
fastparquet Python (개발자를 위한 작동 방식)
fastparquet 은 빅데이터 워크플로우에서 흔히 사용되는 Parquet 파일 형식을 처리하도록 설계된 Python 라이브러리입니다. Dask 및 Pandas와 같은 다른 Python 기반 데이터 처리 도구와도 잘 통합됩니다. 이제 그 기능을 살펴보고 몇 가지 코드 예제를 확인해 보겠습니다. 이 글 후반부에서는 Iron Software 에서 개발한 PDF 생성 라이브러리인 IronPDF 에 대해서도 알아보겠습니다.
패스트파케트 개요
fastparquet은 효율적이며 다양한 Parquet 기능을 지원합니다. 주요 특징은 다음과 같습니다.
마루 파일 읽기 및 쓰기
Parquet 파일 및 기타 데이터 파일을 쉽게 읽고 쓸 수 있습니다.
Pandas 및 Dask와의 통합
Pandas DataFrame과 Dask를 활용하여 병렬 처리를 원활하게 수행하세요.
압축 지지대
데이터 파일에서 gzip, snappy, brotli, lz4, zstandard 등 다양한 압축 알고리즘을 지원합니다.
효율적인 보관
Parquet 컬럼형 파일 형식과 파일을 가리키는 메타데이터 파일을 사용하여 대규모 데이터 세트 또는 데이터 파일의 저장 및 검색에 최적화되어 있습니다.
설치
pip를 사용하여 fastparquet을 설치할 수 있습니다.
pip install fastparquetpip install fastparquet또는 conda를 사용하는 방법:
conda install -c conda-forge fastparquetconda install -c conda-forge fastparquet기본 사용법
fastparquet을 시작하는 데 도움이 되는 간단한 예제를 소개합니다.
Parquet 파일 작성하기
Pandas DataFrame을 Parquet 파일로 저장할 수 있습니다.
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")산출
![]()
파케트 파일 읽기
Parquet 파일을 Pandas DataFrame으로 읽어들일 수 있습니다.
import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())산출

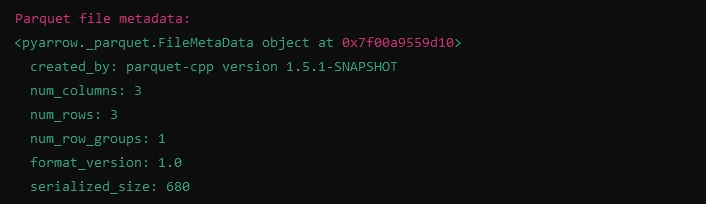
Parquet 파일 메타데이터 표시
import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)산출
고급 기능
Dask를 이용한 병렬 처리
fastparquet은 대규모 데이터 세트를 병렬로 처리하는 데 있어 Dask 와 잘 통합됩니다.
import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)압축 사용자 지정
Parquet 파일을 작성할 때 서로 다른 압축 알고리즘을 지정할 수 있습니다.
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')IronPDF 소개합니다
IronPDF 는 HTML, CSS, 이미지 및 JavaScript 에서 파생된 PDF 문서를 생성, 수정 및 디지털 서명하기 위해 제작된 강력한 Python 라이브러리입니다. 이 제품은 뛰어난 성능을 제공하면서도 메모리 사용량은 최소화합니다. 주요 특징은 다음과 같습니다.
1. HTML을 PDF로 변환
IronPDF 사용하여 HTML 파일, HTML 문자열 및 URL을 PDF 문서로 변환하세요. 예를 들어, Chrome PDF 렌더러를 사용하면 웹페이지를 손쉽게 PDF로 변환할 수 있습니다 .
2. 크로스 플랫폼 지원
Windows, Mac, Linux 및 다양한 클라우드 플랫폼에서 Python 3 이상 버전과 호환됩니다. IronPDF 는 .NET, Java, Python 및 Node.js 환경에서도 사용할 수 있습니다.
3. 편집 및 서명
IronPDF 사용하여 문서 속성을 수정하고, 암호 보호 및 권한 설정을 통해 보안을 강화하고, PDF에 디지털 서명을 통합하세요.
4. 페이지 템플릿 및 설정
사용자 지정 머리글, 바닥글 , 페이지 번호 및 조정 가능한 여백을 사용하여 PDF를 맞춤 설정하세요. 반응형 레이아웃을 지원하고 사용자 지정 용지 크기를 수용합니다.
5. 표준 준수
PDF/A 및 PDF/UA와 같은 PDF 표준을 준수합니다. 이 프로그램은 UTF-8 문자 인코딩을 처리하며 이미지, CSS 스타일시트, 글꼴과 같은 자산을 효율적으로 관리합니다.
IronPDF 와 fastparquet을 사용하여 PDF 문서를 생성합니다.
Python용 IronPDF 필수 조건
- IronPDF 기반 기술로 .NET 6.0을 사용합니다. 그러므로 시스템에 .NET 6.0 런타임이 설치되어 있는지 확인하십시오.
- Python 3.0 이상: Python 버전 3 이상이 설치되어 있는지 확인하십시오.
- pip: IronPDF Install-Package를 위해 Python Install-Package 프로그램인 pip를 설치합니다.
설치
pip install fastparquet pandas ironpdf
코드 예제
다음 코드 예제는 Python에서 fastparquet과 IronPDF 함께 사용하는 방법을 보여줍니다.
import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
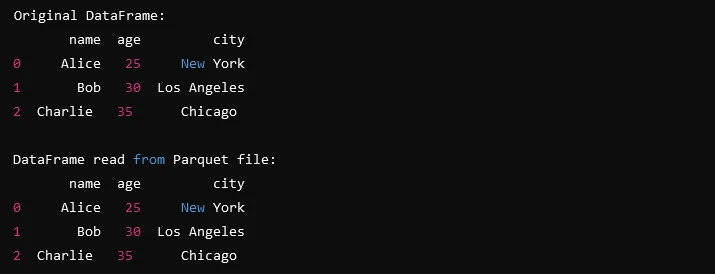
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
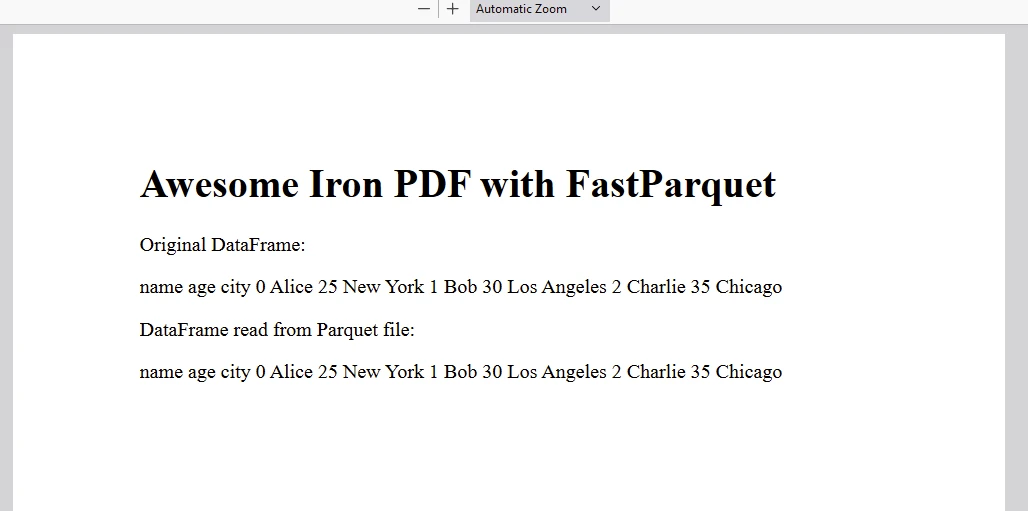
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")코드 설명
이 코드 조각은 여러 Python 라이브러리를 활용하여 데이터를 조작하고 HTML 콘텐츠에서 PDF 문서를 생성하는 방법을 보여줍니다.
가져오기 및 설정: 데이터 조작, Parquet 파일 읽기 및 쓰기, PDF 생성에 필요한 라이브러리를 가져옵니다.
라이선스 키 설정: IronPDF 의 라이선스 키를 설정하여 모든 기능을 활성화하십시오.
샘플 DataFrame 생성: 개인 정보(이름, 나이, 도시)를 포함하는 샘플 DataFrame (
df) 정의.DataFrame을 Parquet 파일로 저장: DataFrame
df을(를)example.parquet라는 이름의 Parquet 파일에 저장.Parquet 파일에서 읽기: Parquet 파일 (
example.parquet)에서 데이터를 다시 DataFrame (df_read)으로 읽기.- HTML에서 PDF 생성:
- IronPDF 사용하여 ChromePdfRenderer 인스턴스를 초기화합니다.
- 제목(
<h1>)과 단락(<p>)을 포함하는 HTML 문자열(content)을 구성하여 원본 DataFrame(df)과 Parquet 파일에서 읽은 DataFrame(df_read)을 표시. - IronPDF 사용하여 HTML 콘텐츠를 PDF 문서로 렌더링합니다.
- 생성된 PDF 문서를
Demo-FastParquet.pdf으로 저장.
이 코드는 FastParquet의 샘플 코드로서, 데이터 처리 기능과 PDF 생성 기능을 통합하여 Parquet 파일에 저장된 데이터를 기반으로 보고서나 문서를 생성하는 데 유용하게 사용할 수 있습니다.
산출
출력 PDF
IronPDF 라이선스
라이선스 정보는 IronPDF 라이선스 페이지를 참조하십시오.
IronPDF 패키지를 사용하기 전에 스크립트 시작 부분에 라이선스 키를 배치하십시오.
from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"결론
fastparquet은 Python에서 parquet 파일을 다루기 위한 강력하고 효율적인 라이브러리입니다. Pandas 및 Dask와의 통합 덕분에 Python 기반 빅 데이터 워크플로에서 대규모 데이터 세트를 처리하는 데 매우 적합합니다. IronPDF 는 Python 애플리케이션에서 PDF 문서를 직접 생성, 조작 및 렌더링할 수 있도록 지원하는 강력한 Python 라이브러리입니다. 이 프로그램은 HTML 콘텐츠를 PDF 문서로 변환하거나, 대화형 양식을 만들거나, 파일 병합 또는 워터마크 추가와 같은 다양한 PDF 조작을 수행하는 등의 작업을 간소화합니다. IronPDF 기존 Python 프레임워크 및 환경과 완벽하게 통합되어 개발자에게 PDF 문서를 동적으로 생성하고 사용자 정의할 수 있는 다재다능한 솔루션을 제공합니다. IronPDF fastparquet 과 함께 사용하면 parquet 파일 형식의 데이터를 원활하게 조작하고 PDF를 생성할 수 있습니다.
IronPDF 개발자가 기능을 최대한 활용할 수 있도록 포괄적인 문서와 코드 예제를 제공합니다. 더 자세한 내용은 설명서 및 코드 예제 페이지를 참조하십시오.
















