
Jak konwertować HTML na PDF w Node.js, używając Puppeteer
W dzisiejszym cyfrowym świecie kluczowa jest możliwość konwersji stron internetowych lub dokumentów HTML do plików PDF. Może to być przydatne do generowania raportów, tworzenia faktur lub po prostu udostępniania informacji w bardziej przejrzystym formacie. W tym wpisie na blogu omówimy, jak konwertować strony HTML do formatu PDF przy użyciu Node.js i Puppeteer, biblioteki open source opracowanej przez Google.
Wprowadzenie do Puppeteer
Puppeteer to potężna biblioteka Node.js, która pozwala programistom sterować przeglądarkami bezinterfejsowymi, głównie Google Chrome lub Chromium, oraz wykonywać różne czynności, takie jak pobieranie danych z sieci, robienie zrzutów ekranu i generowanie plików PDF. Puppeteer udostępnia rozbudowany interfejs API do interakcji z przeglądarką, co czyni go doskonałym wyborem do konwersji HTML na PDF.
Dlaczego Puppeteer?
- Łatwość użytkowania: Puppeteer oferuje proste i łatwe w użyciu API, które eliminuje złożoność pracy z przeglądarkami bezinterfejsowymi.
- Wydajność: Puppeteer zapewnia szerokie możliwości manipulowania stronami internetowymi i interakcji z elementami przeglądarki.
- Skalowalność: Dzięki Puppeteer możesz łatwo skalować proces generowania plików PDF, uruchamiając równolegle wiele instancji przeglądarki.
Konfiguracja projektu Node.js
Zanim zaczniemy, musisz skonfigurować nowy projekt Node.js. Aby rozpocząć, wykonaj następujące kroki:
- Zainstaluj Node.js, jeśli jeszcze tego nie zrobiłeś (możesz pobrać go ze strony Node.js).
- Utwórz nowy folder dla swojego projektu i otwórz go w Visual Studio Code lub dowolnym edytorze kodu.
-
Uruchom
npm init, aby utworzyć nowy plikpackage.jsondla swojego projektu. Postępuj zgodnie z instrukcjami i wprowadź wymagane informacje.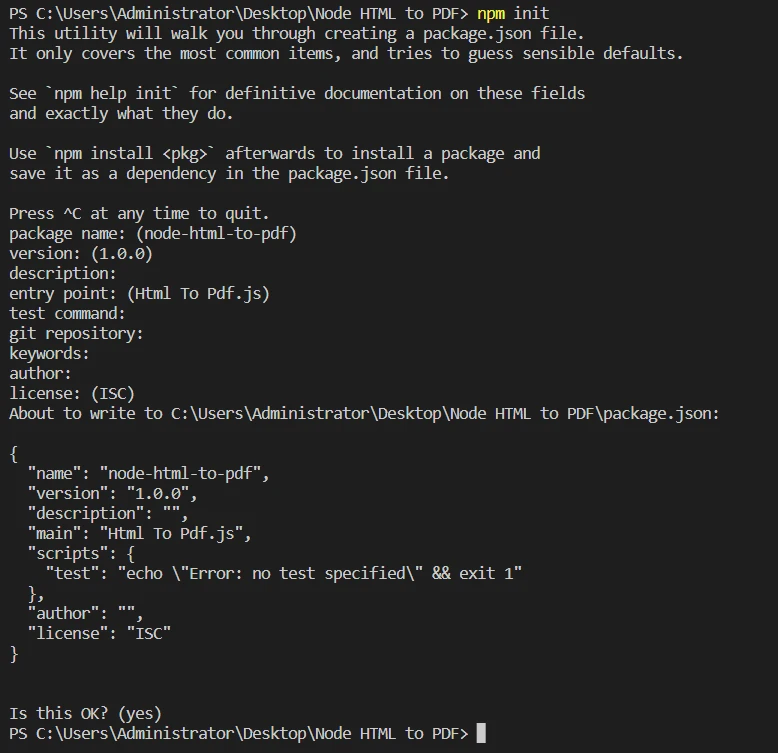
-
Zainstaluj Puppeteer, uruchamiając
npm install puppeteer.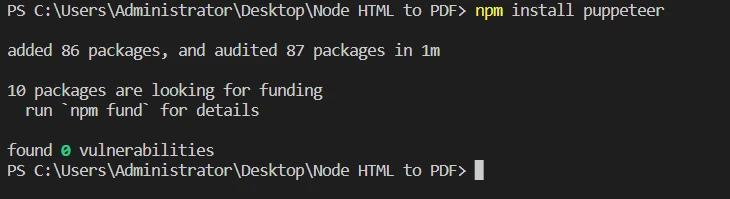
Skoro mamy już gotowy projekt, przejdźmy do kodu.
Ładowanie szablonu HTML i konwersja do pliku PDF
Aby przekonwertować szablony HTML na plik PDF za pomocą Puppeteer, wykonaj następujące kroki:
Utwórz w folderze plik o nazwie "HTML To PDF.js".
Importowanie Puppeteer i fs
const puppeteer = require('puppeteer');
const fs = require('fs');Kod rozpoczyna się od zaimportowania dwóch niezbędnych bibliotek: puppeteer, wszechstronnego narzędzia do sterowania przeglądarkami bezinterfejsowymi, takimi jak Chrome i Chromium, oraz fs, wbudowanego modułu Node.js do obsługi operacji systemu plików. Puppeteer umożliwia automatyzację szerokiego zakresu zadań internetowych, w tym renderowanie HTML, robienie zrzutów ekranu i generowanie plików PDF.
Definiowanie funkcji exportWebsiteAsPdf
async function exportWebsiteAsPdf(html, outputPath) {
// Create a browser instance
const browser = await puppeteer.launch({
headless: true // Launches the browser in headless mode
});
// Create a new page
const page = await browser.newPage();
// Set the HTML content for the page, waiting for DOM content to load
await page.setContent(html, { waitUntil: 'domcontentloaded' });
// To reflect CSS used for screens instead of print
await page.emulateMediaType('screen');
// Download the PDF
const PDF = await page.pdf({
path: outputPath,
margin: { top: '100px', right: '50px', bottom: '100px', left: '50px' },
printBackground: true,
format: 'A4',
});
// Close the browser instance
await browser.close();
return PDF;
}Funkcja exportWebsiteAsPdf stanowi rdzeń naszego fragmentu kodu. Ta funkcja asynchroniczna przyjmuje ciąg znaków html oraz outputPath jako parametry wejściowe i zwraca plik PDF. Funkcja wykonuje następujące kroki:
- Uruchamia nową instancję przeglądarki bezinterfejsowej przy użyciu Puppeteer.
- Tworzy nową stronę w przeglądarce.
- Ustawia podany ciąg znaków
htmljako zawartość strony, czekając na załadowanie zawartości DOM. - Emuluje typ mediów "screen", aby zastosować CSS używany dla ekranów zamiast stylów przeznaczonych do druku.
- Generuje plik PDF na podstawie załadowanej treści HTML, określając marginesy, drukowanie tła i format (A4).
- Zamyka instancję przeglądarki.
- Zwraca utworzony plik PDF.
Korzystanie z funkcji exportWebsiteAsPdf
// Usage example
// Get HTML content from HTML file
const html = fs.readFileSync('test.html', 'utf-8');
// Convert the HTML content into a PDF and save it to the specified path
exportWebsiteAsPdf(html, 'result.pdf').then(() => {
console.log('PDF created successfully.');
}).catch((error) => {
console.error('Error creating PDF:', error);
});Ostatnia sekcja kodu ilustruje sposób użycia funkcji exportWebsiteAsPdf. Wykonujemy następujące czynności:
- Odczytaj zawartość HTML z pliku HTML za pomocą metody
readFileSyncmodułufs. - Wywołaj funkcję
exportWebsiteAsPdfz załadowanym ciągiem znakówhtmli żądanymoutputPath. - Wykorzystaj blok
.thendo obsługi pomyślnego utworzenia pliku PDF, rejestrując komunikat o powodzeniu w konsoli. - Użyj bloku
.catchdo obsługi wszelkich błędów występujących podczas procesu konwersji HTML do PDF, rejestrując komunikat o błędzie w konsoli.
Ten fragment kodu stanowi kompleksowy przykład konwersji szablonu HTML do pliku PDF przy użyciu Node.js i Puppeteer. Wdrażając to rozwiązanie, można efektywnie generować wysokiej jakości pliki PDF, spełniające potrzeby różnych aplikacji i użytkowników.
Konwersja adresów URL na pliki PDF
Oprócz konwersji szablonów HTML, Puppeteer umożliwia również bezpośrednią konwersję adresów URL do plików PDF.
Importowanie Puppeteer
const puppeteer = require('puppeteer');Kod rozpoczyna się od zaimportowania biblioteki Puppeteer, która jest potężnym narzędziem do sterowania przeglądarkami bezinterfejsowymi, takimi jak Chrome i Chromium. Puppeteer pozwala zautomatyzować różne zadania internetowe, w tym renderowanie kodu HTML, robienie zrzutów ekranu oraz, w naszym przypadku, generowanie plików PDF.
Definiowanie funkcji exportWebsiteAsPdf
async function exportWebsiteAsPdf(websiteUrl, outputPath) {
// Create a browser instance
const browser = await puppeteer.launch({
headless: true // Launches the browser in headless mode
});
// Create a new page
const page = await browser.newPage();
// Open the URL in the current page
await page.goto(websiteUrl, { waitUntil: 'networkidle0' });
// To reflect CSS used for screens instead of print
await page.emulateMediaType('screen');
// Download the PDF
const PDF = await page.pdf({
path: outputPath,
margin: { top: '100px', right: '50px', bottom: '100px', left: '50px' },
printBackground: true,
format: 'A4',
});
// Close the browser instance
await browser.close();
return PDF;
}Funkcja exportWebsiteAsPdf stanowi rdzeń naszego fragmentu kodu. Ta funkcja asynchroniczna przyjmuje websiteUrl i outputPath jako parametry wejściowe i zwraca plik PDF. Funkcja wykonuje następujące kroki:
- Uruchamia nową instancję przeglądarki bezinterfejsowej przy użyciu Puppeteer.
- Tworzy nową stronę w przeglądarce.
- Przechodzi do podanego
websiteUrli czeka, aż sieć przejdzie w stan bezczynności, używając opcjiwaitUntilustawionej nanetworkidle0. - Emuluje typ mediów "screen", aby zapewnić zastosowanie CSS przeznaczonego dla ekranów zamiast stylów specyficznych dla PRINT.
- Konwertuje załadowaną stronę internetową na plik PDF z określonymi marginesami, drukowaniem tła i formatem (A4).
- Zamyka instancję przeglądarki.
- Zwraca wygenerowany plik PDF.
Korzystanie z funkcji exportWebsiteAsPdf
// Usage example
// Convert the URL content into a PDF and save it to the specified path
exportWebsiteAsPdf('https://ironpdf.com/', 'result.pdf').then(() => {
console.log('PDF created successfully.');
}).catch((error) => {
console.error('Error creating PDF:', error);
});Ostatnia sekcja kodu pokazuje, jak używać funkcji exportWebsiteAsPdf. Wykonujemy następujące kroki:
- Wywołaj funkcję
exportWebsiteAsPdfz żądanymi parametramiwebsiteUrlioutputPath. - Użyj bloku
then, aby obsłużyć pomyślne utworzenie pliku PDF. W tym bloku zapisujemy komunikat o pomyślnym zakończeniu operacji w konsoli. - Użyj bloku
catch, aby obsłużyć wszelkie błędy występujące podczas procesu konwersji strony internetowej do formatu PDF. W przypadku wystąpienia błędu rejestrujemy komunikat o błędzie w konsoli.
Dzięki wbudowaniu tego fragmentu kodu w swoje projekty możesz bez wysiłku konwertować adresy URL na wysokiej jakości pliki PDF przy użyciu Node.js i Puppeteer.
Najlepsza biblioteka do konwersji HTML na PDF dla programistów C
Explore IronPDF to popularna biblioteka .NET służąca do generowania, edycji i wyodrębniania treści z plików PDF. Zapewnia proste i wydajne rozwiązanie do tworzenia plików PDF z HTML, tekstu, obrazów i istniejących dokumentów PDF. IronPDF obsługuje projekty .NET Core, .NET Framework i .NET 5.0+, co czyni go wszechstronnym wyborem dla różnych zastosowań.
Najważniejsze cechy IronPDF
Konwersja HTML do PDF za pomocą IronPDF: IronPDF umożliwia konwersję treści HTML, w tym CSS, do plików PDF. Ta funkcja umożliwia tworzenie dokumentów PDF o idealnej rozdzielczości na podstawie stron internetowych lub szablonów HTML.
Renderowanie adresów URL: IronPDF może pobierać strony internetowe bezpośrednio z serwera za pomocą adresu URL i konwertować je na pliki PDF, co ułatwia archiwizację treści internetowych lub generowanie raportów z dynamicznych stron internetowych.
Łączenie tekstu, obrazów i plików PDF: IronPDF umożliwia łączenie tekstu, obrazów i istniejących plików PDF w jeden dokument PDF. Ta funkcja jest szczególnie przydatna do tworzenia złożonych dokumentów z wieloma źródłami treści.
Manipulacja plikami PDF: IronPDF zapewnia narzędzia do edycji istniejących plików PDF, takie jak dodawanie lub usuwanie stron, modyfikowanie metadanych, a nawet wyodrębnianie tekstu i obrazów z dokumentów PDF.
Wnioski
Podsumowując, generowanie i edycja plików PDF to częste wymaganie w wielu aplikacjach, a posiadanie odpowiednich narzędzi jest kluczowe. Rozwiązania przedstawione w tym artykule, takie jak użycie Puppeteer z Node.js lub IronPDF for .NET, oferują potężne i wydajne metody konwersji treści HTML i adresów URL na profesjonalne, wysokiej jakości dokumenty PDF.
W szczególności IronPDF wyróżnia się bogatym zestawem funkcji, co czyni go najlepszym wyborem dla programistów .NET. IronPDF oferuje bezpłatną wersję próbną, która pozwala zapoznać się z jego możliwościami.
Użytkownicy mogą również skorzystać z pakietu Iron Suite, zestawu pięciu profesjonalnych bibliotek .NET, w tym IronXL, IronPDF, IronOCR i innych.














