
PythonでURLからPDFをダウンロードする方法
この記事では、IronPDF for Python ライブラリを使用して PDF を作成する方法を説明します。
IronPDF
Python は、他の言語よりもプログラマーにとってはるかに動的な言語であり、開発者がグラフィカル ユーザー インターフェイスを迅速かつ簡単に設計できます。 したがって、IronPDF ライブラリを Python に組み込むのは簡単です。 PyQt、wxWidgets、Kivy などの多数の組み込みツールや、完全に機能する GUI を迅速かつ安全に構築するために使用できる他の多くのパッケージとライブラリが付属しています。
IronPDF は、Python での Web 開発とデザインのための非常に効果的なライブラリです。 これは主に、Django、Flask、Pyramid など、利用できる Python Web 開発パラダイムが非常に多いためです。 Reddit、Mozilla、Spotify など、多数の Web サイトやオンライン サービスがこれらのフレームワークを利用しています。
- PDF ファイルは、 HTML 、HTML5、ASP、PHP サイト、その他のソースから作成できます。 HTML ファイルだけでなく画像ファイルも PDF に変換できます。
- IronPDF を使用してインタラクティブな PDF ドキュメントを作成できます。 インタラクティブなフォームに入力して送信したり、PDF ファイルを分割および結合したり、PDF ファイルからテキストや画像を抽出したり、PDF ファイル内の特定の単語を検索したり、PDF ページを画像にラスタライズしたり、PDF を HTML に変換したり、 PDF ファイルを印刷したりできます。
- IronPDF を使用すると、URL からドキュメントを生成できます。 さらに、ユーザー エージェント、プロキシ、Cookie、HTTP ヘッダー、カスタム ネットワーク ログイン資格情報、フォーム変数、HTML ログイン フォームの背後でログインするユーザー エージェントもサポートします。
- IronPDF プログラムを使用して PDF ファイルを調べたり注釈を付けたりすることができます。
- IronPDF を使用すると、ドキュメントから画像を抽出できます。
- IronPDF を使用すると、ヘッダー、フッター、テキスト、画像、ブックマーク、透かしなどを PDF ドキュメントに簡単に追加できます。
- IronPDF を使用すると、新規または既存のドキュメントでページを結合したり分割したりできます。
- Acrobat ビューアを使用せずにドキュメントを PDF オブジェクトに変換できます。
- CSSファイルからPDF文書を作成するにはIronPDFを使用できます。
- メディアタイプ指定のある CSS ファイルを使用してドキュメントを作成できます。
Pythonを設定する
環境を設定する
コンピュータに Python がインストールされていることを確認してください。 ご使用のオペレーティング システム用の最新バージョンの Python をダウンロードしてインストールするには、公式の Python ダウンロード Web サイトにアクセスしてください。 Python をインストールしたら、プロジェクトの依存関係を分離するための仮想環境を設定します。 仮想環境を作成および管理するためには、venvモジュールを使用します。これにより、変換プロジェクトのためのクリーンかつ独立した作業スペースが提供されます。
PyCharm の新しいプロジェクト
このデモでは、Python 開発用の IDE である PyCharm が推奨されます。
PyCharm IDE を開いたら、下の画像に示すように"新規プロジェクト"オプションを選択します。
 PyCharm IDE
PyCharm IDE
"新しいプロジェクト"を選択すると新しいウィンドウが開き、下の画像に示すように、プロジェクトの場所と Python 環境を指定できます。
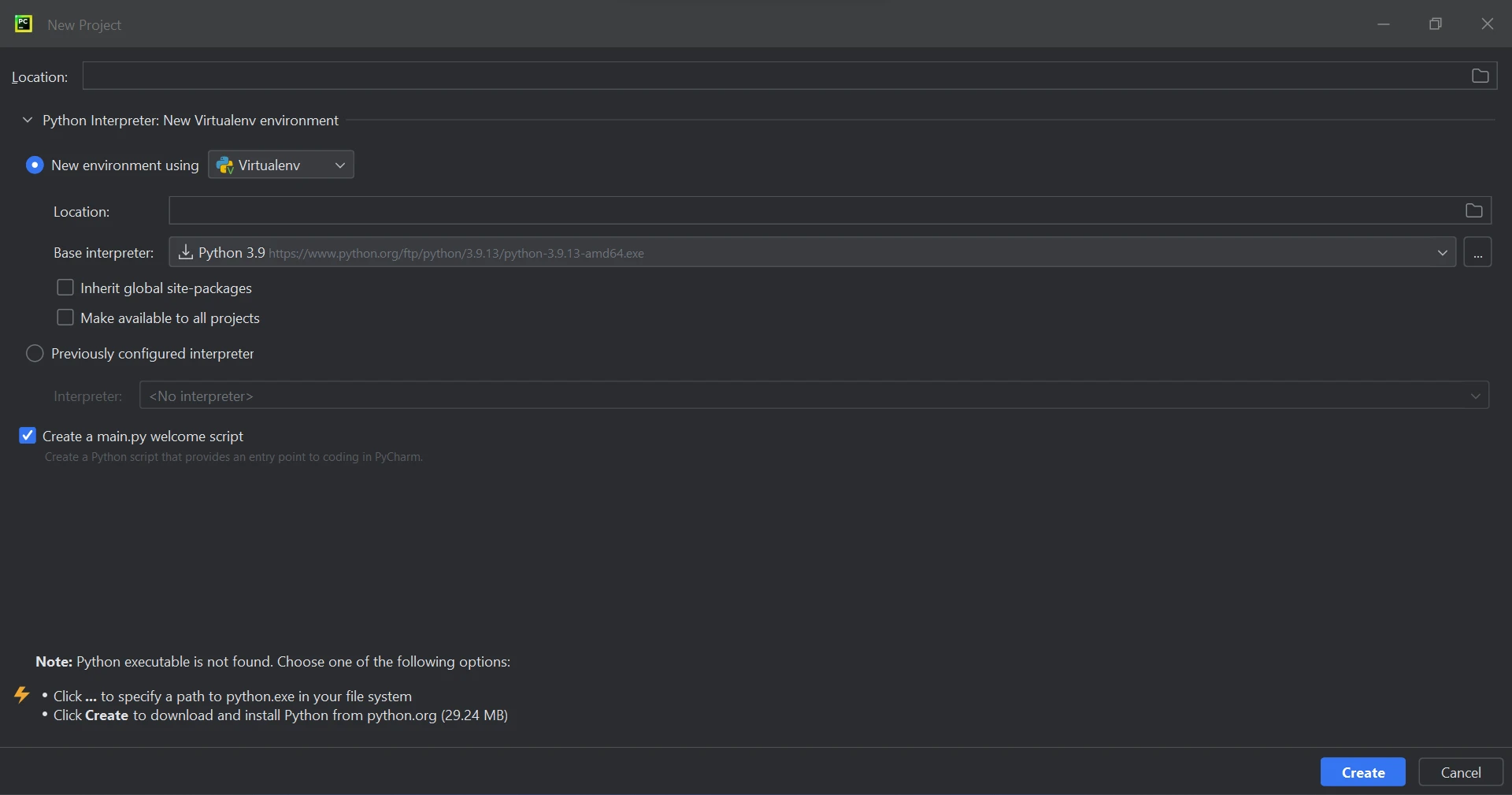 PyCharmで新しいプロジェクトを作成する
PyCharmで新しいプロジェクトを作成する
プロジェクトの場所と環境パスを選択したら、 [作成]ボタンをクリックして新しいプロジェクトを作成します。 新しいウィンドウが開き、Pythonファイルにコードを記述できるようになります。このチュートリアルではPython 3.9を使用します。
 main.pyファイル
main.pyファイル
IronPDF for Python ライブラリの要件
IronPDF for Python は、基盤テクノロジーとして .NET 6.0 を利用します。 したがって、IronPDF for Python を使用するには、コンピューターに .NET 6.0 ランタイムがインストールされている必要があります。 Linux および Mac ユーザーは、この Python パッケージを使用する前に .NET をインストールする必要がある場合があります。 必要なランタイム環境をダウンロードするには、 Microsoft のこのダウンロード ページからダウンロードできます。
IronPDF パッケージのセットアップ
".pdf"拡張子のファイルを作成、編集、開くことができるようにするには、ironpdfパッケージをインストールする必要があります。 PyCharm にパッケージをインストールするには、ターミナル ウィンドウを開いて次のコマンドを実行します。
pip install ironpdf
以下のスクリーンショットでわかるように、ironpdfパッケージがインストールされました。
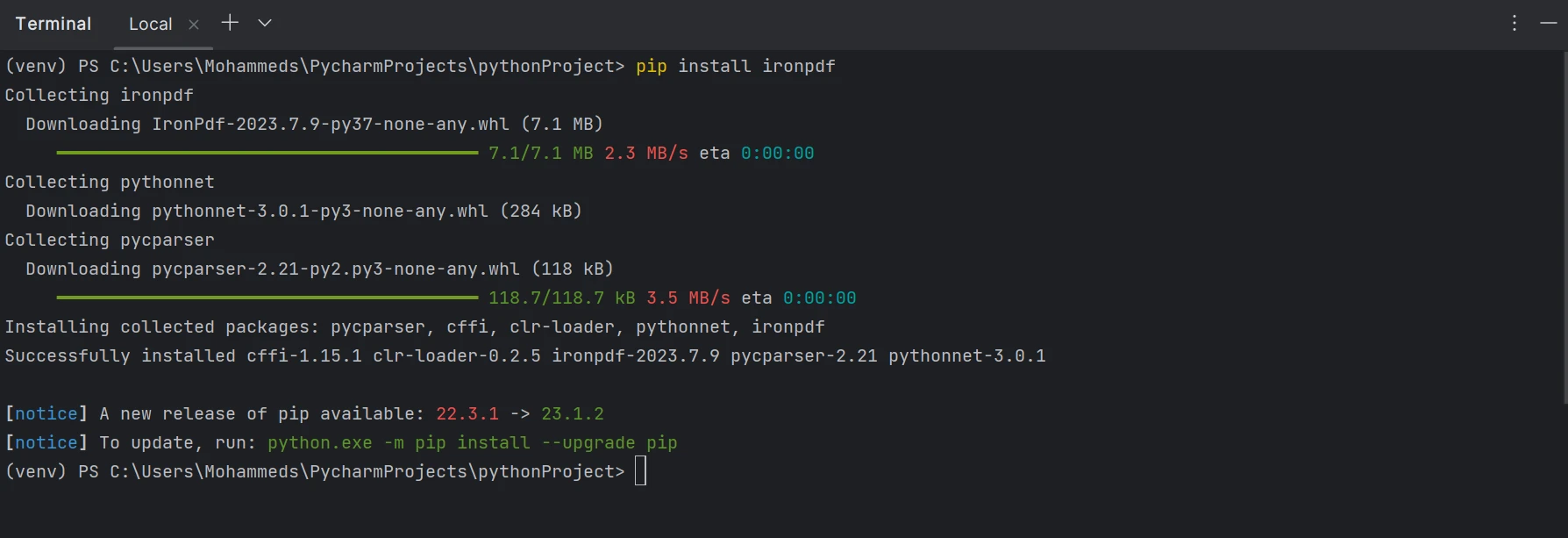 IronPDFパッケージをインストールする
IronPDFパッケージをインストールする
IronPDF を使用して URL から PDF を作成する
Python を使用すると、IronPDF ライブラリを使用して、わずか数行のコードで PDF ファイルを簡単に生成できます。 IronPDF は追加の依存関係を必要としないスタンドアロン ライブラリです。 強力な Chromium ブラウザを利用し、画像、グラフ、表などを含む URL を正確にダウンロードできます。 以下は PDF ファイルを生成するサンプル コード スニペットです。
from ironpdf import *
# Create a renderer to render PDF from a URL
renderer = ChromePdfRenderer()
# Render the given URL as a PDF
pdf = renderer.RenderUrlAsPdf("https://www.google.com/")
# Save the rendered PDF to a file
pdf.SaveAs("output.pdf")
# Inform the user that the PDF creation is complete
print('Completed')from ironpdf import *
# Create a renderer to render PDF from a URL
renderer = ChromePdfRenderer()
# Render the given URL as a PDF
pdf = renderer.RenderUrlAsPdf("https://www.google.com/")
# Save the rendered PDF to a file
pdf.SaveAs("output.pdf")
# Inform the user that the PDF creation is complete
print('Completed')提供されているコードでは、最初のステップは IronPDF ライブラリをインポートすることです。 次に、様々なPDFファイル作成プロセスを実行できるChromePdfRendererクラスのインスタンスを作成します。 作成されたオブジェクト、"renderer"という名前のものを使用して、RenderUrlAsPdf関数を使用できます。 この機能には、PDF 形式に変換する必要のある PDF URL が必要です。 指定されたウェブページからデータをスクレイピングし、画像を含む小さなデータチャンクでファイルをダウンロードし、応答をバイナリファイルに書き込みます。最後に、生成されたPDFファイルをPDF形式でローカルディレクトリに保存するために、SaveAs関数を使用します。
上記のコードの出力は以下の画像に示されています。
 出力PDFファイル
出力PDFファイル
さらに、IronPDF は .NET Framework で使用できます。 IronPDF を .NET Framework で使用する方法の詳細については、このサンプル リンクをクリックしてください。
結論
IronPDF ライブラリは、潜在的なリスクを軽減し、データ保護を確実にするための強力なセキュリティ対策を提供します。 一般的に使用されているすべてのブラウザと互換性があり、特定のブラウザに限定されません。 わずか数行のコードで、プログラマーは IronPDF を使用して PDF ファイルを効率的に作成および読み取ることができます。 開発者の多様なニーズに応えるために、IronPDF ライブラリでは、無料の開発者ライセンスや購入可能な追加の開発ライセンスなど、さまざまなライセンス オプションを提供しています。
$799の価格のLiteパッケージには、永続ライセンス、30日間の返金保証、1年間のソフトウェアサポート、アップグレードの可能性が含まれます。 最初の購入後は、追加の費用は発生しません。 これらのライセンスは、運用、ステージング、開発環境で使用できます。 IronPDF は、一定の期間と再配布の制限が付いた無料ライセンスも提供しています。 現実世界では、ユーザーは透かしなしの無料試用期間でソフトウェアをテストできます。 IronPDF の試用価格とライセンスの詳細については、次のライセンス ページを参照してください。
IronPDF をダウンロードして試してみましょう。
よくある質問
PythonでどのようにURLからPDFをダウンロードできますか?
PythonでURLからPDFをダウンロードするには、IronPDFの組み込みChromiumブラウザを使用してURLをPDFとしてレンダリングします。ChromePdfRendererクラスを使用してコンテンツを取得し、SaveAsメソッドを使用してPDFファイルとして保存します。
PythonでIronPDFを使用するために何が必要ですか?
PythonでIronPDFを使用するには、Pythonと.NET 6.0ランタイムがインストールされていることを確認します。また、Python環境にIronPDFパッケージをpip install ironpdfでインストールします。
Pythonを使用してインタラクティブなPDFドキュメントを作成するにはどうすればよいですか?
IronPDFは、フォームの入力、注釈、およびPDFファイルの分割と結合などの機能を提供することにより、PythonでインタラクティブなPDFドキュメントを作成できます。
IronPDFはDjangoやFlaskのようなWebフレームワークと互換性がありますか?
はい、IronPDFはDjango、Flask、Pyramidなど for Python Webフレームワークと互換性があり、WebアプリケーションからのシームレスなPDF生成を可能にします。
Python用IronPDFの主な機能は何ですか?
IronPDF for Pythonは、HTMLをPDFにレンダリングしたり、画像をPDFに変換したり、コンテンツを抽出したり、注釈を追加したり、PDFドキュメントを結合または分割するなどの機能を提供します。
IronPDFをPyCharmプロジェクトに統合するにはどうすればよいですか?
IronPDFをPyCharmプロジェクトに統合するには、PyCharm内でターミナルを開きpip install ironpdfを実行してパッケージをインストールし、プロジェクトファイルにインポートします。
IronPDFを使用して安全なPDFを作成できますか?
はい、IronPDFはセキュリティ機能を提供し、安全で管理されたPDFドキュメントの作成と管理を可能にし、コンテンツの保護とアクセスの制御を確保します。
IronPDF for Pythonがサポートするプラットフォームは何ですか?
IronPDF for Pythonは、Windows、Linux、Macプラットフォームをサポートしており、適切な機能を確保するために.NETランタイムがインストールされている必要があります。
IronPDFはPython開発者向けに無料トライアルを提供していますか?
はい、IronPDFは無料トライアルを提供しており、開発者がその機能を評価するためのマーキング制限のない機会を提供します。ライセンスを購入する前に機能をテストできます。
IronPDFに追加の依存関係は必要ですか?
いいえ、IronPDFはスタンドアロンライブラリであり、Pythonと.NETランタイムを除いて追加の依存関係は必要ありません。
















