xml2js npm (開発者向けのしくみ)
開発者は、Node.jsでXML2JSとIronPDFを組み合わせることで、アプリにXMLデータのパースとPDF作成機能を簡単に組み込むことができます。 人気のあるNode.jsパッケージのXML2JSは、XMLデータをJavaScriptオブジェクトに変換することを容易にし、プログラム的な操作やXML素材の利用を促進します。 一方で、IronPDFは、動的に作成された素材を含む
HTMLから、調整可能なページサイズ、余白、ヘッダーを持つ高品質のPDFドキュメントを作成することに特化しています。開発者は、XML2JSとIronPDFの助けを借りて、XMLデータソースから直接PDFレポート、請求書、または他の印刷可能な素材を動的に作成することができます。 この統合では、両方のライブラリの強みを活用して、Node.jsアプリケーションのPDF出力用のXMLベースのデータ管理における正確性と柔軟性を確保しながら、文書生成プロセスを自動化します。
xml2jsとは?
XML2JSというNode.jsパッケージは、XML(拡張可能マークアップ言語)をJavaScriptオブジェクトに変換するための簡単なやり方を提供します。 XMLファイルやテキストを解析し、それらを構造化されたJavaScriptオブジェクトに変換する方法を提供することで、XMLドキュメントの処理を容易にします。 この手続きにより、アプリケーションはXMLの属性のみの管理、テキストコンテンツ、名前空間、属性のマージや属性のキー付け、及びその他のXML固有の性質の管理を選択するオプションを提供し、XMLデータをどのように解釈し利用するかの自由を与えます。
このライブラリは、非ブロッキング解析が必要な状況や巨大なXMLドキュメントのため、同期と非同期解析操作の両方をサポートしています。 さらに、XML2JSは、XMLをJavaScriptオブジェクトに変換する際のエラーの検証と解決機能を提供し、データ処理操作の安定性と信頼性を保証します。 すべてを総合すると、Node.jsアプリケーションはXMLベースのデータソースの統合、ソフトウェアの設定、データフォーマットの変更、及び自動化テスト手順の簡素化のために頻繁にXML2JSを使用します。
次の特徴により、XML2JSはNode.jsアプリケーションでのXMLデータ処理において柔軟で不可欠なツールです:
XML解析
XML2JSを利用することで、開発者はJavaScriptオブジェクトにXML文字列やファイルを処理することで、よく知られたJavaScriptの構文を使用してXMLデータにより迅速にアクセスし操作することができます。
JavaScriptオブジェクト変換
XMLデータを構造化されたJavaScriptオブジェクトにスムーズに変換することで、JavaScriptアプリケーション内でのXMLデータの処理が容易になります。
設定可能オプション
XML2JSはさまざまな設定オプションを提供し、XMLデータがどのようにJavaScriptオブジェクトに解析と変換されるかを調整することが可能です。 これには名前空間、テキストコンテンツ、属性の管理などが含まれます。
双方向変換
双方向変換機能により、JavaScriptオブジェクトをシンプルなXML文字列に再変換するサイクルを可能にします。
非同期解析
ライブラリの非同期解析プロセスのサポートにより、アプリケーションのイベントループに影響を与えることなく大きなXMLドキュメントを効率的に処理できます。
エラーハンドリング
XML2JSは、XMLの解析と変換の過程で発生する可能性のある検証問題や解析エラーを扱うための強力なエラーハンドリング手法を提供します。
Promisesとの統合
JavaScriptのPromisesとよく組み合わさるため、非同期のコードパターンでXMLデータを扱う際に、より明瞭で容易に管理できるようにします。
カスタマイズ可能な解析フック
独自の解析フックを作成することによって、XML解析の振る舞いを補足し変更する特別なオプションを与えることで、データ処理プロセスの柔軟性を高めることができます。
xml2jsの作成と設定
Node.jsアプリケーションでXML2JSを使用するための初期ステップは、ライブラリをインストールし、それを必要に応じて設定することです。 これは、XML2JSの設定と作成手順を示す詳細な方法です。
XML2JS npmのインストール
最初にnpmとNode.jsがインストールされていることを確認します。XML2JSはnpmでインストールできます:
npm install xml2jsnpm install xml2jsXML2JSの基本的な使用法
これは、XML2JSを使用してXMLテキストをJavaScriptオブジェクトに解析するシンプルな例です:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
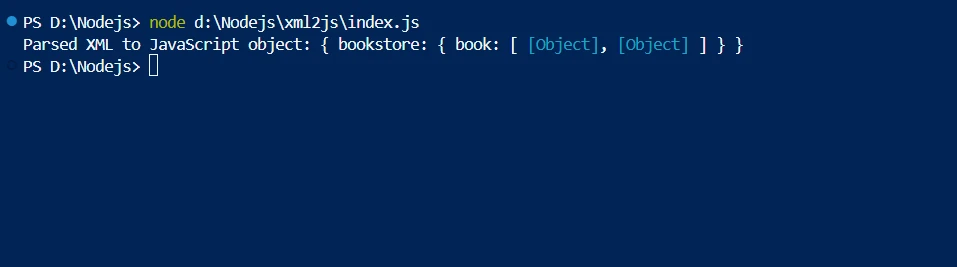
console.log('Parsed XML to JavaScript object:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object:', result);
});
設定オプション
XML2JSは、解析の振る舞いを変更することができる設定オプションやデフォルト設定を様々に提供します。 こちらは、XML2JSにおけるデフォルト解析設定を設定する例です:
const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});const xml2js = require('xml2js');
// Example XML content
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser with options
const parser = new xml2js.Parser({
explicitArray: false, // Converts child elements to objects instead of arrays when there is only one child
trim: true // Trims leading/trailing whitespace from text nodes
});
// Parse XML content
parser.parseString(xmlContent, (err, result) => {
if (err) {
console.error('Error parsing XML:', err);
return;
}
console.log('Parsed XML to JavaScript object with options:', result);
});非同期解析の扱い
XML2JSは非同期解析をサポートしており、これはアプリケーションのイベントループを停止することなく大きなXMLドキュメントを管理するのに便利です。こちらは、XML2JSでasync/await構文を使用する方法の例です:
const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);const xml2js = require('xml2js');
// Example XML content (assume it's loaded asynchronously, e.g., from a file)
const xmlContent = `
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
`;
// Configure XML2JS parser
const parser = new xml2js.Parser();
// Async function to parse XML content
async function parseXml(xmlContent) {
try {
const result = await parser.parseStringPromise(xmlContent);
console.log('Parsed XML to JavaScript object (async):', result);
} catch (err) {
console.error('Error parsing XML (async):', err);
}
}
// Call async function to parse XML content
parseXml(xmlContent);開始方法
Node.jsアプリケーションでIronPDFとXML2JSを使用するには、最初にXMLデータを読み込み、処理されたコンテンツからPDFドキュメントを作成する必要があります。 これらのライブラリをインストールし設定するのを手助けする詳細な方法です。
IronPDF とは何ですか?
IronPDFライブラリは、PDFを扱うための強力なNode.jsライブラリです。 その目標は、HTMLコンテンツを卓越した品質のPDFドキュメントに変換することです。 HTML、CSS、およびその他 for JavaScriptファイルを適切にフォーマットされたPDFに変換するプロセスを簡素化し、元のオンラインのコンテンツを損なうことはありません。 これは、請求書、認証、レポートなどの動的印刷可能なドキュメントを生成する必要のあるWebアプリケーションに非常に便利なツールです。
IronPDFには、カスタマイズ可能なページ設定、ヘッダー、フッター、及びフォントや画像の挿入能力を含むいくつかの特徴があります。 複合レイアウトとスタイルをサポートし、すべてのテスト出力のPDFが指定されたデザインに従うようにします。 さらに、IronPDFはHTML内でのJS実行を管理し、動的及びインタラクティブなコンテンツの正確なレンダリングを可能にします。
IronPDF の機能
HTMLからのPDF生成
HTML、CSS、JavaScriptをPDFに変換します。 2つの現代的なウェブ標準をサポート:メディアクエリとレスポンシブデザイン。 HTMLとCSSを使用して、PDF請求書、レポート、およびドキュメントを動的に装飾するのに便利です。
PDF編集
既存のPDFにテキストや画像、その他の素材を追加することが可能です。 PDFファイルからテキストや画像を抽出します。 複数のPDFを一つのファイルにマージします。PDFファイルをいくつかの異なる文書に分割します。 ヘッダー、フッター、注釈、ウォーターマークを追加します。
パフォーマンスと信頼性
産業環境において、高いパフォーマンスと信頼性は望ましい設計属性です。 大規模なドキュメントのセットを容易に処理します。
IronPDFをインストールする
Node.jsプロジェクトでPDFを扱うのに必要なツールを手に入れるために、IronPDFパッケージをインストールしてください。
npm install @ironsoftware/ironpdfnpm install @ironsoftware/ironpdfXMLの解析とPDF生成
例としてexample.xmlと呼ばれる基本的なXMLファイルを生成しましょう:
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
</book>
<book category="nonfiction">
<title>Thinking, Fast and Slow</title>
<author>Daniel Kahneman</author>
</book>
</bookstore>XMLファイルを読み込み、XML2JSを使用してJavaScriptオブジェクトに解析し、その解析データの結果オブジェクトを使用してIronPDFでPDFを作成するgeneratePdf.js Node.jsスクリプトを作成します。
// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
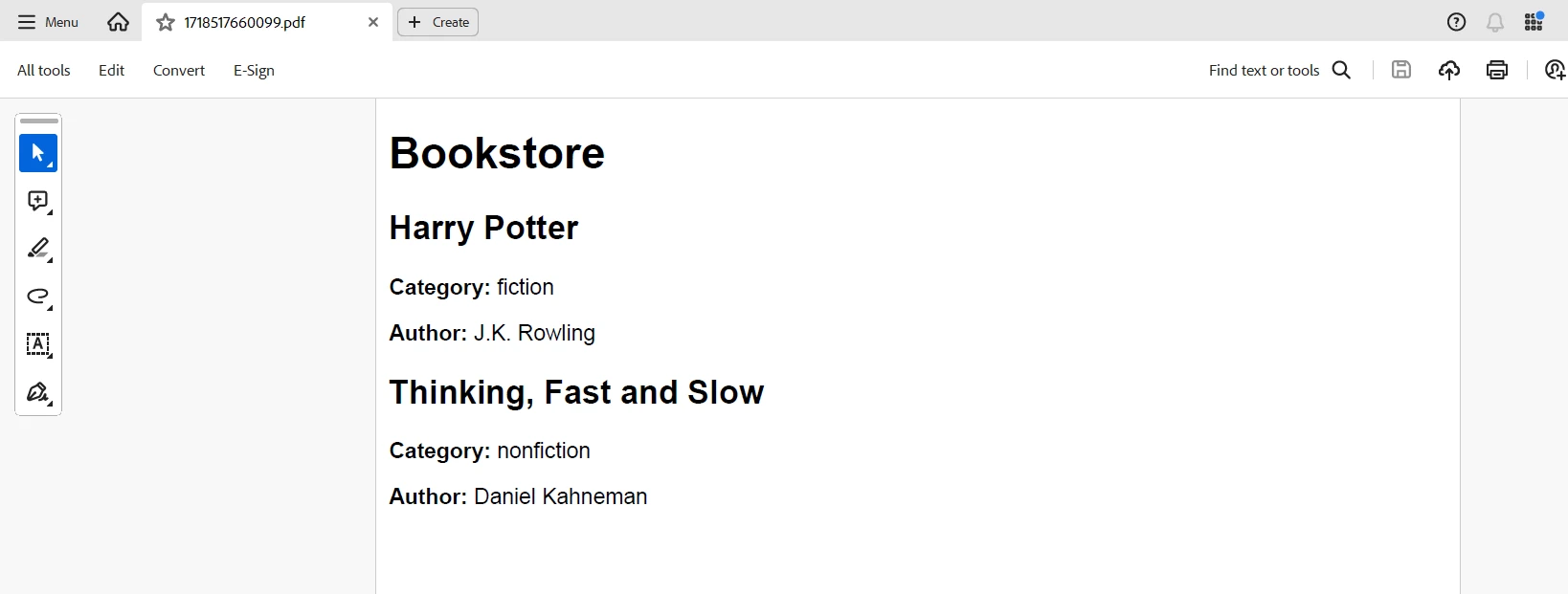
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
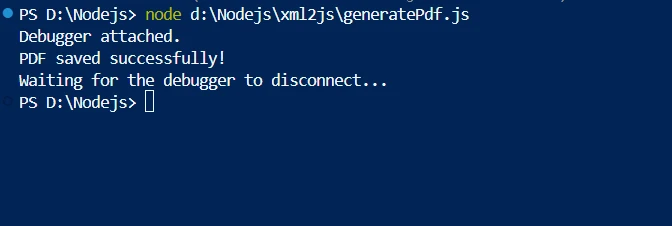
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();// generatePdf.js
const fs = require('fs');
const xml2js = require('xml2js');
const IronPdf = require('@ironsoftware/ironpdf');
// Configure IronPDF with license if necessary
var config = IronPdf.IronPdfGlobalConfig;
config.setConfig({ licenseKey: '' });
// Function to read and parse XML
const parseXml = async (filePath) => {
const parser = new xml2js.Parser();
const xmlContent = fs.readFileSync(filePath, 'utf8');
return await parser.parseStringPromise(xmlContent);
};
// Function to generate HTML content from the parsed object
function generateHtml(parsedXml) {
let htmlContent = `
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Bookstore</title>
<style>
body { font-family: Arial, sans-serif; }
.book { margin-bottom: 20px; }
</style>
</head>
<body>
<h1>Bookstore</h1>
`;
// Iterate over each book to append to the HTML content
parsedXml.bookstore.book.forEach(book => {
htmlContent += `
<div class="book">
<h2>${book.title}</h2>
<p><strong>Category:</strong> ${book.$.category}</p>
<p><strong>Author:</strong> ${book.author}</p>
</div>
`;
});
htmlContent += `
</body>
</html>
`;
return htmlContent;
}
// Main function to generate PDF
const generatePdf = async () => {
try {
const parser = await parseXml('./example.xml');
const htmlContent = generateHtml(parser);
// Convert HTML to PDF
IronPdf.PdfDocument.fromHtml(htmlContent).then((pdfres) => {
const filePath = `${Date.now()}.pdf`;
pdfres.saveAs(filePath).then(() => {
console.log('PDF saved successfully!');
}).catch((e) => {
console.log(e);
});
});
} catch (error) {
console.error('Error:', error);
}
};
// Run the main function
generatePdf();Node.jsアプリケーションでIronPDFとXML2JSを組み合わせることは、XMLデータをPDFドキュメントに変換し、複数のファイルを解析する簡単な方法です。 まず最初に、Node.jsのfsモジュールを使用してXMLファイルを読み込んだ後、XML2JSを使ってファイルのXMLコンテンツをJavaScriptオブジェクトに解析します。 その後、この処理されたデータを使用してPDFの基盤を構成するHTMLテキストが動的に生成されます。
スクリプトは、ファイルからXMLテキストを読み取り、xml2jsを使ってそれをJavaScriptオブジェクトに解析することから始めます。 解析されたデータオブジェクトから、書店用の著者やタイトルなど、必要な要素で構造化されたHTMLコンテンツがカスタム関数によって作成されます。 このHTMLは、IronPDFを使用してその後PDFバッファにレンダリングされます。 生成されたPDFはファイルシステムに保存されます。
IronPDFの効果的なHTMLからPDFへの変換及びXML2JSの強力なXML解析機能を用いることで、この方法はNode.jsアプリケーションにおいてXMLデータからPDFを作成する簡素化された手段を提供します。 この連携により、動的なXMLデータを印刷可能で整形されたPDFドキュメントに変換することが可能になります。 これは、XMLソースからの自動化ドキュメント生成を必要とするアプリケーションに理想的です。
結論
要約すると、Node.jsアプリケーションにおいてXML2JSとIronPDFを併用することで、XMLデータを高品質なPDFドキュメントに変換する強力で適応性のある方法を提供します。 XML2JSを用いたJavaScriptオブジェクトへの効果的なXML解析は、データの抽出及び操作を簡単にします。 データが解析された後、それは動的にHTMLテキストに変更され、それをIronPDFが適切に構造化されたPDFファイルに容易に変換できます。
XMLデータソースからのレポート、請求書、および証明書などのドキュメントの自動生成を必要とするアプリケーションにこの組み合わせは特に有用です。 両方のライブラリの利点を活用することで、開発者は正確で視覚的に魅力的なPDFの出力を確実にし、作業の流れを簡素化して、Node.jsアプリのドキュメント生成タスクの処理能力を向上させます。
IronPDFは、Iron Softwareの非常に柔軟なシステムとスイートを利用しながら、開発者により多くの能力を提供し、より効率的な開発を実現します。
ライセンスオプションが明確で、プロジェクトに特化していると、開発者はベストなモデルを選択しやすくなります。 これらの機能により、開発者は様々な問題を使いやすく、効率的かつ一貫性を持って解決できます。