
Cómo Leer PDFs Escaneados en Python
En la era de la transformación digital, la indispensabilidad de los documentos PDF para compartir y preservar información no puede ser exagerada.
Sin embargo, la prevalencia de PDFs escaneados, que a menudo contienen imágenes en lugar de texto buscable, presenta un desafío significativo al extraer datos valiosos.
Aquí es donde Python surge como una solución versátil y potente, estableciéndose como un lenguaje de programación ideal para automatizar diversas tareas, siendo la extracción de información de documentos escaneados un ejemplo destacado.
La flexibilidad y las robustas capacidades de Python empoderan a los usuarios para navegar eficientemente a través de las complejidades del contenido escaneado, proporcionando un enfoque simplificado para acceder y utilizar los datos de PDFs basados en imágenes.
Python es uno de los lenguajes de programación más utilizados por su avanzada funcionalidad. Visita la página de Wikipedia de Python para aprender sobre el lenguaje de programación Python y su formato estructurado.
En este artículo, discutiremos cómo leer PDFs escaneados en el lenguaje de programación Python con la ayuda de IronPDF para la Biblioteca de PDF de Python.
Cómo leer PDF escaneados en Python
- Crea un nuevo proyecto en PyCharm.
- Para leer primero el archivo PDF escaneado, instala la Biblioteca PDF de IronPDF.
- Importa las dependencias requeridas.
- Cargue el archivo PDF escaneado utilizando el método
PdfDocument.FromFile. - Extraiga todo el texto del PDF escaneado utilizando el método
ExtractAllText. - Imprima todo el texto del archivo PDF utilizando el método
print().
IronPDF for Python
IronPDF for Python es una biblioteca robusta desarrollada por Iron Software, que permite una integración fluida de capacidades de generación y manipulación de PDF en aplicaciones Python.
Esta herramienta versátil permite a los desarrolladores crear, modificar e interactuar sin esfuerzo con documentos PDF, apoyando tareas como la generación dinámica de informes, la conversión de HTML a PDF y la extracción de contenido de archivos PDF existentes.
Con una API fácil de usar, documentación completa y una gama de características, IronPDF simplifica el proceso de incorporar funcionalidad avanzada de PDF en proyectos Python, convirtiéndolo en un recurso invaluable para desarrolladores que buscan mejorar sus aplicaciones con capacidades de procesamiento de documentos de calidad profesional.
Características de IronPDF
IronPDF for Python viene equipado con una variedad de características que lo convierten en una herramienta poderosa para la generación de PDF y la manipulación de la estructura de archivos de texto.
Algunas de sus características clave incluyen:
- Conversión de HTML a PDF: Convierte contenido HTML, incluidos CSS e imágenes, en documentos PDF de alta calidad, permitiendo a los desarrolladores aprovechar el contenido web existente en sus procesos de generación de PDF y crear archivos PDF buscables.
- Manipulación de Texto e Imágenes: Agrega y manipula fácilmente texto, imágenes y otros elementos dentro de documentos PDF, proporcionando un control detallado sobre el diseño y la apariencia de los PDFs generados.
- Fusión y División de Documentos: Combina múltiples documentos PDF en un solo archivo o divide grandes archivos PDF en archivos más pequeños y manejables, ofreciendo flexibilidad en la organización de documentos.
- Formularios PDF: Crea y completa formularios PDF interactivos programáticamente, facilitando la automatización de tareas relacionadas con formularios en aplicaciones comerciales.
- Características de Seguridad: Implementa cifrado y protección con contraseña para asegurar los documentos PDF, asegurando que la información confidencial permanezca confidencial y protegida contra accesos no autorizados.
- Extracción de Texto: Extrae contenido de texto de documentos PDF para propósitos de análisis o indexación, permitiendo a los desarrolladores trabajar con los datos textuales contenidos dentro de archivos PDF con la capacidad de reconocimiento de texto de IronPDF.
Instalación de IronPDF for Python
Antes de comenzar con el tutorial de código, veamos primero cómo puedes instalar IronPDF for Python.
Primero, asegúrate de que Python esté instalado en el sistema y tengas un buen IDE de Python como PyCharm. Además, PIP debe estar instalado para instalar IronPDF for Python.
- Primero, crea un nuevo proyecto de Python o abre uno existente.
Abre la consola y ejecuta el siguiente comando y presiona enter.
pip install ironpdfpip install ironpdfSHELL
Así de simple, IronPDF for Python está integrado en tu proyecto de Python.
Lectura de archivos PDF escaneados con IronPDF for Python
En esta sección, veremos cómo puedes extraer texto de archivos PDF escaneados usando IronPDF.
from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)from ironpdf import * # Import everything from ironpdf
# Set the license key for IronPDF
License.LicenseKey = "Your License Key"
# Load the scanned PDF document
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Print the extracted text
print(all_text)El ejemplo de código anterior extrae texto de archivos PDF escaneados. A continuación se muestra el desglose del código anterior:
Importa el Módulo IronPDF:
from ironpdf import *from ironpdf import *PYTHONEsta línea importa los módulos y clases necesarios de la biblioteca IronPDF. El asterisco (
*) indica que se deben importar todas las clases y funciones del módulo.Configura la Clave de Licencia:
License.LicenseKey = "Your License Key"License.LicenseKey = "Your License Key"PYTHONEsta línea configura la clave de licencia para IronPDF. Debe reemplazar
"Your License Key"con la clave de licencia real que obtuvo de Iron Software.La clave de licencia es necesaria para usar IronPDF y típicamente se proporciona cuando compras el producto.
Carga un Documento PDF Escaneado:
pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")pdf = PdfDocument.FromFile("C:/Users/buttw/INV_2023_00008.pdf")PYTHONEsta línea carga un documento PDF escaneado ubicado en la ruta de archivo especificada (
"C:/Users/buttw/INV_2023_00008.pdf"). El métodoPdfDocument.FromFilese utiliza para crear un objetoPdfDocumenta partir del archivo dado.Extrae Texto del Documento PDF:
all_text = pdf.ExtractAllText()all_text = pdf.ExtractAllText()PYTHONEsta línea extrae todo el contenido de texto del documento PDF cargado usando el método ExtractAllText de todas las páginas. Luego, el texto extraído se almacena en la variable
all_text.Imprime el Texto Extraído:
print(all_text)print(all_text)PYTHONFinalmente, esta línea imprime el texto extraído en la consola. La variable
all_textcontiene el contenido de texto del documento PDF escaneado.
PDF de entrada
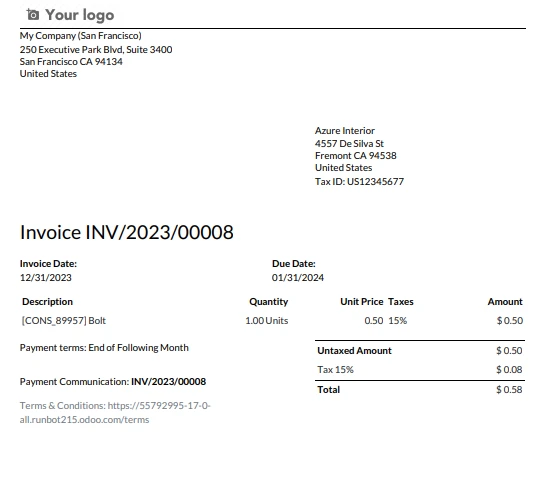
Texto de salida
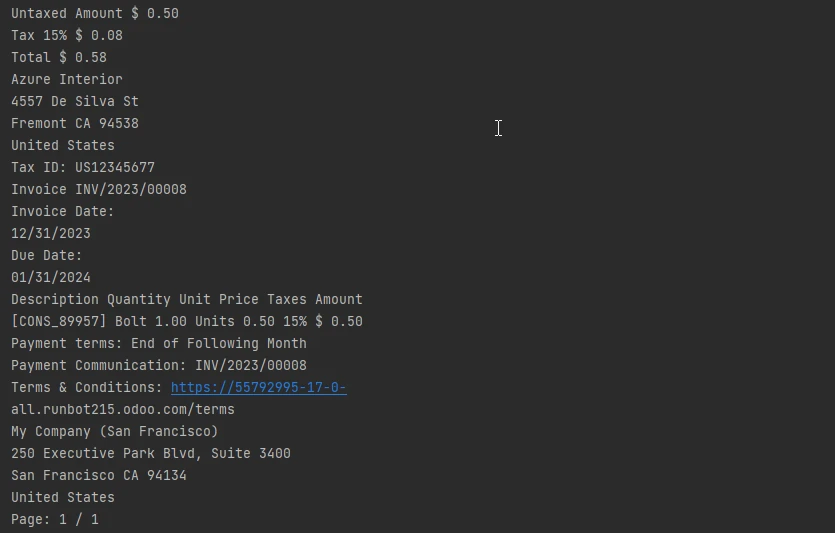
Conclusión
En el ámbito del procesamiento de documentos digitales, el lenguaje de programación Python surge como una solución versátil para superar los desafíos que presentan los PDFs escaneados que contienen imágenes en lugar de texto buscable.
La sinergia entre la flexibilidad de Python y las robustas capacidades de IronPDF for Python ofrece una vía convincente para que los desarrolladores integren sin problemas funcionalidades de generación, manipulación y extracción de PDF en sus proyectos.
IronPDF, desarrollado por Iron Software, resulta instrumental en este sentido, ofreciendo características como la conversión de archivos PDF desde varios tipos de documentos, conversión de página HTML a PDF, manipulación de texto e imágenes, y extracción de texto basada en OCR de PDFs escaneados.
El ejemplo de código mostrado demuestra la implementación simple de IronPDF para leer texto de una página PDF escaneada, mostrando el potencial para una extracción de datos eficiente y mejorando las capacidades de procesamiento de documentos en aplicaciones Python.
A medida que la demanda por un manejo sofisticado de PDFs sigue aumentando, IronPDF for Python se erige como una herramienta valiosa que empodera a los desarrolladores para navegar las complejidades del contenido escaneado con facilidad.
IronPDF for Python ofrece una licencia de prueba, que es una gran oportunidad para que los desarrolladores conozcan las características de IronPDF.
El tutorial completo sobre la extracción de texto de PDFs escaneados se puede encontrar aquí.
Preguntas Frecuentes
¿Cómo puedo leer texto de un PDF escaneado en Python?
Para leer texto de un PDF escaneado en Python, puedes usar las capacidades OCR de IronPDF. Primero, instala IronPDF con pip install ironpdf. Luego, carga tu PDF usando PdfDocument.FromFile y extrae texto con el método ExtractAllText.
¿Qué desafíos presentan los PDFs escaneados para la extracción de texto?
Los PDFs escaneados a menudo almacenan contenido como imágenes, no como texto buscable, requiriendo herramientas especializadas como el OCR de IronPDF para extraer y convertir el texto en un formato manejable.
¿Cómo facilita IronPDF la manipulación de PDFs en Python?
IronPDF ofrece un conjunto de herramientas para la manipulación de PDFs, incluyendo extracción de texto, conversión de HTML a PDF, fusión y división de documentos, y trabajar con formularios PDF interactivos, mejorando las capacidades de manejo de documentos de las aplicaciones Python.
¿Qué se necesita para configurar IronPDF en un entorno Python?
Para configurar IronPDF en Python, asegúrate de que Python y PIP estén instalados en tu sistema. Luego, ejecuta pip install ironpdf para instalar la librería, permitiéndote comenzar a manipular PDFs en tus proyectos Python.
¿Puede IronPDF convertir contenido HTML a PDFs en Python?
Sí, IronPDF puede convertir contenido HTML, incluyendo CSS e imágenes, en documentos PDF de alta calidad, convirtiéndolo en una herramienta versátil para desarrolladores que necesitan generar PDFs a partir de contenido web.
¿Existe una forma de probar IronPDF antes de comprarlo?
IronPDF ofrece una licencia de prueba, que permite a los desarrolladores explorar toda la gama de características, incluido OCR y manipulación de PDFs, antes de decidir comprarlo.
¿Por qué Python es una buena opción para procesar PDFs escaneados?
Python es un idioma preferido para el procesamiento de PDFs escaneados debido a su flexibilidad y la disponibilidad de robustas librerías como IronPDF, que simplifica tareas como la extracción de texto y la manipulación de PDFs.
¿Cuáles son algunas características clave de IronPDF for Python?
Características clave de IronPDF for Python incluyen OCR para PDFs escaneados, conversión de HTML a PDF, fusión y división de documentos, manipulación de texto e imágenes y manejo de formularios interactivos, ofreciendo soluciones integrales de procesamiento de PDFs.
















