
fastparquet python (Wie es für Entwickler funktioniert)
fastparquet ist eine Python-Bibliothek, die entwickelt wurde, um mit dem Parquet-Dateiformat umzugehen, das häufig in Big-Data-Workflows verwendet wird. Es integriert sich gut mit anderen Python-basierten Datenverarbeitungstools wie Dask und Pandas. Lassen Sie uns seine Funktionen erkunden und einige Codebeispiele ansehen. Später in diesem Artikel erfahren wir auch mehr über IronPDF, eine PDF-Generierungsbibliothek von Iron Software.
Überblick über fastparquet
fastparquet ist effizient und unterstützt eine breite Palette von Parquet-Funktionen. Einige seiner wichtigsten Funktionen sind:
Lesen und Schreiben von Parquet-Dateien
Einfaches Lesen von und Schreiben zu Parquet-Dateien und anderen Datendateien.
Integration mit Pandas und Dask
Nahtlose Arbeit mit Pandas DataFrames und Dask für parallele Verarbeitung.
Unterstützung für Komprimierung
Unterstützt verschiedene Kompressionsalgorithmen wie gzip, snappy, brotli, lz4 und zstandard in Datendateien.
Effiziente Speicherung
Optimiert für sowohl Speicherung als auch Abruf großer Datensätze oder Datendateien mithilfe des Parquet-säulenbasierten Dateiformats und Metadatendateien, die auf die Datei verweisen.
Installation
Sie können fastparquet mit pip installieren:
pip install fastparquetpip install fastparquetOder mit conda:
conda install -c conda-forge fastparquetconda install -c conda-forge fastparquetGrundlagen
Hier ist ein einfaches Beispiel, um Ihnen den Einstieg mit fastparquet zu erleichtern.
Schreiben einer Parquet-Datei
Sie können ein Pandas DataFrame in eine Parquet-Datei schreiben:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
})
# Write the DataFrame to a Parquet file
df.to_parquet('example.parquet', engine='fastparquet')
# Display confirmation message
print("DataFrame successfully written to 'example.parquet'.")Ausgabe
![]()
Lesen einer Parquet-Datei
Sie können eine Parquet-Datei in ein Pandas DataFrame einlesen:
import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())import pandas as pd
# Read a Parquet file
df = pd.read_parquet('example.parquet', engine='fastparquet')
# Display the DataFrame
print(df.head())Ausgabe

Anzeigen von Parquet-Dateimetadata
import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)import fastparquet as fp
# Reading metadata from Parquet file
meta = fp.ParquetFile('example.parquet').metadata
print("Parquet file metadata:")
print(meta)Ausgabe
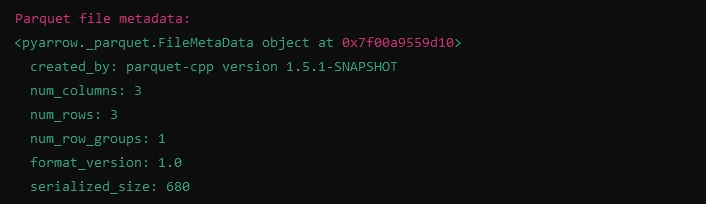
Erweiterte Funktionen
Verwendung von Dask für parallele Verarbeitung
fastparquet integriert sich gut mit Dask für die Bearbeitung großer Datensätze in Parallelverarbeitung:
import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)import dask.dataframe as dd
# Read a Parquet file into a Dask DataFrame
ddf = dd.read_parquet('example.parquet', engine='fastparquet')
# Perform operations on the Dask DataFrame
result = ddf.groupby('name').mean().compute()
# Display the result
print(result)Anpassen der Komprimierung
Sie können beim Schreiben von Parquet-Dateien verschiedene Kompressionsalgorithmen angeben:
import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')import pandas as pd
# Create a sample DataFrame
df = pd.DataFrame({
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35]
})
# Write the DataFrame to a Parquet file with gzip compression
df.to_parquet('example.parquet', engine='fastparquet', compression='gzip')Einführung in IronPDF
IronPDF ist eine robuste Python-Bibliothek, die für das Erstellen, Ändern und digitale Signieren von PDF-Dokumenten entwickelt wurde, die von HTML, CSS, Bildern und JavaScript abgeleitet sind. Es überzeugt durch Leistung und behält gleichzeitig einen minimalen Speicherbedarf bei. Hier sind seine Hauptfunktionen:
1. HTML-zu-PDF-Umwandlung
Konvertieren Sie HTML-Dateien, HTML-Strings und URLs in PDF-Dokumente mit IronPDF. Zum Beispiel mühelos Webseiten in PDFs rendern mit dem Chrome PDF-Renderer.
2. Plattformübergreifende Unterstützung
Kompatibel mit Python 3+ unter Windows, Mac, Linux und verschiedenen Cloud-Plattformen. IronPDF ist auch für .NET-, Java-, Python- und Node.js-Umgebungen zugänglich.
3. Bearbeiten und Signieren
Ändern Sie die Dokumenteigenschaften, erhöhen Sie die Sicherheit mit Passwortschutz und Berechtigungen und integrieren Sie digitale Signaturen in Ihre PDFs mit IronPDF.
4. Seitenschablonen und Einstellungen
Passen Sie PDFs mit benutzerdefinierten Kopfzeilen, Fußzeilen, Seitenzahlen und anpassbaren Rändern an. Es unterstützt responsive Layouts und bietet die Möglichkeit, benutzerdefinierte Papiergrößen anzupassen.
5. Einhaltung von Standards
Es erfüllt PDF-Standards wie PDF/A und PDF/UA. Es verarbeitet UTF-8-Zeichencodierung und verwaltet effektiv Assets wie Bilder, CSS-Stilblätter und Schriftarten.
PDF-Dokumente mit IronPDF und fastparquet erstellen
IronPDF für Python Voraussetzungen
- IronPDF stützt sich auf .NET 6.0 als seine zugrunde liegende Technologie. Stellen Sie daher sicher, dass .NET 6.0 Runtime auf Ihrem System installiert ist.
- Python 3.0+: Stellen Sie sicher, dass Sie Python Version 3 oder höher installiert haben.
- pip: Installieren Sie den Python-Paketmanager pip für die Installation des IronPDF-Pakets.
Installation
# Install latest version of the libraries
pip install fastparquet
pip install pandas
pip install ironpdf# Install latest version of the libraries
pip install fastparquet
pip install pandas
pip install ironpdfBeispielcode
Das folgende Codebeispiel zeigt die Verwendung von fastparquet und IronPDF zusammen in Python:
import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
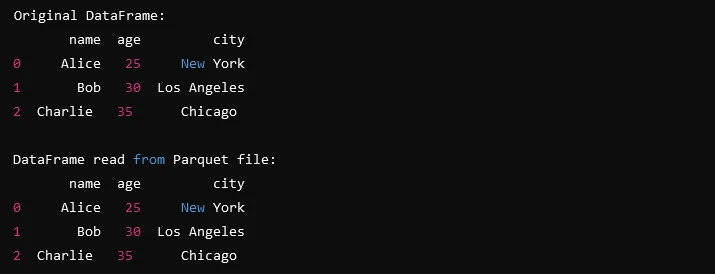
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
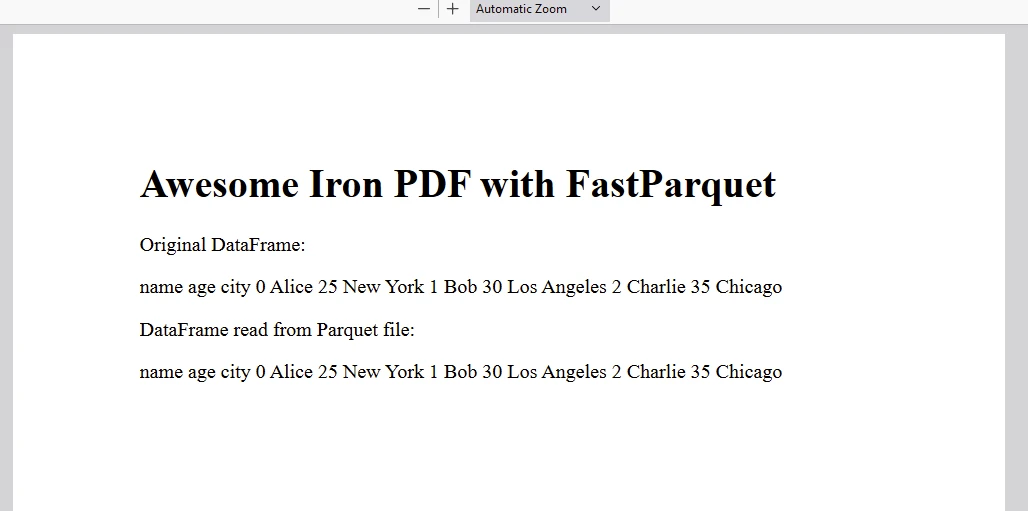
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")import pandas as pd
import fastparquet as fp
from ironpdf import ChromePdfRenderer, License
# Apply your license key for IronPDF
License.LicenseKey = "your Key"
# Sample DataFrame
data = {
'name': ['Alice', 'Bob', 'Charlie'],
'age': [25, 30, 35],
'city': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# Writing DataFrame to a Parquet file
fp.write('example.parquet', df)
# Reading from Parquet file into DataFrame
df_read = fp.ParquetFile('example.parquet').to_pandas()
# Displaying the read DataFrame
print("Original DataFrame:")
print(df)
print("\nDataFrame read from Parquet file:")
print(df_read)
# Initialize a ChromePdfRenderer instance
renderer = ChromePdfRenderer()
# Create a PDF from a HTML string using IronPDF
content = "<h1>Awesome Iron PDF with FastParquet</h1>"
content += "<p> Original DataFrame:</p>"
content += "<p>" + f"{str(df)}" + "</p>"
content += "<p> DataFrame read from Parquet file:</p>"
content += "<p>" + f"{str(df_read)}" + "</p>"
# Render the HTML content to a PDF
pdf = renderer.RenderHtmlAsPdf(content)
# Export the PDF to a file
pdf.SaveAs("Demo-FastParquet.pdf")Code-Erklärung
Dieser Codeausschnitt zeigt, wie Sie mehrere Python-Bibliotheken verwenden, um Daten zu manipulieren und ein PDF-Dokument aus HTML-Inhalten zu erstellen.
-
Import und Einrichtung: Importieren Sie die notwendigen Bibliotheken für die Datenmanipulation, das Lesen und Schreiben von Parquet-Dateien und die PDF-Generierung.
-
Lizenzschlüssel festlegen: Legen Sie den Lizenzschlüssel für IronPDF fest, um alle Funktionen zu aktivieren.
-
Erstellen eines Beispiel-DataFrames: Definieren Sie einen Beispiel-DataFrame (
df), der Informationen über Personen (Name, Alter, Stadt) enthält. -
DataFrame in Parquet schreiben: Schreiben Sie den DataFrame
dfin eine Parquet-Datei mit dem Namenexample.parquet. -
Lesen aus der Parquet-Datei: Daten aus der Parquet-Datei (
example.parquet) zurück in einen DataFrame (df_read) lesen. - PDF aus HTML generieren:
- Eine ChromePdfRenderer-Instanz mit IronPDF initialisieren.
- Erstellen Sie eine HTML-Zeichenkette (
content), die eine Überschrift (<h1>) und Absätze (<p>) enthält, welche den ursprünglichen DataFrame (df) und den aus der Parquet-Datei gelesenen DataFrame (df_read) anzeigen. - Den HTML-Inhalt als PDF-Dokument mit IronPDF rendern.
- Speichern Sie das generierte PDF-Dokument unter
Demo-FastParquet.pdf.
Der Code zeigt ein Beispiel für die Verwendung von FastParquet, indem Datenverarbeitungsfunktionen mit der PDF-Erzeugung integriert werden, was es nützlich macht, Berichte oder Dokumente basierend auf Daten zu erstellen, die in Parquet-Dateien gespeichert sind.
AUSGABE
AUSGABE-PDF
IronPDF-Lizenz
Für Lizenzinformationen besuchen Sie die IronPDF-Lizenzierungsseite.
Setzen Sie den Lizenzschlüssel am Anfang des Skripts, bevor Sie das IronPDF-Paket verwenden:
from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"from ironpdf import License
# Apply your license key
License.LicenseKey = "your Key"Abschluss
fastparquet ist eine leistungsstarke und effiziente Bibliothek zum Arbeiten mit Parquet-Dateien in Python. Die Integration mit Pandas und Dask macht es zu einer hervorragenden Wahl für die Handhabung großer Datensätze in einem Python-basierten Big-Data-Workflow. IronPDF ist eine robuste Python-Bibliothek, die die Erstellung, Bearbeitung und Wiedergabe von PDF-Dokumenten direkt aus Python-Anwendungen ermöglicht. Es vereinfacht Aufgaben wie das Konvertieren von HTML-Inhalten in PDF-Dokumente, das Erstellen interaktiver Formulare und das Durchführen verschiedener PDF-Manipulationen wie das Zusammenführen von Dateien oder das Hinzufügen von Wasserzeichen. IronPDF integriert sich nahtlos mit bestehenden Python-Frameworks und -Umgebungen und bietet Entwicklern eine vielseitige Lösung zur dynamischen Erstellung und Anpassung von PDF-Dokumenten. Zusammen mit fastparquet ermöglicht IronPDF nahtlose Datenverarbeitung im Parquet-Dateiformat und die PDF-Erzeugung.
IronPDF bietet umfassende Dokumentation und Codebeispiele, um Entwicklern dabei zu helfen, das Beste aus seinen Funktionen herauszuholen. Für weitere Informationen lesen Sie bitte die Dokumentation und die Codebeispiel-Seiten.
















