
PythonでPDFからテキストを抽出する方法
この記事では、Python で IronPDF を使用して PDF ファイルからすべてのテキストを抽出する方法を説明し、このタスクを効率的に実行するための知識と Python コード スニペットを提供します。
- PDFからテキストを抽出するため for Pythonモジュールをダウンロードする。
- PDFファイルをインポートするには、`FromFile`メソッドを使用します。
- 取 り 込んだ PDF か ら `ExtractText` メ ソ ッ ド でテ キ ス ト を抽出 し ます。
- `ExtractTextFromPage`メソッドを使用して、特定のページからテキストを抽出します。
- 抽出したテキストをコンソールまたはテキストファイルに出力する
IronPDF - Python ライブラリ
IronPDF for Pythonは、開発者が PDF ドキュメントからテキストを抽出できるようにする強力な Python PDF ライブラリです。 IronPDF を使用すると、PDF ファイルからテキスト コンテンツのデータ抽出部分を自動化できるため、PDF ドキュメントに含まれる情報の処理と分析が容易になります。
IronPDF は、Python プログラマーに、Python を使用して PDF ファイルを操作、データ抽出、対話する機能を提供し、さまざまな PDF 関連のタスクの自動化を容易にします。 PDF を生成したり、既存の PDF を変更したり、コンテンツからデータを抽出したり、その他の PDF 操作を実行したりする必要がある場合、IronPDF は直感的な API と強力な機能によってプロセスを簡素化します。
主要機能
IronPDF for Python ライブラリの機能には次のようなものがあります。
- 最初から新しいPDFファイルを作成する
- 既存のPDFファイルの編集
- PDFファイルからテキスト、メタデータ、画像を抽出します
- PDFファイルを他の形式に変換する
- パスワードと制限でPDFファイルを保護
- PDFの分割と結合
前提条件
IronPDF を使用してテキスト抽出を進める前に、次の前提条件が満たされていることを確認してください。
- Python のインストール:システムに Python がインストールされていることを確認します。 IronPDF は Python 3.x バージョンと互換性があるため、互換性のある Python がインストールされていることを確認してください。
IronPDFライブラリ: Pythonパッケージマネージャーで
pipを使用してIronPDFライブラリをインストールします。 コマンドライン インターフェイスを開き、次のコマンドを実行します。pip install ironpdfpip install ironpdfSHELL注意: pip コマンドを使用するには、Python を PATH 環境変数に追加する必要があります。
3.統合開発環境 (IDE):厳密には必要ではありませんが、IDE を使用すると開発エクスペリエンスが大幅に向上します。 コード補完、デバッグ、より合理化されたワークフローなどの機能を提供します。 Python 開発用の人気のある IDE の 1 つは PyCharm です。 PyCharm は JetBrains の Web サイトhttps://www.jetbrains.com/pycharm/からダウンロードしてインストールできます。 4.テキスト エディター:軽量のテキスト エディターを使用する場合は、Visual Studio Code、Sublime Text、Atom など、任意のテキスト エディターを使用することもできます。 これらのエディターは、構文の強調表示や Python 開発に役立つその他の機能を提供します。 Python 独自の IDLE アプリを使用することもできます。
PyCharm を使用した Python プロジェクトの作成
PyCharm IDE をインストールした後、以下の手順に従って PyCharm Python プロジェクトを作成します。
PyCharm を起動します。システムのアプリケーション ランチャーまたはデスクトップ ショートカットから PyCharm を開きます。 2.新しいプロジェクトを作成する: "新しいプロジェクトの作成"をクリックするか、既存の Python プロジェクトを開きます。
 PyCharm IDE
PyCharm IDE
3.プロジェクト設定を構成する:プロジェクトの名前を指定し、プロジェクト ディレクトリを作成する場所を選択します。 プロジェクト用の Python インタープリターを選択します。 次に"作成"をクリックします。
**Pycharmで新しいPythonプロジェクトを作成する**4.ソース ファイルの作成: PyCharm は、メインの Python ファイルと追加のソース ファイル用のディレクトリを含むプロジェクト構造を作成します。 コードの記述を開始し、実行ボタンをクリックするか、Shift + F10 を押してスクリプトを実行します。
IronPDF を使用して Python で PDF からテキストを抽出する
それでは、Python プログラミング言語で IronPDF を使用して PDF ファイルからプレーンテキストを抽出する手順について詳しく見ていきましょう。
必要なライブラリをインポートする
まず、Python スクリプトに必要なライブラリをインポートします。 この場合、コード サンプルでは、PDF ファイルの操作機能を提供するIronPDFライブラリをインポートする必要があります。
import ironpdfimport ironpdfライセンスキーを設定する
IronPDF を使用して PDF ファイルから全文を抽出するには、IronPDF のライセンスが必要です。 次のコマンドを使用して、ライセンスまたは試用キーを適用します。
# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"注:ライセンスキーがない場合、IronPDF によるデータの抽出は PDF 拡張子ファイルから数文字に制限されます。ライセンスキーは、 IronPDF をご購入いただくか、無料トライアルにご登録いただくことで取得できます。
PDFドキュメントを読み込む
次に、IronPDFからPdfDocument.FromFile()メソッドを使用してPDFファイルを読み込みます。 このメソッドの引数として PDF ファイルへのパスを指定します。 これにより、PDFファイルがPdfDocumentオブジェクトに読み込まれます。
pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")入力ファイル
入力 PDF ファイルからテキストを抽出して画面に印刷するには、次のドキュメントを使用します。
 入力ファイル
入力ファイル
PDFファイルからテキストを抽出する
PDFドキュメントが読み込まれたら、ExtractTextメソッドを使用してテキストコンテンツを抽出できます。 このメソッドは、抽出されたテキストを文字列として返します。
text = pdf.ExtractText()text = pdf.ExtractText()抽出したテキストの処理と活用
PDF からテキストを抽出したので、必要に応じて処理して利用できます。 テキストの解析、分析、データベースへの保存、またはさらなるデータ処理に使用するなどのタスクを実行できます。
# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text出力
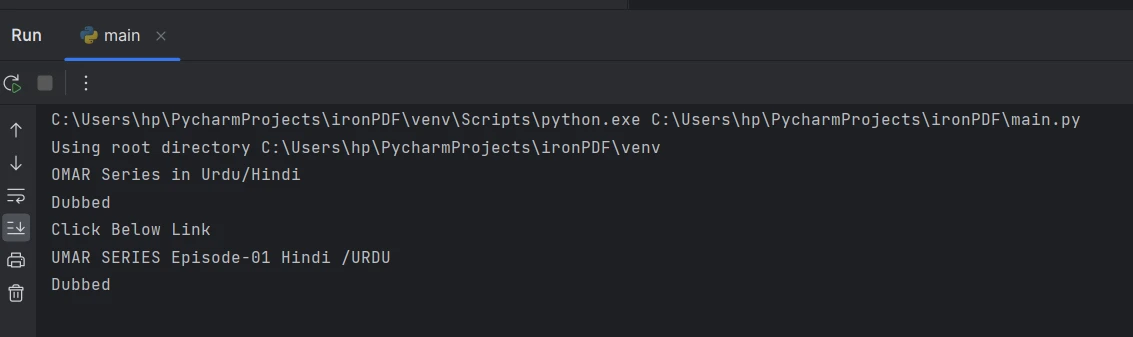 コンソールから抽出されたテキスト
コンソールから抽出されたテキスト
PDFファイル内の特定のページからテキストを抽出する
IronPDFは、PDFファイル内の特定のページからテキストを抽出する便利な方法も提供しています。このセクションでは、IronPDFが提供するExtractTextFromPageメソッドを使って特定のページからテキストを抽出する方法を探ります。
次のコードは、特定のページからテキストを抽出する方法を示しています。
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)上記のサンプルコードでは、PdfDocumentオブジェクトを表します。 ExtractTextFromPage()メソッドは、引数として渡されたページインデックスによって示される特定のページからテキストを抽出するために使用されます。 この場合、テキストはページ インデックス 1 に対応する 2 番目のページまたはページ番号 2 から抽出されます。
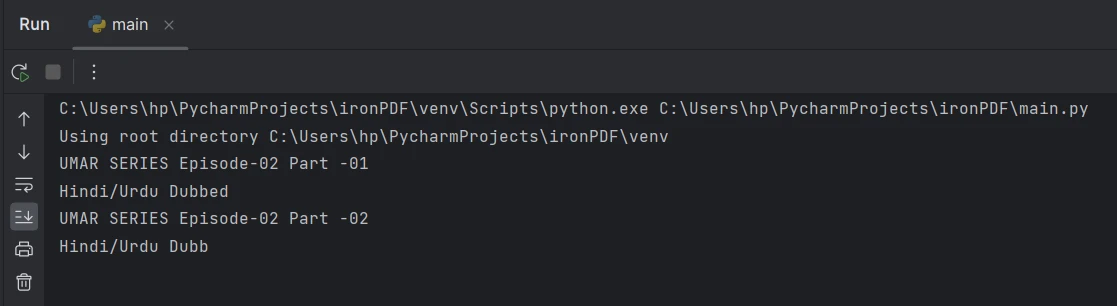 2ページ目からテキストを抽出
2ページ目からテキストを抽出
結論
この記事では、Python で IronPDF を使用して PDF ファイルからテキストを抽出する方法について説明しました。 必要なライブラリのインポート、PDF ドキュメントの読み込み、テキスト コンテンツの抽出、抽出されたテキストの処理など、必要な手順について説明しました。
IronPDF の強力なテキスト抽出機能を使用すると、PDF からのテキストの抽出とその後の処理を自動化できるため、PDF ドキュメント内のテキスト情報を簡単に処理および分析できます。 直感的な API と豊富な機能により、Python 開発におけるさまざまな PDF 関連のタスクに最適です。
IronPDF は開発目的では無料ですが、商用利用にはライセンスが必要です。 テストのために本番環境モードで使用する場合は、無料トライアルを入手してください。 Python 用 IronPDFの最新バージョンをダウンロードしてインストールし、試してみましょう。
よくある質問
Pythonを使用してPDF文書全体からテキストを抽出するにはどうすればよいですか?
IronPDFのPdfDocument.FromFile()メソッドを使用してPDFを読み込み、ExtractText()メソッドを呼び出してテキストコンテンツを取得することで、PDF文書全体からテキストを抽出できます。
PythonでPDFの特定のページからテキストを抽出するプロセスは何ですか?
PDFの特定のページからテキストを抽出するには、IronPDFのExtractTextFromPage()メソッドを使用します。これにより、その特定のページからテキストを取得するためのページインデックスを指定できます。
Python用のIronPDFライブラリをインストールするにはどうすればよいですか?
pipパッケージマネージャーを使用して、次のコマンドを実行してPython用のIronPDFライブラリをインストールします:pip install ironpdf。
PythonでPDFからテキストを抽出するための前提条件は何ですか?
前提条件には、システムにPythonがインストールされていること、pipを介してIronPDFをインストールすること、そして開発にPyCharmのようなIDEを使用することが含まれます。
Python用のIronPDFライブラリの無料バージョンはありますか?
IronPDFは開発目的では無料ですが、商業利用にはライセンスが必要です。ライブラリを実際の運用モードでテストするための無償トライアルが利用可能です。
IronPDFを使用してPDFから完全なテキストを抽出するにはライセンスが必要ですか?
はい、PDFから完全にテキストを抽出するにはIronPDFのライセンスキーが必要です。ライセンスがない場合、抽出は数文字に制限されます。
Python用IronPDFの主な機能は何ですか?
Python用IronPDFの主な機能には、PDFの作成と編集、テキスト、メタデータ、および画像の抽出、他の形式への変換、パスワードのようなセキュリティ機能の追加が含まれます。
Python用IronPDFはPDFデータ抽出の自動化に役立ちますか?
はい、IronPDFはFromFileとExtractTextのようなメソッドを提供しており、PDFデータの抽出を自動化し、データ分析や操作を支援します。
PythonでIronPDFを使用するために推奨されるIDEは何ですか?
PyCharmは、コード補完、デバッグツール、効率的なワークフローといった機能により、PythonでIronPDFを使用するために推奨されます。
IronPDFはPDF文書の処理におけるワークフローをどのように強化しますか?
IronPDFは、テキスト抽出、PDFの作成・編集、形式変換、およびセキュリティ設定のための直感的なAPIを提供することによりさまざまなPDF関連のタスクを効率化し、ワークフローを向上させます。
















