet pandas ironpdf
Exemplo de código
O exemplo de código a seguir demonstra o uso conjunto de fastparquet e IronPDF em Python:
import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
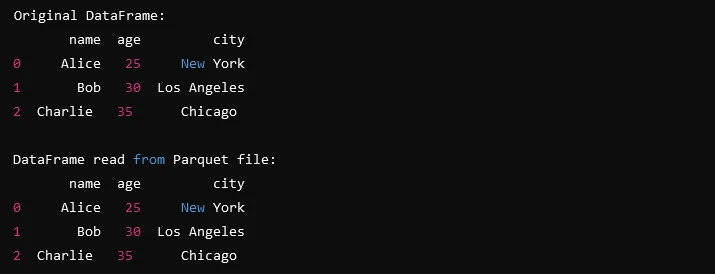
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
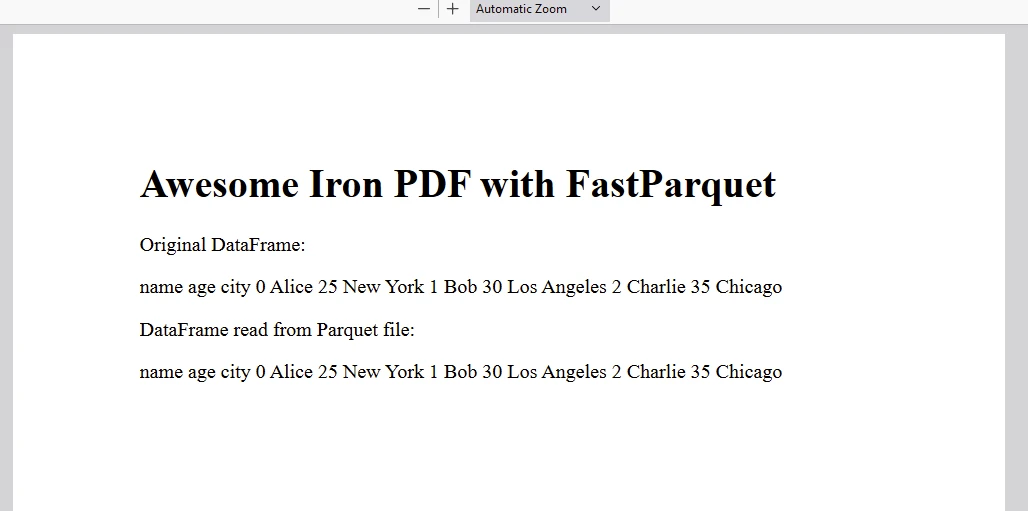
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")Explicação do código
Este trecho de código demonstra como utilizar diversas bibliotecas Python para manipular dados e gerar um documento PDF a partir de conteúdo HTML.
-
Importação e Configuração: Importe as bibliotecas necessárias para manipulação de dados, leitura e gravação de arquivos Parquet e geração de PDFs.
-
Configurar chave de licença: Defina a chave de licença do IronPDF para ativar todos os seus recursos.
-
Criando um DataFrame de Exemplo: Defina um DataFrame de exemplo (
df) contendo informações sobre indivíduos (nome, idade, cidade). -
Gravando DataFrame em Parquet: Escreva o DataFrame
dfem um arquivo Parquet chamadoexample.parquet. -
Lendo de Arquivo Parquet: Leia os dados do arquivo Parquet (
example.parquet) de volta para um DataFrame (df_read). - Gerando PDF a partir de HTML:
- Inicialize uma instância de ChromePdfRenderer usando o IronPDF.
- Construa uma string HTML (
content) que inclua um título (<h1>) e parágrafos (<p>) exibindo o DataFrame original (df) e o DataFrame lido do arquivo Parquet (df_read). - Renderize o conteúdo HTML como um documento PDF usando o IronPDF.
- Salve o documento PDF gerado como
Demo-FastParquet.pdf.
O código demonstra um exemplo de código para FastParquet, integrando recursos de processamento de dados com geração de PDF, tornando-o útil para criar relatórios ou documentos com base em dados armazenados em arquivos Parquet.
SAÍDA
PDF de saída
Licença IronPDF
Para informações sobre licenças, visite a página de licenciamento do IronPDF .
Insira a chave de licença no início do script antes de usar o pacote IronPDF :
from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"Conclusão
fastparquet é uma biblioteca poderosa e eficiente para trabalhar com arquivos parquet em Python. Sua integração com Pandas e Dask o torna uma ótima opção para lidar com grandes conjuntos de dados em um fluxo de trabalho de big data baseado em Python. IronPDF é uma biblioteca Python robusta que facilita a criação, manipulação e renderização de documentos PDF diretamente de aplicações Python. Simplifica tarefas como converter conteúdo HTML em documentos PDF, criar formulários interativos e realizar diversas manipulações em PDFs, como mesclar arquivos ou adicionar marcas d'água. O IronPDF integra-se perfeitamente com as estruturas e ambientes Python existentes, fornecendo aos desenvolvedores uma solução versátil para gerar e personalizar documentos PDF dinamicamente. Em conjunto com o fastparquet , o IronPDF permite a manipulação perfeita de dados em formatos de arquivo Parquet e a geração de PDFs.
O IronPDF oferece documentação completa e exemplos de código para ajudar os desenvolvedores a aproveitarem ao máximo seus recursos. Para obter mais informações, consulte a documentação e as páginas de exemplos de código .
















