
fastparquet Python(开发人员如何使用)
fastparquet 是一个Python库,专为处理Parquet文件格式而设计,这在大数据工作流中被广泛使用。 它与其他基于Python的数据处理工具如Dask和Pandas集成得很好。 让我们探索一下它的功能,并查看一些代码示例。 在本文的后面部分,我们还将学习关于 IronPDF,这是 Iron Software 的一个PDF生成库。
fastparquet概述
fastparquet 高效且支持多种Parquet功能。 它的一些关键功能包括:
读取和写入Parquet文件
轻松从Parquet文件和其他数据文件中读取和写入。
与Pandas和Dask的集成
无缝使用Pandas DataFrames和Dask进行并行处理。
压缩支持
支持gzip、snappy、brotli、lz4和zstandard等多种数据文件压缩算法。
高效存储
使用Parquet列存文件格式和指向文件的元数据文件优化存储和检索大数据集或数据文件。
安装
可以使用pip安装fastparquet:
pip install fastparquetpip install fastparquet或者使用conda:
conda install -c conda-forge fastparquetconda install -c conda-forge fastparquet基本用法
这里是一个简单的示例,让您开始使用fastparquet。
写入Parquet文件
可以将Pandas DataFrame写入Parquet文件:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")输出
![]()
读取Parquet文件
可以将Parquet文件读取到Pandas DataFrame中:
import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())输出

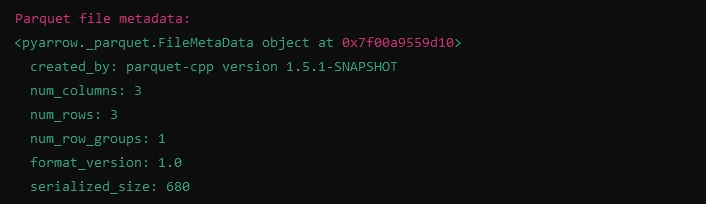
显示Parquet文件元数据
import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)输出
高级功能
使用Dask进行并行处理
fastparquet与Dask集成良好,可并行处理大型数据集:
import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)自定义压缩
在写入Parquet文件时可以指定不同的压缩算法:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')IronPDF 简介
IronPDF 是一个强大的Python库,专为从HTML、CSS、图像和JavaScript生成、修改和数字签名PDF文档而打造。 它在性能方面表现优异,同时保持最低的内存占用。 以下是其关键特性:
1. HTML到PDF转换
使用IronPDF将HTML文件、HTML字符串和网址转换为PDF文档。 例如,使用Chrome PDF渲染器轻松将网页呈现为PDF。
2. 跨平台支持
兼容Windows、Mac、Linux和各种云平台上的Python 3+。 IronPDF也适用于.NET、Java、Python和Node.js环境。
3. 编辑和签署
修改文档属性,通过密码保护和权限增强安全性,并将数字签名集成到PDF中使用IronPDF。
4. 页面模板和设置
通过自定义页眉、页脚、页码和可调边距来定制PDF。 它支持响应布局并适应自定义纸张尺寸。
5. 标准符合性
符合PDF标准如PDF/A和PDF/UA。 它有效地处理UTF-8字符编码,并管理如图像、CSS样式表和字体等资产。
使用IronPDF和fastparquet生成PDF文档
IronPDF for Python先决条件
- IronPDF 依赖于.NET 6.0作为其底层技术。 因此,请确保系统上已安装.NET 6.0 runtime。
- Python 3.0+:确保您已安装Python 3或更高版本。
- pip:安装Python包管理器pip用于安装IronPDF包。
安装
pip install fastparquet pandas ironpdf
代码示例
以下代码示例演示了在Python中结合使用fastparquet和IronPDF:
import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
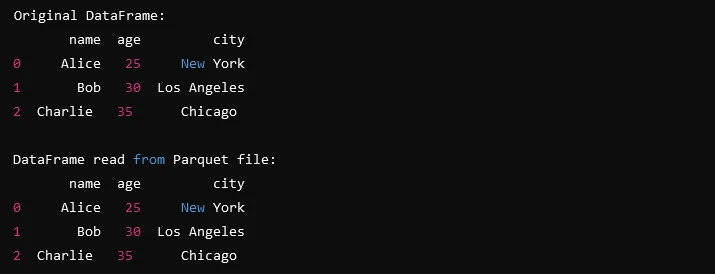
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
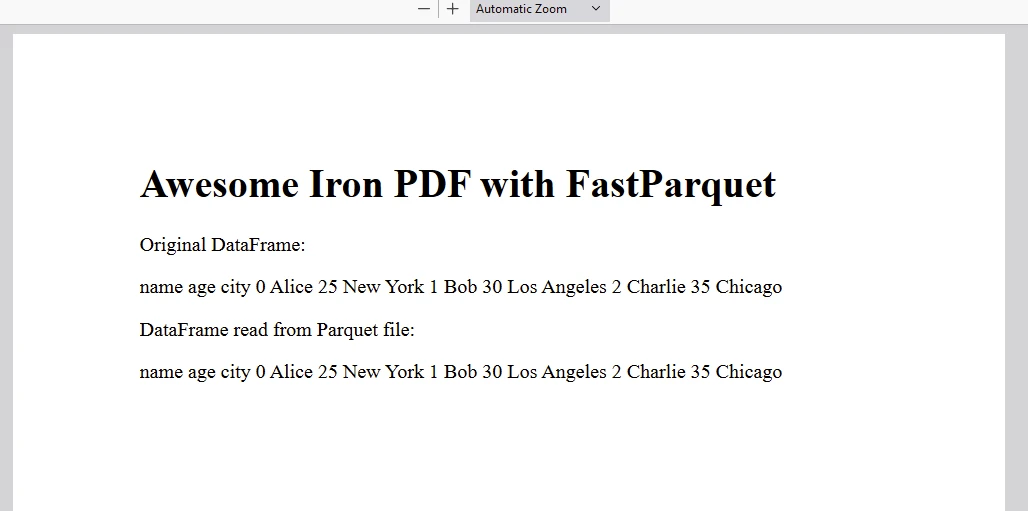
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")代码解释
此代码片段演示如何使用多个Python库来操作数据,并从HTML内容生成PDF文档。
1.导入和设置:导入数据操作、读取和写入 Parquet 文件以及生成 PDF 所需的库。
2.设置许可证密钥:设置IronPDF的许可证密钥,启用其全部功能。
创建示例DataFrame:定义一个包含个人信息(姓名,年龄,城市)的示例DataFrame (
df)。将DataFrame写入Parquet:将DataFrame
df写入名为example.parquet的Parquet文件。从Parquet文件读取:将Parquet文件 (
example.parquet) 中的数据重新读取到DataFrame (df_read)。- 从HTML生成PDF:
- 使用IronPDF初始化ChromePdfRenderer实例。
- 构建一个包括标题 (
<h1>) 和段落 (<p>) 的HTML字符串 (content),显示原始DataFrame (df) 和从Parquet文件读取的DataFrame (df_read)。 - 使用IronPDF将HTML内容渲染为PDF文档。
- 将生成的PDF文档保存为
Demo-FastParquet.pdf。
该代码展示如何将FastParquet的数据处理能力与PDF生成相结合,使其可用于基于Parquet文件存储的数据创建报告或文档。
输出
输出 PDF
IronPDF 许可证
有关许可证信息,请访问IronPDF许可证页面。
在使用 IronPDF 包 之前,将许可证密钥放置在脚本的开头:
from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"结论
fastparquet 是一个强大且高效的Python库,用于处理Parquet文件。 其与Pandas和Dask的集成使其成为Python大数据工作流中处理大数据集的理想选择。 IronPDF 是一个强大的Python库,便于直接从Python应用程序创建、操作和渲染PDF文档。 它简化了将HTML内容转换为PDF文档、创建交互式表单,并执行合并文件或添加水印等各种PDF操作的任务。 IronPDF 无缝集成到现有的Python框架和环境中,为开发人员提供了一个可动态生成和自定义PDF文档的多功能解决方案。 结合fastparquet,IronPDF 实现了在Parquet文件格式和PDF生成中的无缝数据操作。
















