
Cómo Extraer Tablas De Un PDF en Python
Este artículo demostrará cómo utilizar IronPDF, una potente biblioteca de procesamiento de PDF, para extraer datos sin esfuerzo de tablas complejas en cualquier archivo PDF.
IronPDF
Python proporciona significativamente más flexibilidad para los programadores en comparación con otros lenguajes y permite a los desarrolladores diseñar fácilmente interfaces gráficas de usuario de manera eficiente. Por lo tanto, incorporar la biblioteca IronPDF en Python es un proceso sencillo. Para crear rápidamente una GUI completamente funcional y segura, se puede utilizar una variedad de herramientas preinstaladas, incluyendo PyQt, wxWidgets, Kivy y varios otros paquetes y bibliotecas.
IronPDF simplifica el diseño y desarrollo web en Python. Esto se debe principalmente a la abundancia de marcos de desarrollo web en Python disponibles, como Django, Flask y Pyramid. Algunos sitios web y servicios online destacados que han empleado estos marcos incluyen Reddit, Mozilla y Spotify.
Cómo Extraer Tablas De Un PDF en Python
- Descargar un módulo Python para extraer tablas de PDF
- Utilice el método `FromFile` para importar el archivo PDF
- Extraer texto de las tablas con el método `ExtractAllText`
- Itera a través del texto extraído para dividir las filas
- Genera el texto extraído en la consola o un archivo de texto
Características de IronPDF
A continuación, se presentan algunas características de IronPDF:
- Los archivos PDF se pueden crear desde una variedad de fuentes como HTML, HTML5, ASP, PHP y más. Además, los archivos de imagen se pueden convertir a PDF junto con los archivos HTML.
- IronPDF permite la creación de documentos PDF interactivos. Ofrece características como dividir y combinar archivos PDF, extraer texto e imágenes de archivos PDF, rasterizar páginas PDF en imágenes, convertir PDF a HTML, imprimir archivos PDF, completar y enviar formularios interactivos, y dividir y fusionar archivos PDF.
- Con IronPDF, es posible generar un documento desde una URL. También admite agentes de usuario que inician sesión utilizando formularios de inicio de sesión HTML, proxies, cookies, encabezados HTTP, credenciales especiales de inicio de sesión de red, variables de formulario y agentes de usuario.
- El programa IronPDF permite la inspección y anotación de archivos PDF.
- IronPDF permite la extracción de imágenes de documentos.
- IronPDF proporciona a los usuarios la capacidad de agregar encabezados, pies de página, texto, fotos, marcadores, marcas de agua y más a los documentos.
- Usando IronPDF, se pueden dividir y fusionar páginas en un documento nuevo o existente.
- La conversión de documentos a objetos PDF es posible sin la necesidad de un visor Acrobat.
- IronPDF permite la creación de un documento PDF a partir de un archivo CSS.
- Los documentos se pueden crear utilizando archivos CSS que contienen definiciones de tipo de medio con IronPDF.
Configurar entorno Python
Configuración de Python
Asegúrate de que Python esté instalado en tu computadora. Para descargar y configurar la versión más reciente de Python para tu sistema operativo, dirígete al sitio web oficial de Python. Una vez que Python esté instalado, separa los requisitos para tu proyecto creando un entorno virtual. Con la ayuda del módulo venv, podrás crear y gestionar entornos virtuales para ofrecer a tu proyecto de conversión un espacio de trabajo ordenado y organizado.
Nuevo proyecto en PyCharm
Para este tutorial, se recomienda PyCharm, un IDE para desarrollo en Python.
Después de iniciar el IDE PyCharm, selecciona "Nuevo Proyecto" del menú, como se muestra en la siguiente figura.
 IDE PyCharm
IDE PyCharm
Como se ve en la imagen de abajo, cuando eliges "Nuevo Proyecto," aparecerá una nueva ventana que te permitirá definir la ubicación del proyecto y el entorno de Python.
 Crear un nuevo proyecto en PyCharm
Crear un nuevo proyecto en PyCharm
Tras seleccionar la ubicación y el entorno para el proyecto, haz clic en el botón Crear para iniciarlo. Se pueden abrir archivos de Python en la nueva ventana lanzada para que ingreses tu código. Esta guía utiliza Python 3.9.
 el archivo Python principal
el archivo Python principal
Requisitos de la biblioteca IronPDF
IronPDF for Python se basa en .NET 6.0 como su tecnología central. Por lo tanto, para utilizar IronPDF for Python, tu computadora debe tener instalado el runtime de .NET 6.0. Los usuarios de Linux y Mac pueden necesitar instalar .NET antes de poder utilizar este módulo de Python. Descarga el entorno de ejecución necesario desde Microsoft.
Configuración de la biblioteca IronPDF
Es necesario instalar el paquete ironpdf para poder crear, editar y abrir archivos con la extensión ".pdf". Para instalar el paquete en PyCharm, abre una ventana de terminal y escribe el siguiente comando:
pip install ironpdf
La siguiente captura de pantalla ilustra el proceso de instalación del paquete ironpdf.
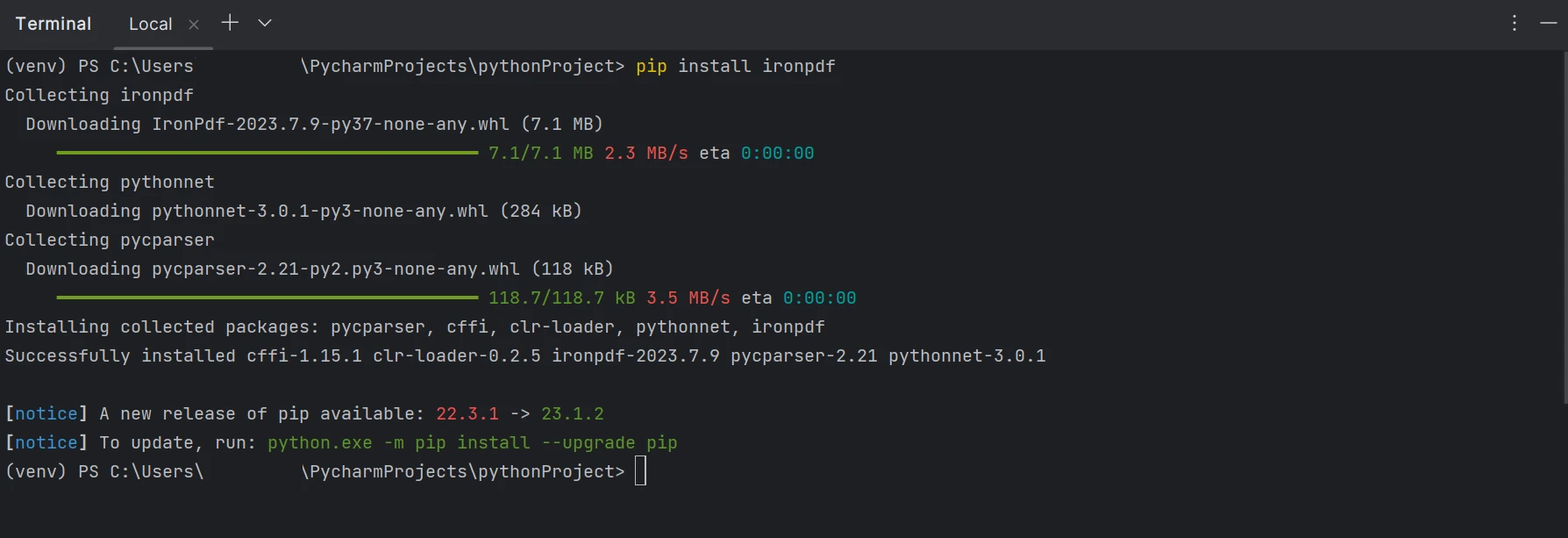 Instalar el paquete IronPDF
Instalar el paquete IronPDF
Extracción de datos de tabla de un archivo PDF
Podemos extraer datos de archivos PDF sin esfuerzo usando la biblioteca IronPDF for Python. IronPDF facilita el análisis de datos de texto y la extracción de tablas de archivos PDF. A continuación, se muestra un código de ejemplo que demuestra cómo extraer datos de tablas PDF, utilizando la imagen proporcionada como referencia.
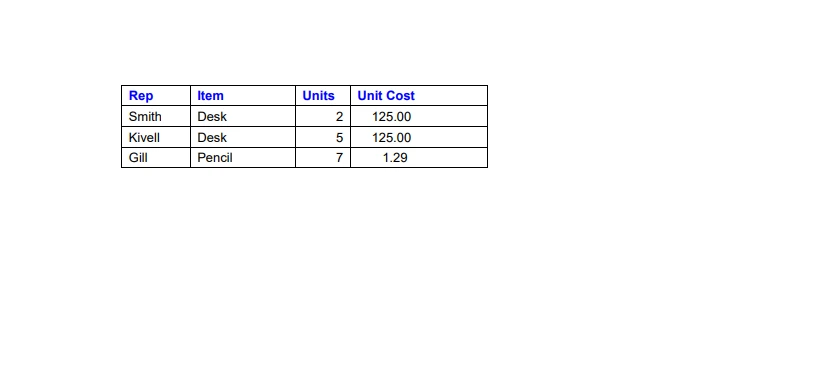 Los datos de muestra de un archivo PDF
Los datos de muestra de un archivo PDF
from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)El código proporcionado demuestra cómo se puede usar IronPDF para extraer tablas de archivos PDF usando solo unas pocas líneas de código Python. Inicialmente, importamos la biblioteca IronPDF para acceder a su funcionalidad y para ganar acceso a todas las características de IronPDF. A continuación, con la ayuda de la clase PdfDocument, se pueden procesar archivos PDF existentes para realizar diversas operaciones en ellos.
Al utilizar la función FromFile, el argumento para cargar el archivo PDF de entrada está disponible. Luego, la función ExtractAllText extrae todos los datos de la tabla de todas las páginas dentro de los archivos PDF. Luego, se utiliza la función split para dividir los datos de la tabla extraídos en varias filas y mostrarlos en la pantalla de la consola.
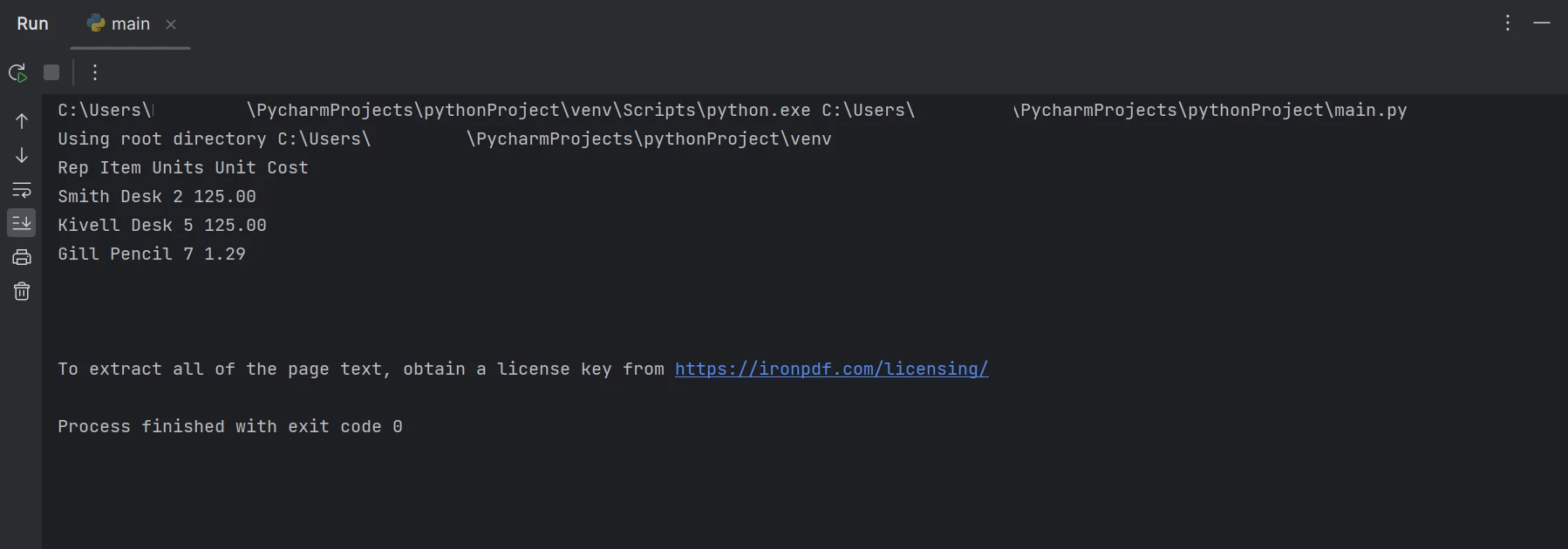 Los datos extraídos
Los datos extraídos
En la salida anterior, los datos se muestran fila por fila, mostrando cómo se pueden extraer los datos de tablas. Aprende más sobre IronPDF consultando la documentación del producto.
Conclusión
La biblioteca IronPDF proporciona medidas de seguridad robustas para minimizar posibles riesgos y asegurar la seguridad de los datos. Es compatible con todos los navegadores populares y no está limitada a ninguno en específico. Con IronPDF, los programadores pueden crear y leer archivos PDF de manera eficiente utilizando solo unas pocas líneas de código. Para satisfacer las diversas necesidades de los desarrolladores, la biblioteca IronPDF ofrece varias opciones de licencias, incluyendo una licencia de desarrollador gratuita y licencias de desarrollo adicionales disponibles para la compra.
El paquete Lite, con un precio de $799, incluye una licencia perpetua, una garantía de devolución de dinero de 30 días, un año de mantenimiento de software y posibilidades de actualización. No hay cargos adicionales después de la compra inicial, y estas licencias se pueden utilizar en entornos de producción, prueba y desarrollo. IronPDF también proporciona licencias gratuitas con algunas limitaciones de tiempo y redistribución. Los usuarios pueden probar el producto en un entorno real con un período de prueba gratuita sin marca de agua. Para información detallada sobre el costo y licenciamiento de la versión de prueba de IronPDF, haga clic en la siguiente página de licenciamiento.
Preguntas Frecuentes
¿Cómo puedo extraer tablas de un PDF en Python?
Para extraer tablas de un PDF usando IronPDF en Python, puedes utilizar el método PdfDocument.FromFile() para cargar el PDF, luego usa ExtractAllText() para extraer el texto. El texto puede ser procesado posteriormente y dividido en filas para recuperar los datos de la tabla.
¿Cuáles son los pasos para configurar el entorno de Python para usar IronPDF?
Para configurar tu entorno de Python para usar IronPDF, asegúrate de tener Python instalado, crea un entorno virtual e instala el runtime de .NET 6.0. Luego puedes instalar IronPDF usando el comando pip install ironpdf.
¿Qué características de manipulación de PDF ofrece IronPDF en Python?
IronPDF ofrece una amplia gama de características de manipulación de PDF en Python, incluyendo la capacidad de crear PDFs a partir de HTML, imágenes y otras fuentes, extraer texto e imágenes, y crear PDFs interactivos con anotaciones, encabezados, pies de página y marcas de agua.
¿Puedo convertir HTML a PDF usando IronPDF en Python?
Sí, IronPDF te permite convertir HTML a PDF en Python. Puedes renderizar cadenas de HTML o archivos como PDFs usando los métodos de IronPDF, facilitando la creación de documentos PDF a partir de contenido web.
¿Qué opciones de licencia están disponibles para IronPDF en Python?
IronPDF ofrece varias opciones de licencia, incluyendo una licencia de desarrollador gratuita para pruebas, un paquete Lite con una licencia perpetua, y paquetes adicionales de licencia a la venta, respaldados por una garantía de devolución de dinero de 30 días.
¿Cómo soluciono problemas comunes al extraer tablas de PDF usando IronPDF?
Para solucionar problemas de extracción con IronPDF, asegúrate de que tu entorno de Python esté configurado correctamente con todas las instalaciones necesarias. Verifica que el archivo PDF sea accesible y revisa la sintaxis de tu código para usar los métodos PdfDocument.FromFile() y ExtractAllText(). Consulta la documentación de IronPDF para más orientación.
¿Qué características de seguridad ofrece IronPDF para el manejo de PDFs?
IronPDF incorpora robustas características de seguridad para el manejo de PDFs, como protección por contraseña y encriptación, asegurando que tus documentos estén seguros durante el procesamiento y distribución.
¿Existe soporte para extraer imágenes de PDFs usando IronPDF en Python?
Sí, IronPDF soporta la extracción de imágenes de PDFs en Python, permitiéndote aislar y guardar imágenes de documentos PDF como parte de tus tareas de procesamiento de datos.
¿Cuál es el IDE recomendado para el desarrollo en Python con IronPDF?
PyCharm es recomendado para el desarrollo en Python con IronPDF, ya que ofrece un completo IDE con características avanzadas para codificación, depuración y gestión efectiva de proyectos en Python.
















