
PythonでPDFをテキストに変換する方法(チュートリアル)
この記事では、最も強力な PDF ライブラリの 1 つである IronPDF for Python を使用して、PDF ドキュメント内の任意のテキストを抽出する方法を説明します。
- PDFをテキストに変換するPythonライブラリをインストールする。
- 既存の PDF ドキュメントを読み込むか、新しいものをレンダリングします
- `ExtractAllText`メソッドを使用して、開いたファイルからテキストを読み取ります。
- 特定のページからテキストを読み取るには、このメソッドの別のオーバーロードを使用します。
- 抽出したテキストをコンソールに印刷するか、テキストファイルに保存する
2.0 Python を使用して PDF からテキストを抽出するにはどうすればいいですか?
- Pythonダウンロードページから最新バージョン for Pythonをインストールします。
- Python用のIDEツールを開きます
- .NET Coreランタイムをインストールする
- IronPDF for Pythonライブラリをインストールするか、 PyPIダウンロードページからダウンロードします。
- PDFからテキストを抽出する
2.1 IronPDF for Python とは何ですか?
IronPDF ライブラリは他の言語に比べてはるかに動的な言語であり、開発者がグラフィカル ユーザー インターフェイスを迅速かつ簡単に作成できるため、Python に統合するのは簡単です。 PyQT、wxWidgets、kivy、および多数の追加パッケージとライブラリを含む多数のプリインストールされたツールがあり、それらすべてを使用して、完全に完成した GUI を迅速かつ安全に作成できます。
IronPDF for Python は非常に効率的なライブラリであり、特に Web 開発に役立ちます。 Django、Flask、Pyramid など、多数の Python Web 開発パラダイムが利用可能であることが、この一因となっています。 これらのフレームワークは、Reddit、Mozilla、Spotify など、多数の Web サイトやオンライン サービスで使用されています。
2.2 IronPDFの機能
- PDF ファイルは、HTML、HTML5、ASP、PHP の Web サイトなど、さまざまなソースから作成できます。 HTML ファイルだけでなく、画像ファイルを PDF に変換することも可能です。
- IronPDF を使用すると、インタラクティブな PDF ドキュメントの作成、インタラクティブなフォームへの入力と送信、PDF ファイルの分割と結合、PDF ファイルからのテキストと画像の抽出、PDF ファイル内の特定の単語の検索、 PDF ページの画像へのラスタライズ、PDF から HTML への変換、 PDF ファイルの印刷を行うことができます。
- IronPDF は URL から PDF ファイルを開いて印刷できます。 さらに、ユーザー エージェントが HTML ログイン フォーム、プロキシ、Cookie、HTTP ヘッダー、カスタム ネットワーク ログイン資格情報、フォーム変数、およびユーザー エージェントの背後でログインできるようになります。
- IronPDF を使用してドキュメントから画像を抽出できます。
- IronPDF を使用すると、ヘッダーやフッター、テキストや画像、ブックマークや透かしなどをドキュメントに簡単に追加できます。
- IronPDF を使用すると、新規または既存のドキュメントを使用してページを結合したり分離したりすることができます。
- Acrobat ビューアを使用せずに、ドキュメントを PDF オブジェクトに変換できます。
- CSS ファイルを使用して PDF ドキュメントを作成できます。
- メディアタイプのCSSファイルを使用してドキュメントの作成が可能です。
2.3 IronPDFライブラリのインポート
IronPDF をインポートするには、IronPDF が使用されるソース ファイルの先頭に次のインポート ステートメントを含めます。
from ironpdf import *from ironpdf import *2.4 ライセンスキーの設定(必要な場合)
IronPDF for Python は無料で使用できますが、無料ユーザーの場合、PDF ファイルにタイル状の背景に透かしが入ります。 IronPDF を使用して透かしのない PDF を作成するには、ライブラリに正規のライセンス キーを付与する必要があります。 ライセンス キーを使用してライブラリを設定する方法は、次のコード スニペットに示されています。
# Set the license key for IronPDF
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"# Set the license key for IronPDF
License.LicenseKey = "IRONPDF-LICENSE-KEY-ABCDEFGH"PDF ファイルを作成したり、そのコンテンツを変更したりする前に、ライセンス キーが設定されていることを確認してください。 LicenseKey メソッドは他のコード行の前に呼び出す必要があります。 無料試用ライセンス キーを取得するには、ライセンス ページにアクセスしてください。
2.5 ログファイルの設定
"Default"というテキスト ファイルには、Python スクリプトのディレクトリ内の Custom.log によって生成されたログ メッセージを保存できます。 以下のコードスニペットは、LogFilePath プロパティを設定し、ログファイル名と位置をカスタマイズするために使用できます。
# Enable debugging and set the log file path and mode
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging and set the log file path and mode
Logger.EnableDebugging = True
Logger.LogFilePath = "Custom.log"
Logger.LoggingMode = Logger.LoggingModes.All3.0 IronPDFでPDFテキストを抽出する
IronPDF for Python ライブラリは、PDF ページを PDF オブジェクトに変換し、スキャンされた PDF ファイルを含む PDF ファイルからテキストを抽出できるようにします。 以下は、IronPDF を使用して既存の PDF を読み取る方法を示す例です。
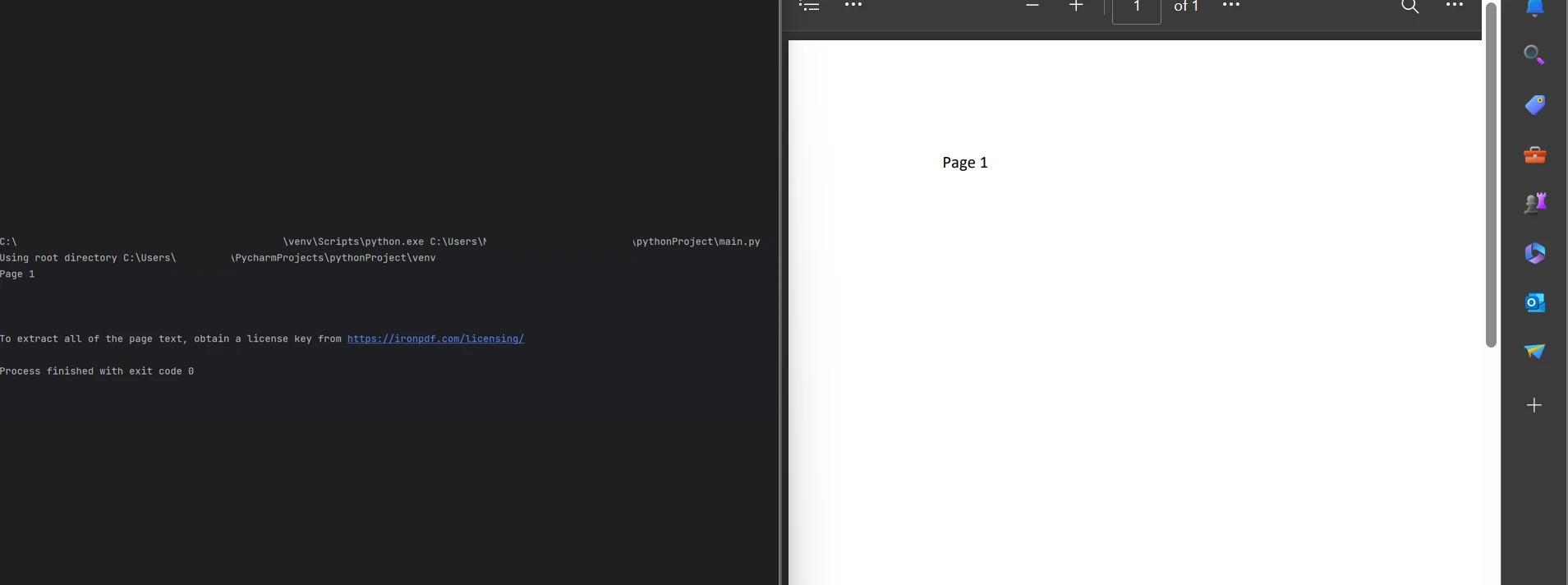
最初の方法では、PDF 内のすべてのテキストを抽出します。 コードのサンプルを以下に示します。
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract all the text from the entire PDF document
all_text = pdf.ExtractAllText()
# Display the extracted text
print(all_text)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract all the text from the entire PDF document
all_text = pdf.ExtractAllText()
# Display the extracted text
print(all_text)上記のコードに示されているように、FromFile メソッドは既存のPDFファイルをロードし、PDFドキュメントオブジェクトに変換するPDFリーダーオブジェクトです。 このオブジェクトは、PDF ページにあるテキストと画像を読み取るために使用できます。 このオブジェクトは、PDFファイル全体からすべてのテキストを引き出し、処理可能な文字列に保持するExtractAllText というメソッドを提供します。 そして、そのテキストを表示するためにprint 関数を使用します。
 テキストを表示する
テキストを表示する
PDFファイルからページごとにテキストを抽出する2番目の方法のコード例を以下に示します。
from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Display the extracted text from the specified page
print(page_text)from ironpdf import *
# Load existing PDF document
pdf = PdfDocument.FromFile("content.pdf")
# Extract text from a specific page in the document
page_text = pdf.ExtractTextFromPage(1)
# Display the extracted text from the specified page
print(page_text)FromFile メソッドは、既存のファイルからPDFファイルをロードし、上記のコードに示されているようにPDFファイルオブジェクトに変換するために使用されます。 PDFページオブジェクトのメソッドであるExtractTextFromPage がPDFファイルのページからすべてのテキストを取得します。特定のページからテキストを抽出するためにはページ番号をパラメーターとして提供する必要があります。 そして、テキストを抽出した後、page_text は処理可能な情報を保持するために使用できます。
PDF からテキストを抽出するためのその他の例を確認してください。
4.0 結論
対照的に、IronPDFライブラリは潜在的なリスクを軽減するために強力なセキュリティ対策を提供します。 特定のブラウザ向けにカスタマイズされておらず、一般的に使用されているすべてのブラウザで動作します。 IronPDF を使用すると、プログラマーはわずか数行のコードで簡単に PDF ファイルを作成および読み取ることができます。 IronPDF ライブラリは、さまざまな開発者のニーズを満たすために、無料の開発者ライセンスや購入可能な追加の開発ライセンスなど、さまざまなライセンス オプションを提供します。
IronPDF には、永久ライセンス、30 日間の返金保証、1 年間のソフトウェア サポート、アップグレード オプションが含まれています。 初回購入後、追加費用は発生しません。 これらのライセンスは、開発、ステージング、プロダクション環境で使用することができます。 製品ライセンスの詳細については、こちらをご覧ください。
ソフトウェア製品をダウンロードします。
よくある質問
PythonでPDFをテキストに変換するにはどうすればいいですか?
PDFをテキストに変換するには、IronPDFのPdfDocument.FromFileメソッドを使用してPDFをロードし、ExtractAllTextまたはExtractTextFromPageメソッドを使用して必要なテキストを抽出します。
PythonでPDFライブラリを使用するにはどんなセットアップが必要ですか?
IronPDFを使用するには、PythonとIDEをインストールし、.NET Coreランタイムを導入する必要があります。IronPDFはPyPIのダウンロードページからインストールできます。
Pythonを使用してPDFの特定のページからテキストを抽出できますか?
はい、IronPDFでは、ページ番号をパラメータとして指定することでExtractTextFromPageメソッドを使用して特定のページからテキストを抽出できます。
PythonでPDFライブラリを使用するための無料オプションはありますか?
IronPDF for Pythonは、ウォーターマークをPDFに追加する無料版を提供しています。ウォーターマークを削除してフル機能をアンロックするには、ライセンスキーが必要です。
DjangoやFlaskなどのウェブフレームワークとPDFライブラリを統合するにはどうすればいいですか?
IronPDFはDjangoやFlaskなどのウェブフレームワークとシームレスに統合でき、ウェブアプリケーションプロジェクト内でのPDFの生成や操作が可能です。
PythonのPDFライブラリで探すべき機能は何ですか?
IronPDFのような包括的なPDFライブラリでは、HTMLや画像からのPDF作成、テキスト抽出、フォームの記入、PDFのマージ、ブックマークやウォーターマークの追加をサポートする必要があります。
PythonのPDFライブラリにライセンスキーを設定するにはどうすればいいですか?
IronPDFでは、他のコードを実行する前にLicense.LicenseKeyメソッドを使用してライセンスキーを設定し、ライセンスを登録してウォーターマークを削除します。
PythonのPDFライブラリはウェブページからのPDF作成をサポートしていますか?
IronPDFはHTML、HTML5、ASPやPHPで構築されたウェブページからのPDF作成が可能で、ウェブベースのPDF生成において多用途なツールです。
Python用のPDFライブラリでデバッグを有効にするにはどうすればいいですか?
IronPDFでデバッグを有効にするには、Logger.EnableDebuggingをtrueに設定し、Logger.LogFilePathを使用してログファイルのパスを定義します。
Python用のPDFライブラリのセキュリティ機能は何ですか?
IronPDFはセキュリティとクロスブラウザー互換性を確保し、Pythonでの安全なPDF操作を求める開発者に信頼性のあるソリューションを提供します。
















