
Guía de Pandas en Python para Ciencia de Datos
Pandas es una popular herramienta de análisis de datos en el lenguaje de programación Python, reconocida por su facilidad de uso y versatilidad en el manejo de datos tabulares. Esta guía le llevará a través de lo esencial del uso de Pandas, centrándose en ejemplos prácticos y técnicas eficientes para la manipulación y análisis de datos.
Entendiendo el DataFrame: El núcleo de Pandas
1. Acceso a datos en Pandas
La estructura principal en Pandas es el DataFrame, una herramienta poderosa para el análisis y manipulación de datos. Para comenzar, exploremos cómo acceder a los datos dentro de un DataFrame.
1.1 Cargar datos desde un archivo CSV
Por ejemplo, si tiene un archivo CSV que contiene sus datos, puede cargarlo en un DataFrame y comenzar a manipularlo. El código a continuación demuestra cómo cargar datos desde un archivo CSV:
import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')import pandas as pd
# Load data from a CSV file into a DataFrame
df = pd.read_csv('your_file.csv')1.2 Acceso a datos de columna
Una vez cargado, hay varias formas de acceder a los datos en el DataFrame. Puede acceder a los datos de la columna utilizando el nombre de la columna. Por ejemplo, el código a continuación accede a los datos de una columna llamada 'data':
# Access data from a column named 'data'
column_data = df['data']# Access data from a column named 'data'
column_data = df['data']1.3 Acceso a los datos de la fila
De manera similar, también puede acceder a los datos de fila utilizando índices de fila o condiciones:
# Accesses the first row of the DataFrame
row_data = df.loc[0]# Accesses the first row of the DataFrame
row_data = df.loc[0]2. Manejo de valores nulos en DataFrames
Un problema común en el análisis de datos es lidiar con los valores nulos. Pandas proporciona métodos robustos para manejarlos. El código llena los valores nulos con un valor específico, o puede eliminar filas o columnas con nulos. Aquí hay un ejemplo de código de cómo llenar los valores nulos:
# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)# Fill null values in the DataFrame with 0
df.fillna(0, inplace=True)3. Creación y manipulación de columnas
Los DataFrames son versátiles al permitir la creación de nuevas columnas. Ya sea una nueva columna entera o una columna derivada de los datos existentes, el proceso es simple. Aquí hay un ejemplo de cómo agregar una nueva columna a un DataFrame:
# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10# Add a new column 'new_column' by multiplying an existing column by 10
df['new_column'] = df['existing_column'] * 10También puede filtrar datos basándose en condiciones. Por ejemplo, si desea crear una nueva columna con datos de una columna llamada 'column_named_data' mayor que un cierto valor:
# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]# Create a new column 'filtered_data' based on the condition
df['filtered_data'] = df[df['column_named_data'] > value]Técnicas avanzadas de manipulación de datos
1. Agrupación y agregación de datos
Pandas se destaca en la agrupación y agregación de datos. El siguiente código usa el método groupby y agrupa los datos por una columna especificada y calcula funciones agregadas como la media, la suma, etc.:
# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()# Group data by 'column_name' and calculate the mean
grouped_data = df.groupby('column_name').mean()2. Datos de fecha y hora
Manejar fechas y horas es crucial en muchos conjuntos de datos. Si su DataFrame tiene una columna de fecha, Pandas simplifica tareas como filtrar por fecha, agregar por mes o año, etc. Aquí hay un ejemplo básico:
# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])# Convert 'date_column' to datetime format
df['date_column'] = pd.to_datetime(df['date_column'])3. Manipulaciones de datos personalizadas
Para necesidades más complejas de manipulación de datos, Pandas le permite escribir funciones personalizadas y aplicarlas a su DataFrame. Esto es particularmente útil para escenarios que requieren un enfoque de consulta integrado en el lenguaje.
def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)def custom_function(row):
# Perform custom manipulation on each row
return modified_row
# Apply custom function to each row in the DataFrame
df = df.apply(custom_function, axis=1)Visualización y visualización de datos
Pandas se integra bien con bibliotecas como Matplotlib y Seaborn para la visualización de datos. Mostrar datos en un formato visual puede ser tan simple como se muestra en el siguiente código fuente:
import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()import matplotlib.pyplot as plt
# Plot a bar chart for data visualization
df.plot(kind='bar')
plt.show()Integración de IronPDF con Pandas para mejorar el análisis de datos en Python
Pandas, como hemos discutido, es una herramienta robusta para la manipulación y análisis de datos en Python. Complementando sus capacidades, IronPDF, una biblioteca desarrollada por Iron Software, ofrece funcionalidades adicionales que pueden elevar los flujos de trabajo de análisis de datos, especialmente al tratar con contenido PDF.
IronPDF: Una visión general
IronPDF es una biblioteca PDF for Python versátil para crear, editar y extraer contenido PDF dentro de proyectos de Python. Está diseñada para funcionar en varias plataformas, incluyendo Windows, Mac, Linux, y entornos en la nube, lo que la convierte en una opción adecuada para diversos proyectos de Python. Esta biblioteca es particularmente poderosa en el manejo de archivos PDF, ofreciendo una experiencia fluida y un procesamiento eficiente, lo que es crucial para desarrolladores que trabajan con datos en PDF.
Sinergia con Pandas
La integración de IronPDF con Pandas abre posibilidades para un manejo de datos más avanzado y reportes. Imagine un flujo de trabajo de análisis en el que utiliza Pandas para la manipulación y análisis de datos, y luego convierte sin problemas sus resultados y visualizaciones en un informe PDF con formato profesional utilizando IronPDF. Esta integración puede simplificar significativamente el proceso de compartir y presentar los resultados del análisis de datos.
Conclusión
En conclusión, mientras que Pandas proporciona la base para el análisis de datos, la integración de IronPDF añade una nueva dimensión al flujo de trabajo de análisis de datos en Python. Esta combinación no solo mejora la eficiencia de los procesos de manipulación y análisis de datos, sino que también mejora significativamente la manera en que los datos se presentan y comparten, convirtiéndola en un activo invaluable para analistas y científicos de datos basados en Python.
IronPDF para usuarios interesados en explorar sus características antes de realizar una compra.
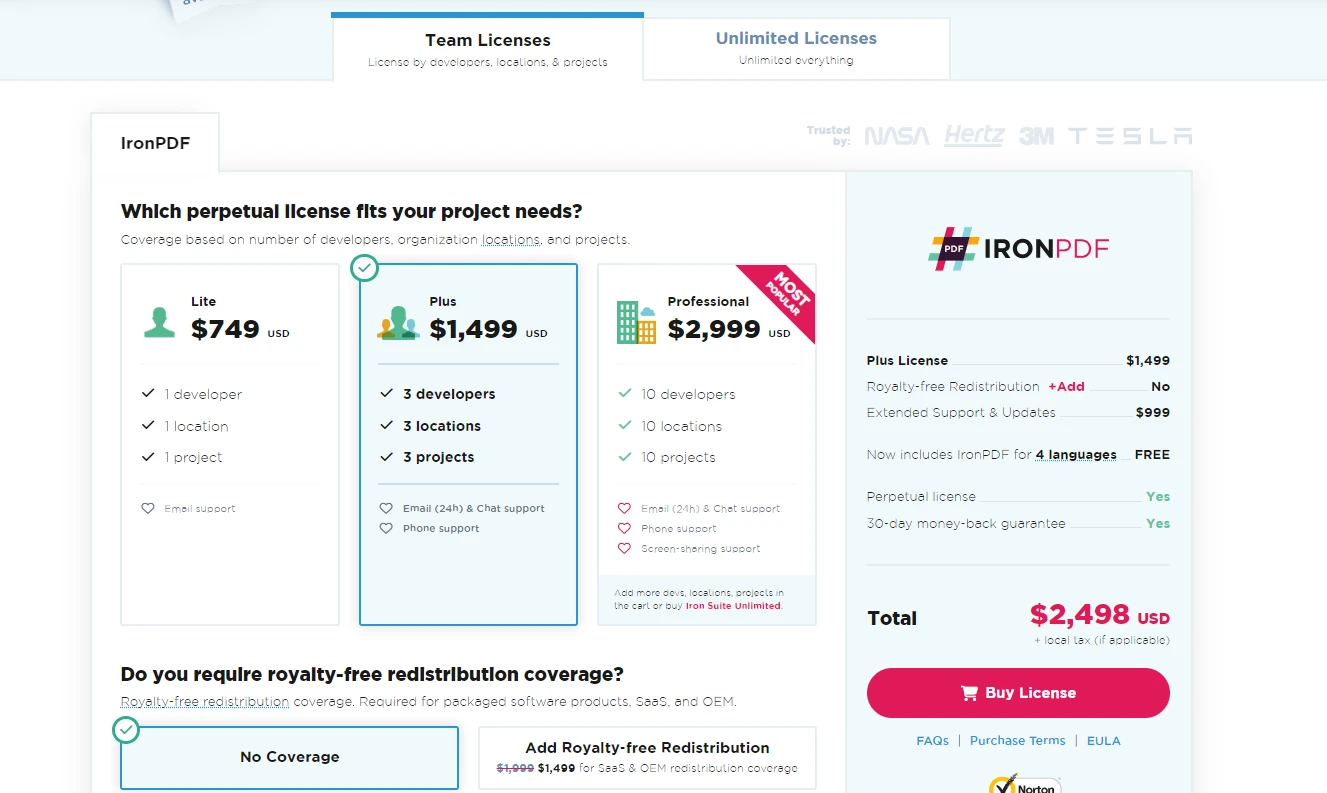
Para aquellos que buscan adquirir una licencia completa, IronPDF permite a los usuarios elegir un plan que mejor se adapte a las necesidades y presupuesto de su proyecto.
















