
How to Download PDF From URL in Python
This article will demonstrate how to create a PDF using the IronPDF for Python library.
IronPDF
Python is a much more dynamic language for programmers than other languages, allowing developers to quickly and easily design graphical user interfaces. Therefore, it is simple to include the IronPDF library in Python. It comes with a ton of built-in tools like PyQt, wxWidgets, Kivy, and many other packages and libraries that can be used to quickly and safely build a fully functional GUI.
IronPDF is a highly effective library for web development and design in Python. This is largely because there are so many Python web development paradigms available, such as Django, Flask, and Pyramid. Numerous websites and online services, including Reddit, Mozilla, and Spotify, have made use of these frameworks.
- PDF files can be created from HTML, HTML5, ASP, PHP sites, and other sources. It is also possible to convert picture files as well as HTML files to PDF.
- Interactive PDF documents can be created using IronPDF. You can fill out and submit interactive forms, split and combine PDF files, extract text and images from PDF files, search for specific words in a PDF file, rasterize PDF pages to images, convert PDF to HTML, and print PDF files.
- IronPDF allows the generation of a document from a URL. Additionally, it supports user agents, proxies, cookies, HTTP headers, custom network login credentials, form variables, and user agents that log in behind HTML login forms.
- You can examine and annotate PDF files using the IronPDF program.
- IronPDF can be used to extract images from documents.
- With IronPDF, it is very easy to add headers, footers, text, pictures, bookmarks, watermarks, and more to PDF documents.
- Using IronPDF, you can merge and split pages with a new or existing document.
- It is possible to convert documents to PDF objects without using an Acrobat viewer.
- A PDF document can be created from a CSS file using IronPDF.
- Documents can be created using CSS files with media-type specifications.
Configure Python
Set up the Environment
Ensure that Python is installed on your computer. To download and install the latest version of Python for your operating system, visit the official Python download website. Once Python is installed, set up a virtual environment to isolate the dependencies for your project. Use the venv module to create and manage virtual environments, which will provide a clean and independent workspace for your conversion project.
New Project in PyCharm
For this demonstration, PyCharm, an IDE for Python development, is recommended.
After opening PyCharm IDE, select the "New Project" option as shown in the image below.
 PyCharm IDE
PyCharm IDE
A new window will open when you choose "New Project", allowing you to specify the project's location and Python environment, as depicted in the image below.
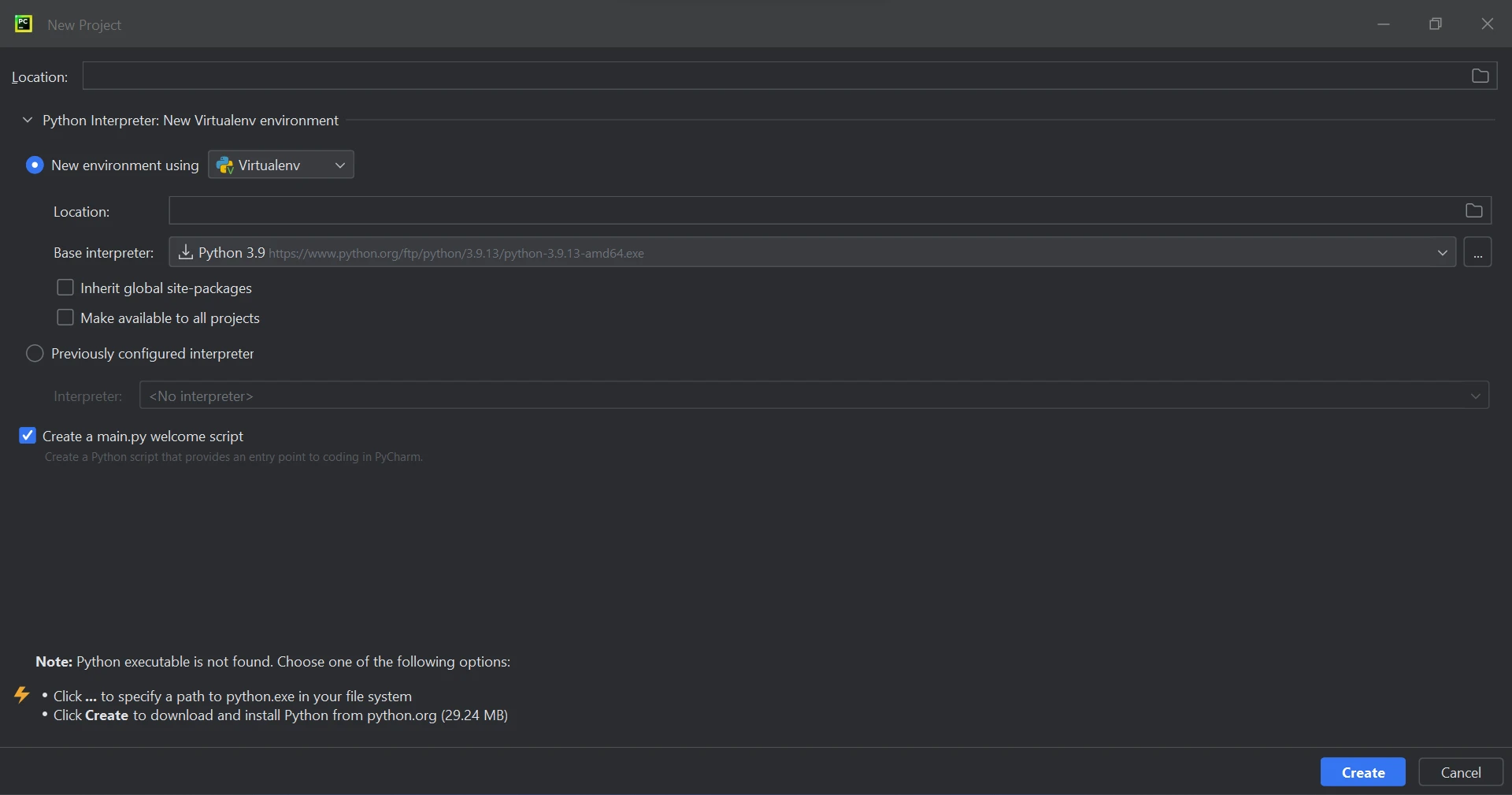 Create a new project in PyCharm
Create a new project in PyCharm
After selecting the project location and environment path, click the Create button to create a new project. A new window will open, and you will be able to write your code in a Python file. For this tutorial, Python 3.9 is being used.
 The main.py file
The main.py file
IronPDF for Python Library Requirement
IronPDF for Python utilizes .NET 6.0 as its underlying technology. Therefore, in order to use IronPDF for Python, your computer must have the .NET 6.0 runtime installed. Linux and Mac users may need to install .NET before using this Python package. To download the required runtime environment, you can download it from this download page of Microsoft.
IronPDF Package Setup
The ironpdf package must be installed in order to be able to create, edit, and open files with the ".pdf" extension. To install the package in PyCharm, open a terminal window and run the following command:
pip install ironpdf
As you can see in the screenshot below, the ironpdf package has been installed.
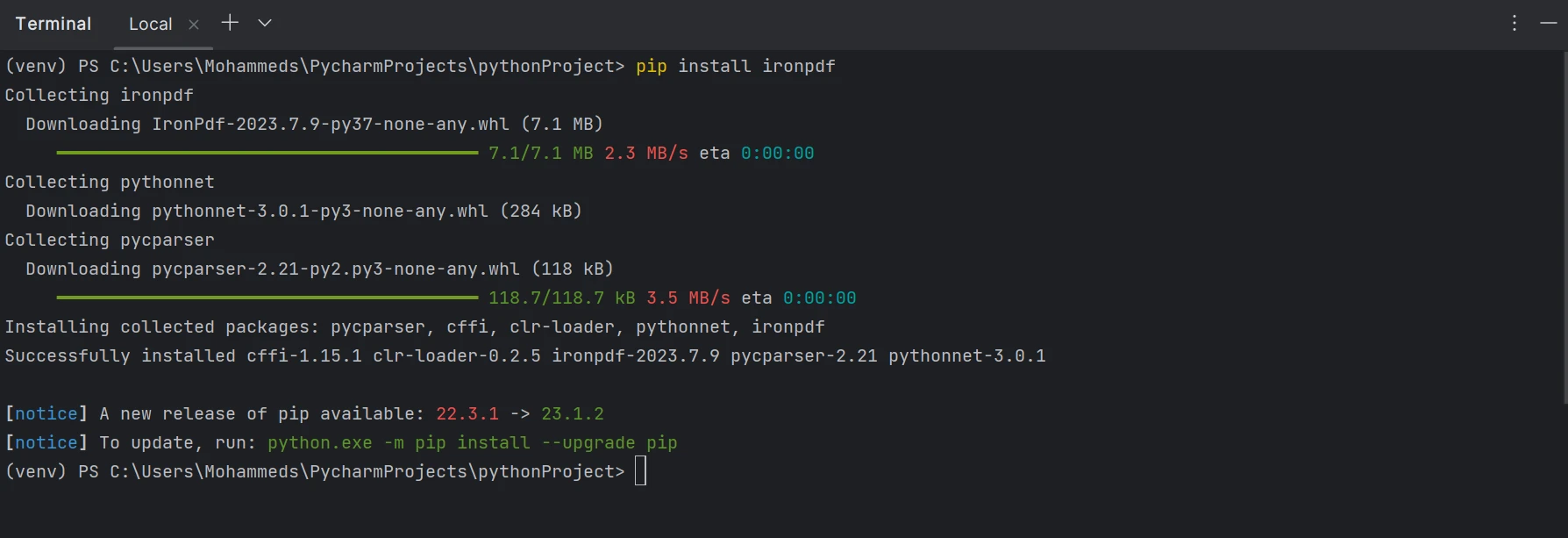 Install the IronPDF package
Install the IronPDF package
Create a PDF from a URL using IronPDF
Using Python, a PDF file can be easily generated with just a few lines of code using the IronPDF library. IronPDF is a standalone library that does not require any additional dependencies. It utilizes a powerful Chromium browser, which enables accurate downloading of URLs that include images, charts, tables, and more. Below is a sample code snippet to generate a PDF file:
from ironpdf import *
# Create a renderer to render PDF from a URL
renderer = ChromePdfRenderer()
# Render the given URL as a PDF
pdf = renderer.RenderUrlAsPdf("https://www.google.com/")
# Save the rendered PDF to a file
pdf.SaveAs("output.pdf")
# Inform the user that the PDF creation is complete
print('Completed')from ironpdf import *
# Create a renderer to render PDF from a URL
renderer = ChromePdfRenderer()
# Render the given URL as a PDF
pdf = renderer.RenderUrlAsPdf("https://www.google.com/")
# Save the rendered PDF to a file
pdf.SaveAs("output.pdf")
# Inform the user that the PDF creation is complete
print('Completed')In the provided code, the first step is to import the IronPDF library. Then, create an instance of the ChromePdfRenderer class, which allows performing various PDF file creation processes. Using the created object, named "renderer", the RenderUrlAsPdf function can be used. This function requires the PDF URL that needs to be converted into PDF format. It will scrape data from the specified web page, downloading files in small chunks of data, including images, and write the response into a binary file. Finally, the SaveAs function is used to save the generated PDF file to the local directory in PDF format.
The output of the above code is shown in the below image.
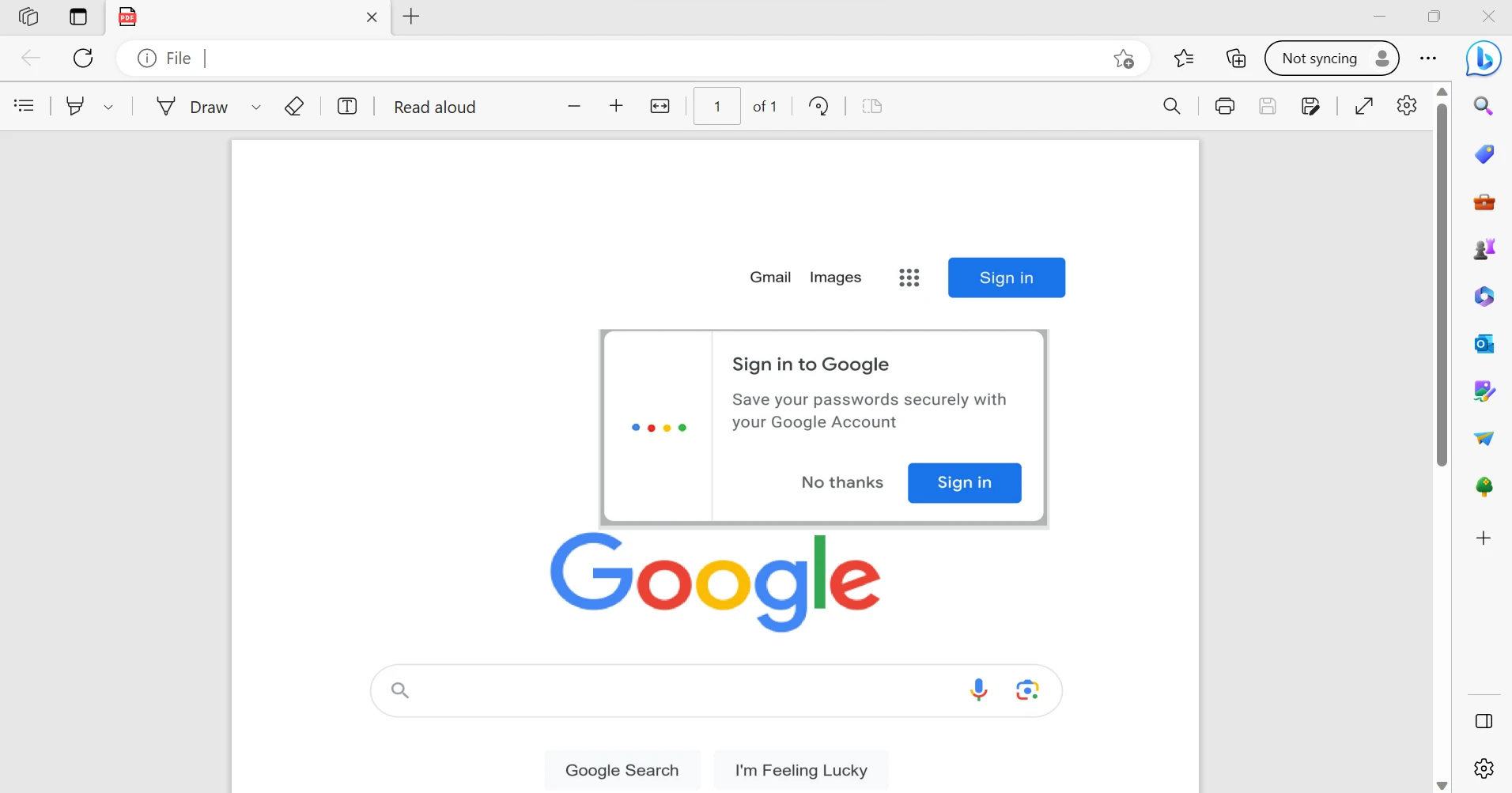 The output PDF file
The output PDF file
Additionally, IronPDF can be used with the .NET Framework. To learn more about using IronPDF with .NET Framework, you can click on this example link.
Conclusion
The IronPDF library offers robust security measures to mitigate potential risks and ensure data protection. It is compatible with all commonly used browsers and is not limited to a specific browser. With just a few lines of code, programmers can efficiently create and read PDF files using IronPDF. To cater to the diverse needs of developers, the IronPDF library provides various licensing options, including a free developer license and additional development licenses available for purchase.
The Lite package, priced at $999, includes a perpetual license, a 30-day money-back guarantee, one year of software support, and upgrade possibilities. After the initial purchase, there are no further costs involved. These licenses can be used in production, staging, and development environments. IronPDF also offers free licenses with certain time and redistribution limitations. In a real-world context, users can test the software with a free trial period without a watermark. For more detailed information about IronPDF's trial pricing and licensing, please refer to the following licensing page.
Download IronPDF and give it a try.
Frequently Asked Questions
How can I download a PDF from a URL using Python?
To download a PDF from a URL in Python, you can use IronPDF's built-in Chromium browser to render the URL as a PDF. Use the ChromePdfRenderer class to fetch the content and SaveAs method to save it as a PDF file.
What is required to use IronPDF with Python?
To use IronPDF with Python, ensure you have Python and the .NET 6.0 runtime installed. Additionally, install the IronPDF package in your Python environment using pip install ironpdf.
How can I create interactive PDF documents using Python?
IronPDF allows the creation of interactive PDF documents in Python by providing features such as form filling, annotations, and the ability to split and merge PDF files.
Is IronPDF compatible with web frameworks like Django and Flask?
Yes, IronPDF is compatible with Python web frameworks such as Django, Flask, and Pyramid, allowing seamless PDF generation from web applications.
What are some key features of IronPDF for Python?
IronPDF for Python offers features such as rendering HTML to PDF, converting images to PDF, extracting content, adding annotations, and combining or splitting PDF documents.
How do I integrate IronPDF into a PyCharm project?
To integrate IronPDF into a PyCharm project, open the terminal within PyCharm and run pip install ironpdf to install the package, then import it into your project files.
Can I use IronPDF to create secure PDFs?
Yes, IronPDF provides security features that allow you to create and manage secure PDF documents, ensuring content is protected and access is controlled.
What platforms are supported by IronPDF for Python?
IronPDF for Python supports Windows, Linux, and Mac platforms, with the requirement that the .NET runtime is installed for proper functionality.
Does IronPDF offer a free trial for Python developers?
Yes, IronPDF offers a free trial that allows developers to evaluate its capabilities without watermark restrictions, providing an opportunity to test features before purchasing a license.
Are there any additional dependencies needed for IronPDF?
No, IronPDF is a standalone library and does not require any additional dependencies beyond Python and the .NET runtime.
















