
Cómo Agregar o Quitar Páginas de PDF Usando Python
Este artículo demostrará cómo agregar o eliminar páginas de PDF usando Python y una biblioteca de PDF llamada IronPDF for Python.
1. IronPDF for Python
IronPDF es una biblioteca líder de PDF for Python que ofrece a los desarrolladores la capacidad de generar, manipular y trabajar con documentos PDF en sus aplicaciones sin esfuerzo. Con IronPDF, los desarrolladores pueden integrar sin problemas la funcionalidad PDF en sus proyectos de Python, ya sea para crear informes dinámicos, generar facturas o convertir contenido web en archivos PDF. Esta biblioteca ofrece una forma fácil de usar y eficiente de manejar tareas relacionadas con PDF, permitiéndote crear y manipular PDFs con facilidad.
Ya sea que estés construyendo aplicaciones web, software de escritorio o automatizando flujos de trabajo de documentos, IronPDF es una herramienta valiosa que te permite trabajar con PDFs en el entorno Python, siendo una adición esencial al conjunto de herramientas de cualquier desarrollador. Esta guía introductoria explorará las características y capacidades clave de IronPDF for Python. Usando IronPDF, los desarrolladores pueden combinar varios archivos PDF en un solo documento, extraer texto de una página en particular, agregar marcas de agua, y realizar otras operaciones como eliminar páginas, eliminar una página en blanco, rotar páginas, agregar páginas y leer archivos PDF.
2. Instalación de IronPDF
Para instalar IronPDF, solo abre PyCharm o cualquier otro compilador de Python, y crea un nuevo proyecto de Python o abre uno existente. Una vez creado o abierto el proyecto, abre el terminal.
IronPDF for Python se puede instalar fácilmente usando el comando del terminal. Simplemente ejecuta el siguiente comando en el terminal, y IronPDF debería estar instalado en un minuto.
pip install ironpdf
 Instalar paquete de IronPDF
Instalar paquete de IronPDF
Una vez que la instalación se complete, estarás listo para comenzar a jugar con el código.
3. Ejemplos de código
Antes de agregar y eliminar páginas de PDF de un documento PDF, vamos a crear un archivo PDF simple de 4 páginas usando conversión de HTML a PDF. El código a continuación crea archivos PDF para usarlos como un documento PDF de entrada para los próximos ejemplos de código.
from ironpdf import *
# HTML content to be converted to PDF
html = """
<p> Hello Iron</p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 4th Page</p>
"""
# Initialize the renderer
renderer = ChromePdfRenderer()
# Render the HTML as a PDF document
pdf = renderer.RenderHtmlAsPdf(html)
# Save the PDF to a file
pdf.SaveAs("Page1And4.pdf")from ironpdf import *
# HTML content to be converted to PDF
html = """
<p> Hello Iron</p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 4th Page</p>
"""
# Initialize the renderer
renderer = ChromePdfRenderer()
# Render the HTML as a PDF document
pdf = renderer.RenderHtmlAsPdf(html)
# Save the PDF to a file
pdf.SaveAs("Page1And4.pdf")Este código Python usa la biblioteca IronPDF para crear un documento PDF a partir de contenido HTML. El contenido HTML se define como una cadena, que contiene párrafos y etiquetas div de "page-break-after", indicando saltos de página. Está estructurado para tener cuatro páginas. Luego, el código utiliza ChromePdfRenderer para convertir este HTML en un documento PDF. Finalmente, guarda el PDF resultante como "Page1And4.pdf".
Esencialmente, este código genera un PDF con varias páginas, donde cada página corresponde al contenido entre dos etiquetas "page-break" consecutivas en el HTML, y guarda este contenido HTML en un archivo PDF.
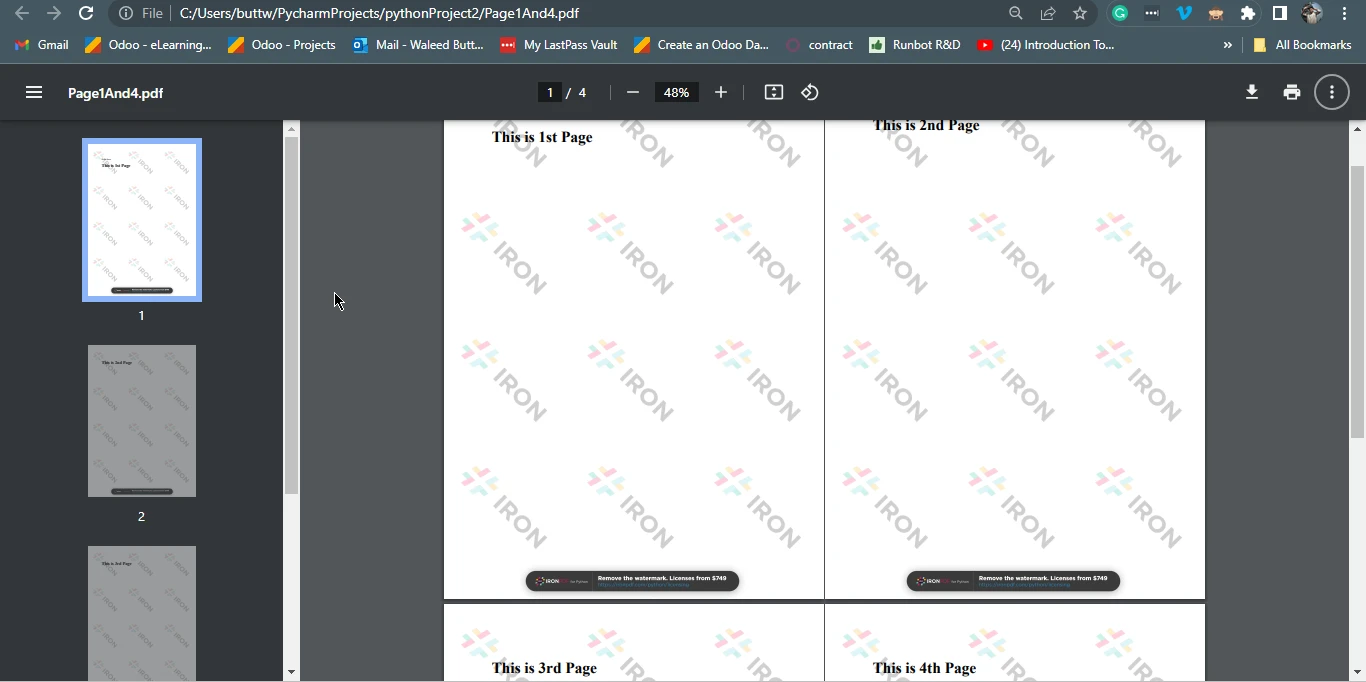 Page1And4.pdf
Page1And4.pdf
3.1. Eliminación de una página específica de archivos PDF utilizando IronPDF
Esta sección eliminará páginas de un PDF creado anteriormente. El siguiente código eliminará una página del archivo PDF.
from ironpdf import *
# Load the existing PDF document
pdf = PdfDocument.FromFile("Page1And4.pdf")
# Remove the page at index 1 (second page)
pdf.RemovePage(1)
# Save the modified PDF to a new file
pdf.SaveAs("removed.pdf")from ironpdf import *
# Load the existing PDF document
pdf = PdfDocument.FromFile("Page1And4.pdf")
# Remove the page at index 1 (second page)
pdf.RemovePage(1)
# Save the modified PDF to a new file
pdf.SaveAs("removed.pdf")El código anterior utiliza la biblioteca IronPDF para manipular un documento PDF. Comienza importando los componentes necesarios y luego carga un documento PDF existente llamado "Page1And4.pdf" utilizando el método FromFile(). Procede a eliminar una página del PDF, identificada por su índice '1', y posteriormente llama al método SaveAs que guarda el documento modificado como un nuevo archivo PDF llamado removed.pdf. En esencia, el código realiza la tarea de eliminar la segunda página del documento PDF original y guardar el documento resultante como un archivo separado.
3.1.1. Archivo PDF de salida
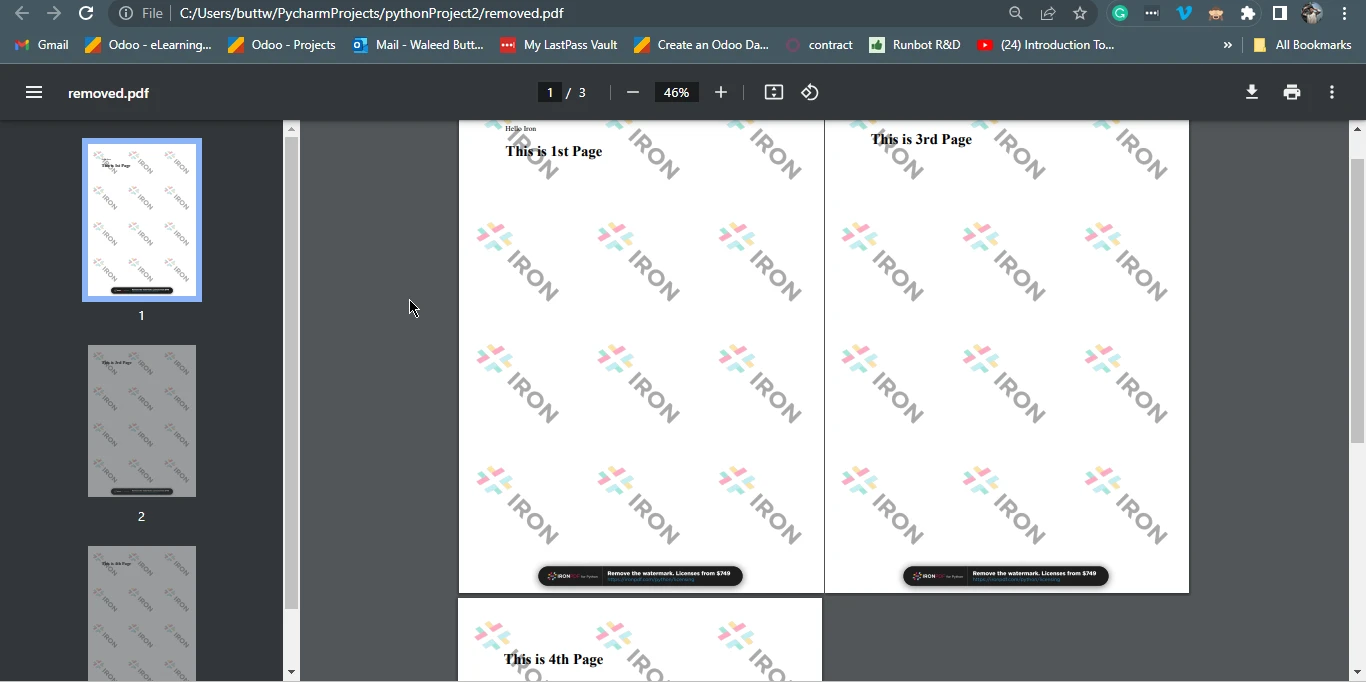 Archivo de Salida
Archivo de Salida
3.2. Añadir una página en un documento PDF usando IronPDF
Esta sección discutirá cómo agregar una nueva página en archivos PDF existentes. Para esto, vamos a crear un nuevo archivo PDF y luego agregar el PDF recién creado al archivo PDF creado anteriormente usando números de página con solo unas pocas líneas de código.
A continuación se presenta un ejemplo de código de cómo agregar una nueva página de PDF en el documento original.
from ironpdf import *
# HTML content to represent a new page
pdf_page = """
<h1> Cover Page</h1>
"""
# Initialize the renderer and render the new PDF page
renderer = ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(pdf_page)
# Load the existing PDF file
pdf = PdfDocument.FromFile("removed.pdf")
# Prepend the new page to the beginning of the existing PDF
pdf.PrependPdf(pdfdoc_a)
# Save the combined PDF to a new file
pdf.SaveAs("addPage.pdf")from ironpdf import *
# HTML content to represent a new page
pdf_page = """
<h1> Cover Page</h1>
"""
# Initialize the renderer and render the new PDF page
renderer = ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(pdf_page)
# Load the existing PDF file
pdf = PdfDocument.FromFile("removed.pdf")
# Prepend the new page to the beginning of the existing PDF
pdf.PrependPdf(pdfdoc_a)
# Save the combined PDF to a new file
pdf.SaveAs("addPage.pdf")Este fragmento de código Python aprovecha la biblioteca IronPDF para manipular documentos PDF. Inicialmente, define un fragmento de contenido HTML que representa una página de portada con un título. Luego, emplea el método ChromePdfRenderer() para convertir este HTML en un documento PDF, almacenándolo en pdfdoc_a.
Luego, carga un documento PDF existente, "removed.pdf", usando PdfDocument.FromFile("removed.pdf"). El código procede a anteponer el contenido de pdfdoc_a a este PDF existente usando el método pdf.PrependPdf(pdfdoc_a). Esencialmente, este código combina el PDF de la portada con el "removed.pdf", creando un nuevo documento PDF llamado "addPage.pdf", agregando efectivamente la portada al comienzo del PDF original.
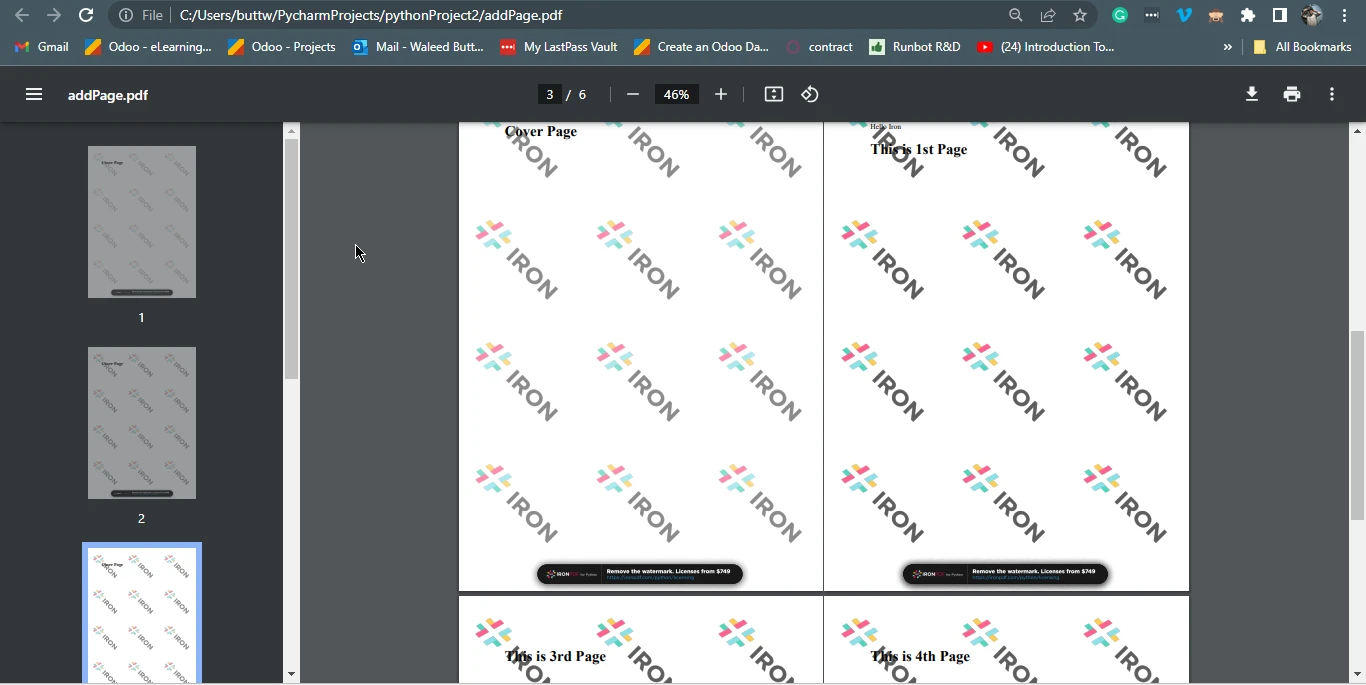 Archivo de Salida
Archivo de Salida
4. Conclusión
Este artículo exploró el mundo de la manipulación de PDF usando Python, con un enfoque en la biblioteca IronPDF. La capacidad de agregar o eliminar páginas de documentos PDF es una habilidad valiosa en el entorno digital actual, y Python ofrece una manera accesible y poderosa para lograr estas tareas. El artículo cubrió los pasos esenciales para instalar IronPDF y proporcionó ejemplos de código para ilustrar el proceso de crear, eliminar y agregar páginas en PDFs.
Con IronPDF, los desarrolladores de Python pueden trabajar de manera eficiente con documentos PDF, ya sea para generar informes, personalizar contenido o mejorar los flujos de trabajo de documentos. A medida que el mundo digital continúa dependiendo de los PDFs para diversos propósitos, dominar estas técnicas permite a los desarrolladores satisfacer una amplia gama de necesidades, haciendo de Python e IronPDF una combinación dinámica para la manipulación de PDFs.
El ejemplo de código de la eliminación de páginas de PDF se puede encontrar en el siguiente código de ejemplo. El ejemplo de código para agregar páginas de PDF se puede encontrar en otro ejemplo de código Python. Además, si tienes curiosidad sobre cómo funciona la conversión de HTML a PDF, por favor visita esta página de tutoriales.
Explora las versátiles características de la biblioteca IronPDF for Python y experimenta la transformación optando por una prueba gratuita hoy.
Preguntas Frecuentes
¿Cómo puedo agregar una nueva página de portada a un PDF en Python?
Puedes agregar una nueva página de portada a un documento PDF en Python usando el ChromePdfRenderer de IronPDF para crear una nueva página a partir de contenido HTML. Luego, usa el método PrependPdf para añadir esta nueva página al frente de un documento PDF existente.
¿Qué pasos están involucrados en eliminar una página de un PDF usando IronPDF?
Para eliminar una página de un PDF usando IronPDF, primero carga tu PDF usando PdfDocument.FromFile. Identifica la página que deseas eliminar por su índice y usa el método RemovePage para eliminarla.
¿Puedo combinar múltiples archivos PDF usando una biblioteca PDF en Python?
Sí, con IronPDF for Python, puedes combinar fácilmente múltiples archivos PDF en un solo documento usando métodos como MergePdf que combinen PDFs sin problemas.
¿Qué características ofrece IronPDF para editar PDFs en Python?
IronPDF ofrece una variedad de características para editar PDFs, como agregar y eliminar páginas, combinar documentos, extraer texto, agregar marcas de agua y rotar páginas, lo que lo convierte en una herramienta integral para la manipulación de PDF.
¿Cómo convierto contenido HTML a un documento PDF usando IronPDF?
Para convertir contenido HTML en un documento PDF usando IronPDF, utiliza el método RenderHtmlAsPdf, que procesa cadenas HTML y las produce como archivos PDF.
¿Hay una versión de prueba disponible para la biblioteca IronPDF?
Sí, hay una prueba gratuita de IronPDF disponible, lo que permite a los usuarios explorar las características y capacidades de la biblioteca en el manejo de documentos PDF dentro de aplicaciones Python.
¿Qué tipos de aplicaciones pueden beneficiarse de la manipulación de PDF usando IronPDF?
Las aplicaciones que van desde plataformas web hasta software de escritorio pueden beneficiarse de la manipulación de PDF usando IronPDF. Soporta tareas como generar informes, automatizar flujos de trabajo de documentos y personalizar contenido de PDF.
¿Dónde puedo encontrar ejemplos de código Python para agregar o eliminar páginas de PDF?
Los ejemplos de código para agregar o eliminar páginas de PDF usando IronPDF se pueden encontrar en el artículo en el sitio web de IronPDF, que proporciona fragmentos de código Python prácticos para estas operaciones.
¿Por qué es importante gestionar páginas de PDF en flujos de trabajo digitales?
Gestionar páginas de PDF es crucial en flujos de trabajo digitales para personalizar la disposición de documentos, eliminar contenido innecesario y automatizar la generación de informes, lo que mejora la eficiencia y adaptabilidad de la gestión documental.
















