
Cómo Extraer Imágenes De Un PDF en Python
Este artículo usará IronPDF for Python para extraer imágenes de un archivo PDF usando código Python.
IronPDF for Python
IronPDF for Python es una biblioteca de vanguardia y potente que aporta una nueva dimensión al manejo de documentos PDF en Python. Como solución integral para tareas de PDF, IronPDF permite una integración perfecta de funciones avanzadas de PDF en aplicaciones.
IronPDF proporciona una amplia gama de herramientas y API para tareas como crear PDFs desde cero, convertir HTML en PDFs de alta calidad y gestionar páginas PDF a través de acciones como combinar, dividir y editar. Estas herramientas son fáciles de usar y eficientes. Con su interfaz fácil de usar y extensa documentación, IronPDF desbloquea posibilidades para los desarrolladores.
Ya sea creando informes profesionales y facturas, automatizando flujos de trabajo o gestionando documentos, IronPDF proporciona un activo valioso en el ámbito de la gestión y automatización de documentos, convirtiéndolo en una herramienta esencial para cualquier desarrollador que busque aprovechar el poder de los PDFs en aplicaciones Python.
Cómo extraer imágenes de un PDF con IronPDF for Python
- Instala la biblioteca IronPDF para extraer imágenes de PDFs en Python.
- Utilice el método
PdfDocument.FromFilepara cargar un archivo PDF utilizando una ruta de archivo del disco local. - Aplique el método
ExtractAllImagespara extraer imágenes de archivos PDF. - Usa un bucle para iterar a través de todas las imágenes extraídas encontradas en el PDF.
- Guarda estas imágenes extraídas del archivo PDF con la extensión de imagen requerida.
Requisitos previos
Antes de adentrarse en el mundo de obtener imágenes de PDF usando Python, instalemos los requisitos necesarios:
- Instalación de Python: asegúrese de tener un intérprete de Python instalado en su sistema. El proceso de obtención de imágenes de PDF requerirá Python 3.0 o versiones más nuevas. Asegúrate de tener una instalación de Python compatible.
Biblioteca IronPDF : para utilizar las potentes capacidades de IronPDF , deberá instalarlo utilizando
pip, el administrador de paquetes de Python. Simplemente abre tu interfaz de línea de comandos y ejecuta el siguiente comando:pip install ironpdfpip install ironpdfSHELL- Entorno de Desarrollo Integrado (IDE): Aunque no es obligatorio, usar un IDE puede mejorar en gran medida tu experiencia de desarrollo. Los IDEs ofrecen características como la autocompletación de código, depuración y un flujo de trabajo más optimizado. Un IDE muy popular para el desarrollo en Python es PyCharm. Puedes descargar e instalar PyCharm desde el sitio web de JetBrains.
Una vez que estos requisitos estén en su lugar, puedes explorar la guía paso a paso a través del emocionante mundo de la recuperación de imágenes de PDFs usando Python e IronPDF.
Paso 1: Creación de un nuevo proyecto Python
Aquí están los pasos para crear un nuevo Proyecto Python en PyCharm.
- Para iniciar un nuevo proyecto Python en PyCharm, abre la aplicación PyCharm y navega al menú superior.
Haz clic en Archivo y selecciona Nuevo Proyecto del menú desplegable.
 PyCharm IDE
PyCharm IDE- Después de hacer clic en Nuevo Proyecto, aparecerá una nueva ventana con el título Crear Proyecto.
En esta ventana, introduce el nombre de tu proyecto en el campo Ubicación en la parte superior. Elije el entorno; si estás usando un entorno virtual, selecciónalo de las opciones proporcionadas.
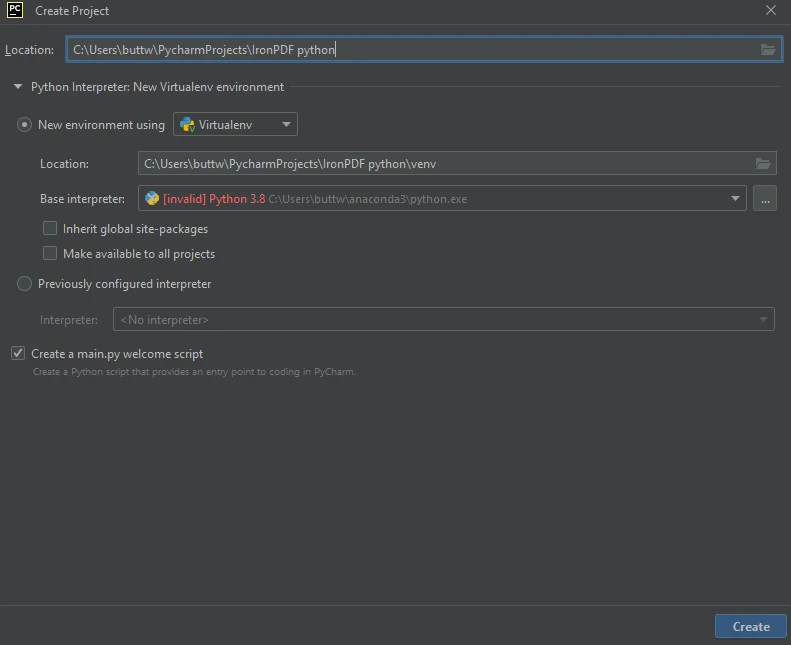 Crear un nuevo proyecto Python en PyCharm
Crear un nuevo proyecto Python en PyCharm- Una vez seleccionado el entorno, haz clic en el botón Crear para crear tu proyecto Python.
Tu proyecto Python está ahora creado y listo para ser usado en varias tareas, como extraer imágenes.
Paso 2 Instalación de IronPDF
Para instalar IronPDF, abra la terminal o un símbolo del sistema separado e ingrese el comando pip install ironpdf, luego presione la tecla Enter . El terminal mostrará la siguiente salida.
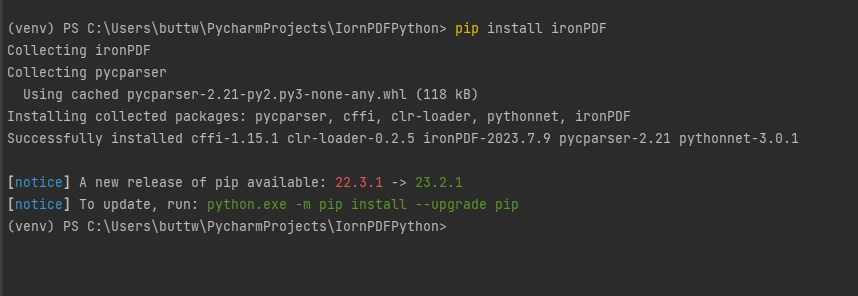 Instalar paquete de IronPDF
Instalar paquete de IronPDF
Paso 3 Extracción de imágenes de archivos PDF con IronPDF
IronPDF capacita a los desarrolladores con herramientas y APIs para navegar por PDFs e identificar y extraer imágenes integradas sin problemas. Ya sea para análisis o integración, IronPDF simplifica la extracción usando la flexibilidad de Python. Esto lo hace esencial para trabajar en PDFs y aplicaciones basadas en imágenes. Puede extraer todas las imágenes de un archivo PDF, lo cual es notablemente simple con solo unas pocas líneas de código.
Consulta el siguiente código para extraer imágenes de PDFs usando el lenguaje de programación Python.
from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")from ironpdf import PdfDocument
# Open PDF file
pdf = PdfDocument.FromFile("FYP Thesis.pdf")
# Get all images found in the PDF Document
all_images = pdf.ExtractAllImages()
# Save each image to the local disk with a dynamic name
for i, image in enumerate(all_images):
image.SaveAs(f"output_image_{i}.png")Este código primero importa la biblioteca IronPDF y luego carga el archivo PDF desde el espacio local utilizando la ruta del archivo con el método PdfDocument.FromFile. Accede a cada página del PDF para extraer los bytes de imagen como objetos de Imagen. Luego, estos objetos de imagen de páginas PDF se guardan utilizando el método SaveAs. El código asigna nombres de imágenes dinámicos basados en los índices de las imágenes y la extensión del archivo de imagen deseada, que es PNG en este ejemplo.
Este enfoque es más simple que usar otras bibliotecas de Python como PyMuPDF y Pillow, que requieren más código para lograr la misma tarea de extraer y guardar archivos de imagen.
Paso 4 Guardar las imágenes del archivo PDF
Las imágenes se extraen de todas las páginas de un archivo PDF y se guardan en formato PNG. También tienes la flexibilidad de modificar el formato de salida ajustando la extensión del archivo para que coincida con los formatos de archivo de imagen deseados.
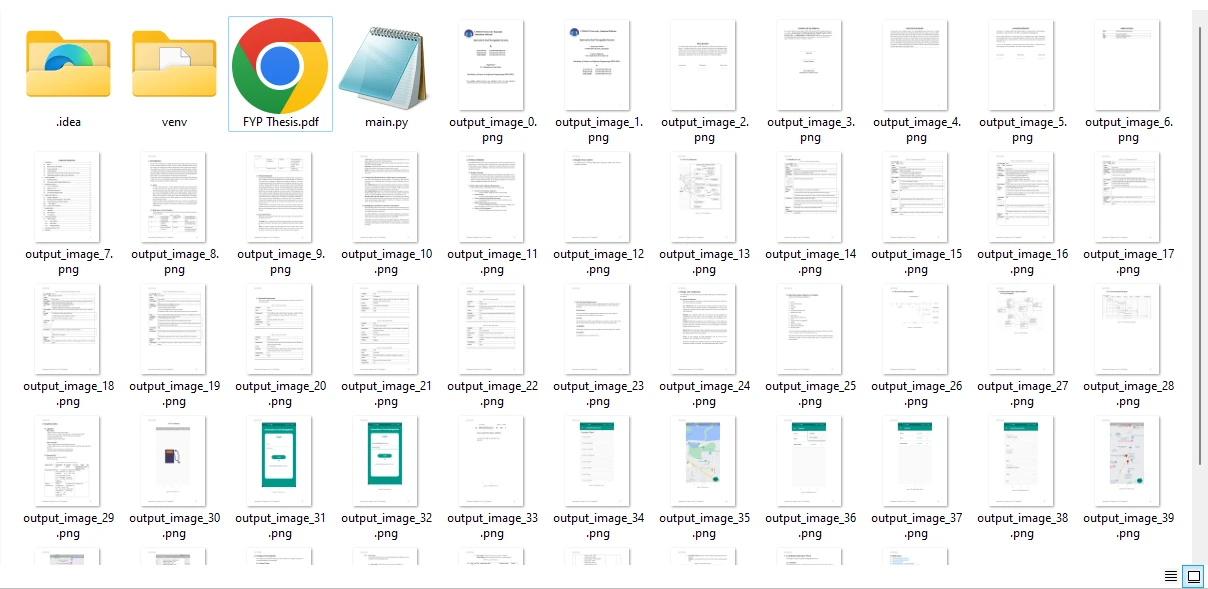 Las imágenes extraídas del archivo PDF de muestra
Las imágenes extraídas del archivo PDF de muestra
Conclusión
Python, junto con el potente IronPDF, ofrece una solución versátil y eficiente para la tarea de recuperar imágenes de archivos PDF. Aprovechando la flexibilidad de Python y las capacidades de IronPDF, los desarrolladores pueden navegar sin problemas por documentos PDF, localizar bytes de imagen dentro de ellos y guardar estas imágenes con la extensión de imagen deseada. El proceso implica obtener imágenes de un PDF, y la lista de imágenes resultante se puede procesar y manipular más según sea necesario. Dominando el arte de adquirir imágenes de PDFs usando Python, los desarrolladores pueden mejorar sus flujos de trabajo, automatizar la gestión de documentos y explorar una amplia gama de aplicaciones basadas en imágenes, lo que lo convierte en una habilidad valiosa en la era digital.
Para más características sobre la extracción de imágenes de archivos PDF, visita el siguiente ejemplo. Puedes explorar otras operaciones como convertir contenidos de archivos PDF a imágenes; el tutorial completo está disponible en este artículo de Python sobre cómo hacerlo.
Preguntas Frecuentes
¿Cómo puedo extraer imágenes de un PDF usando Python?
Puedes extraer imágenes de un PDF usando IronPDF for Python utilizando el método PdfDocument.FromFile para cargar un PDF y el método ExtractAllImages para extraer imágenes.
¿Cuáles son los pasos para guardar imágenes extraídas de un PDF usando Python?
Para guardar las imágenes extraídas, itera a través de las imágenes y usa el método SaveAs para almacenar cada imagen con una extensión de archivo especificada, como PNG.
¿Por qué elegir IronPDF para la extracción de imágenes de PDFs en Python?
IronPDF simplifica el proceso de extracción de imágenes en comparación con otras bibliotecas como PyMuPDF y Pillow, reduciendo la cantidad de código requerido para lograr resultados similares.
¿Cuáles son los requisitos para usar IronPDF en Python para manejar PDFs?
Necesitas tener Python 3.0 o más reciente e instalar la biblioteca IronPDF a través de pip. También es beneficioso usar un IDE como PyCharm para el desarrollo.
¿Cómo instalo IronPDF for Python?
IronPDF se puede instalar usando el gestor de paquetes pip. Ejecuta el comando pip install ironpdf en tu interfaz de línea de comandos.
¿Se puede usar IronPDF para automatizar la gestión de documentos PDF en Python?
Sí, IronPDF permite la automatización de tareas de gestión de documentos como la extracción de imágenes y la conversión de contenidos de PDF, lo que mejora la eficiencia del flujo de trabajo.
¿Qué formatos de imagen son compatibles con IronPDF para guardar imágenes extraídas?
Las imágenes extraídas se pueden guardar en formatos como PNG especificando la extensión de archivo deseada en el método SaveAs.
¿Es IronPDF adecuado para desarrollar aplicaciones basadas en imágenes en Python?
IronPDF es adecuado para desarrollar aplicaciones basadas en imágenes ya que ofrece funciones robustas para extraer y gestionar imágenes dentro de documentos PDF.
















