body parser node(開発者向けのしくみ)
イベント駆動で非ブロッキングのI/Oアーキテクチャを持つNode.jsは、ChromeのV8 JavaScriptエンジンを基にした強力なJavaScriptランタイムで、サーバーサイドのウェブ開発を完全に変革しました。 Node.jsを使用してHTTPリクエストを迅速に処理する際に、リクエストボディを解析することは重要なステップであり、ウェブ開発や信頼性の高いウェブアプリケーションの開発に必須です。 この場合、body-parserミドルウェアが役立ちます。
Body-parserは、有名なNode.jsフレームワークExpress.js向けのミドルウェアで、ハンドラーを実行する前にリクエストボディを解析するプロセスを簡素化することで、クライアントから送信されたデータへのアクセスと修正を容易にします。 Body-parserミドルウェアは、JSONペイロード、URLエンコードフォーム、または生のテキストなど、さまざまなコンテンツタイプを効率的に処理するための方法を提供し、アプリケーションがユーザー入力を効率的に処理できるようにします。
一方で、IronPDFは、Node.js向けの強力なPDF生成ライブラリです。 開発者は、プログラムを通じてPDFドキュメントを作成、編集、操作することが容易にできます。 body-parserとIronPDFを組み合わせることで、ユーザー入力を処理し、そのデータに基づいて動的なPDFドキュメントを生成するウェブアプリケーションの可能性が広がります。
この記事では、Node.jsでbody-parserを統合してHTTPリクエストを処理し、その後にIronPDFを使用してすでに解析されたボディオブジェクトからPDFドキュメントを生成する方法を探ります。 この組み合わせは、レポートの自動生成、請求書の作成、または動的なPDFコンテンツが必要な状況に特に便利です。
Body Parserの主な機能
JSON解析
リクエストボディをJSON形式で解析し、これらのボディパーサーを使用してAPI内でJSONデータを簡単に処理できます。
URLエンコードデータ解析
HTMLフォーム送信で一般的に見られるURLでエンコードされたデータを解析します。 基本的なオブジェクト構造と高度なオブジェクト構造の両方をサポートしています。
生データ解析
リクエストの生のバイナリデータを解析し、独自のデータ形式や非標準コンテンツタイプを管理するのに役立ちます。
テキストデータ解析
プレーンテキストデータのリクエストを解析し、テキストベースのコンテンツ処理を簡単にします。
構成可能なサイズ制限
リクエストボディサイズ制限を設けることができ、重いペイロードがサーバーに負荷をかけないようにします。 これにより、セキュリティが向上し、リソースの使用を管理できます。
自動コンテンツタイプ検出
コンテンツタイプヘッダーに基づいてリクエストボディを自動的に識別し処理することでさまざまなコンテンツタイプをより効率的に処理し、手動操作の必要性をなくします。
エラーハンドリング
強力なエラーハンドリングにより、無効なメディアフォーマット、誤ったJSON、過度に大きなボディなど、問題を引き起こすリクエストに対してアプリケーションが丁寧に反応できるようにします。
他のミドルウェアとの統合
既存のExpressミドルウェアとのシームレスな統合により、モジュール式で整理されたミドルウェアスタックを可能にします。 これによりアプリケーションの保守性と柔軟性が向上します。
拡張設定オプション
テキスト解析のエンコーディングタイプを変更したり、URLエンコードデータの処理の深さを定義したりするなど、解析プロセスの動作を変更するための設定オプションを提供します。
パフォーマンスの最適化
解析操作を効果的に管理し、パフォーマンスのオーバーヘッドを削減し、負荷が高い状況でもプログラムが応答性を保つことを保証します。
Node.jsでBody Parserを作成および設定する
Express.jsを使ってNode.jsアプリケーションでBody Parserを構築し設定します
ExpressとBody-Parserをインストール
これらのnpmコマンドを使用してExpressとBody-Parserパッケージをコマンドラインでインストールします:
npm install express
npm install body-parsernpm install express
npm install body-parserアプリケーションを作成および設定
プロジェクトディレクトリ内で新しいJavaScriptファイルapp.jsを作成し、Expressアプリケーションに対するbody-parserミドルウェアを設定します:
const express = require('express');
const bodyParser = require('body-parser');
const app = express();
// Use body-parser middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Example route that handles POST requests using the req.body property
app.post('/submit', (req, res) => {
const data = req.body;
res.send(`Received data: ${JSON.stringify(data)}`);
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});const express = require('express');
const bodyParser = require('body-parser');
const app = express();
// Use body-parser middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Example route that handles POST requests using the req.body property
app.post('/submit', (req, res) => {
const data = req.body;
res.send(`Received data: ${JSON.stringify(data)}`);
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});さまざまなコンテンツタイプの処理
さらに、プレーンテキストや生のバイナリ形式のデータを含むさまざまな種類のデータを処理するためにBody Parserを設定できます:
生データ解析
app.use(bodyParser.raw({ type: 'application/octet-stream' }));app.use(bodyParser.raw({ type: 'application/octet-stream' }));テキストデータ解析
app.use(bodyParser.text({ type: 'text/plain' }));app.use(bodyParser.text({ type: 'text/plain' }));エラーハンドリング
エラーハンドリング用のミドルウェアを使用して、ボディ解析中に発生する可能性のある問題を管理できます。
app.use((err, req, res, next) => {
if (err) {
res.status(400).send('Invalid request body');
} else {
next();
}
});app.use((err, req, res, next) => {
if (err) {
res.status(400).send('Invalid request body');
} else {
next();
}
});IronPDFの使い方
IronPDF とは何ですか?
IronPDFを使用すると、開発者はプログラムを介してPDFドキュメントを生成、変更、および操作できます。 IronPDFはNode.js向けの頑丈なPDF生成ライブラリで、スタイリング、スクリプト、複雑なレイアウトを含む複数の機能をサポートしており、HTML素材をPDFへ変換するプロセスを簡素化します。
動的レポート、請求書、その他のドキュメントをウェブアプリケーションから直接生成できます。 Node.jsや他のフレームワークとのシームレスな統合により、PDF機能が必要なすべてのアプリケーションに柔軟なソリューションを提供します。 IronPDFは、その広範な機能セットと使いやすさにより、信頼できるPDFの生成と修正を求める開発者にとって最適なツールです。
IronPDFの主な機能
HTMLからPDFへの変換
HTMLコンテンツをPDFドキュメントに変換する際に、高度なレイアウト、CSS、およびJavaScriptを利用できます。 既存のウェブテンプレートを使用して開発者がPDFを作成できるようにします。
高度なレンダリングオプション
ページ番号、フッター、およびヘッダーのオプションを提供します。 透かし、背景画像、その他の高度なレイアウト要素をサポートしています。
PDFの編集と操作
既存のPDFドキュメントのページ修正、ページのマージ、およびページの分割を可能にします。 PDF内でページを追加、削除、または再配置することを可能にします。
IronPDFのインストール
Node Package Managerを使用してNode.jsに必要なパッケージをインストールし、IronPDFの機能を有効にします。
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfIronPDFでレポートPDFを作成する
Node.jsでIronPDFとBody Parserを組み合わせることで、開発者はリクエストデータを処理し、動的なPDFドキュメントを効率的に生成できます。 これは、Node.jsアプリケーションでこれらの機能を設定し利用するための詳細な手順です。
Body ParserとIronPDFを使用してExpressアプリケーションを構築し、app.jsという名前のファイルを作成します。
const express = require('express');
const bodyParser = require('body-parser');
const IronPdf = require("@ironsoftware/ironpdf");
const app = express();
// Middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Route to handle PDF generation
app.post('/generate-pdf', async (req, res) => {
const data = req.body;
// HTML content to be converted into PDF
const htmlContent = `
<html>
<head></head>
<body>
<h1>${JSON.stringify(data, null, 2)}</h1>
</body>
</html>
`;
try {
// Create an instance of IronPDF document
const document = await IronPdf.PdfDocument.fromHtml(htmlContent);
// Convert to PDF buffer
let pdfBuffer = await document.saveAsBuffer();
// Set response headers to serve the PDF
res.setHeader('Content-Type', 'application/pdf');
res.setHeader('Content-Disposition', 'attachment; filename=generated.pdf');
// Send the PDF as the response
res.send(pdfBuffer);
} catch (error) {
console.error('Error generating PDF:', error);
res.status(500).send('Error generating PDF');
}
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});const express = require('express');
const bodyParser = require('body-parser');
const IronPdf = require("@ironsoftware/ironpdf");
const app = express();
// Middleware to parse JSON and URL-encoded data
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: true }));
// Route to handle PDF generation
app.post('/generate-pdf', async (req, res) => {
const data = req.body;
// HTML content to be converted into PDF
const htmlContent = `
<html>
<head></head>
<body>
<h1>${JSON.stringify(data, null, 2)}</h1>
</body>
</html>
`;
try {
// Create an instance of IronPDF document
const document = await IronPdf.PdfDocument.fromHtml(htmlContent);
// Convert to PDF buffer
let pdfBuffer = await document.saveAsBuffer();
// Set response headers to serve the PDF
res.setHeader('Content-Type', 'application/pdf');
res.setHeader('Content-Disposition', 'attachment; filename=generated.pdf');
// Send the PDF as the response
res.send(pdfBuffer);
} catch (error) {
console.error('Error generating PDF:', error);
res.status(500).send('Error generating PDF');
}
});
// Start the server
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`);
});この構成では、IronPDFを使用してPDFを生成し、Node.js Body Parserの機能を組み合わせています。 まず、PDF生成用のIronPDF、要求ボディ解析のためのBody Parser、サーバー構築のためのExpressなど、必要なモジュールをインポートします。 次に、Body Parserを使用してJSONとURLエンコードフォームデータを解析するためにExpressミドルウェアを設定します。
POSTリクエストを処理するために、generate-pdfというルートを作成し、リクエストボディの内容を受け取ります。 このJSON形式のデータはPDFのコンテンツに使用されるHTMLテンプレートに組み込まれます。 IronPdfを使用してドキュメントをインスタンス化し、HTMLコンテンツをPDFドキュメントに変換します。
PDFが正常に生成されたら、ファイル名とコンテンツタイプを示す適切なヘッダーとともにレスポンスを送信します。 エラーハンドリングにより、PDFの生成時に発生する問題を特定、記録し、関連するステータスコードとともにクライアントに通知します。
出力
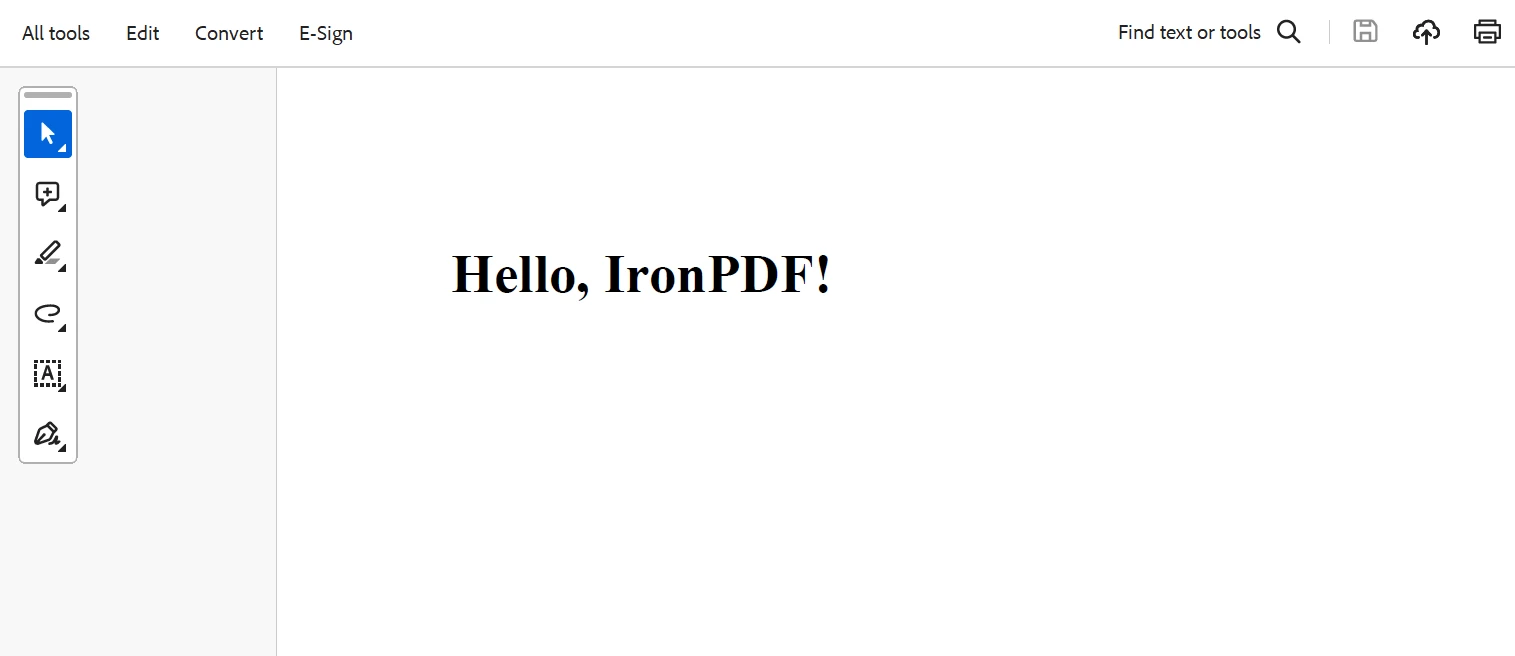
最後に、サーバーが起動し、指定されたポートで受信リクエストを待機します。 この設定により、Body Parserを使用したリクエスト処理とIronPDFによる動的なPDF生成をNode.jsアプリケーションに簡単に統合でき、データ処理とドキュメント生成のためのより効果的なワークフローを実現できます。
結論
要約すると、IronPDFとBody Parserの組み合わせにより、Node.jsでHTTPリクエストボディデータを管理し、オンラインアプリケーションで使用する動的なPDFドキュメントを作成する安定した方法が提供されます。 開発者はBody Parserを利用することで、さまざまな種のリクエストボディを解析するプロセスを簡素化し、受信データに簡単にアクセスし編集できます。
一方で、IronPDFはHTMLテキストからの高度な機能、フォーマット、スタイリングを備えた高品質のPDFドキュメント生成を可能にする強力な機能を持っています。 これらの技術を組み合わせることで、開発者はアプリケーションデータやユーザー入力に基づいて、カスタマイズされたPDFドキュメントを迅速に生成できます。 この統合により、Node.jsアプリは、ユーザー生成コンテンツをより効果的に処理し、プロフェッショナルな外観のPDFを出力できます。
IronPDFとIron Software製品を開発スタックに統合することで、クライアントやエンドユーザーにとって機能が豊富で高品質なソフトウェアソリューションを保証できます。 さらに、これはプロジェクトとプロセスの最適化に貢献します。 Iron Softwareの価格は$799から始まり、広範なドキュメント、活気あるコミュニティ、頻繁なアップグレードにより、現代のソフトウェア開発プロジェクトにおいて頼りになるコラボレーターです。