
如何使用 Puppeteer 在 Node.js 中将 HTML 转换为 PDF
在当今的数字世界中,将网页或 HTML 文档转换为 PDF 文件的能力至关重要。 这对于生成报告、创建发票或简单地以更直观的格式共享信息非常有用。 在本博文中,我们将探讨如何使用 Node.js 和 Puppeteer(Google 开发的开源库)将 HTML 页面转换为 PDF。
Puppeteer 简介
Puppeteer 是一个功能强大的 Node.js 库,它允许开发人员控制无头浏览器(主要是 Google Chrome 或 Chromium),并执行各种操作,如网络搜刮、截图和生成 PDF。 Puppeteer 提供了与浏览器交互的广泛 API,是将 HTML 转换为 PDF 的绝佳选择。
为什么选择 Puppeteer?
- 易用性: Puppeteer 提供了简单易用的 API,抽象化了无头浏览器工作的复杂性。
- 功能强大: Puppeteer 为操作网页和与浏览器元素交互提供了广泛的功能。
- 可扩展:使用 Puppeteer,您可以通过并行运行多个浏览器实例来轻松扩展 PDF 生成流程。
设置您的 NodeJS 项目
在开始之前,您需要建立一个新的 NodeJS 项目。 请按照以下步骤开始:
1.如果您还没有安装 NodeJS,请安装(您可以从 NodeJS 网站下载)。 2.为您的项目创建一个新文件夹,并在 Visual Studio Code 或任何特定的代码编辑器中打开。
-
运行
npm init为您的项目创建一个新的package.json文件。 按照提示填写所需信息。
-
通过运行
npm install puppeteer安装 Puppeteer。
现在我们已经完成了项目设置,让我们开始深入研究代码。
加载 HTML 模板并转换为 PDF 文件
要使用 Puppeteer 将 HTML 模板转换为 PDF 文件,请按照以下步骤操作:
在文件夹中创建一个名为 "HTML To PDF.js "的文件。
导入 Puppeteer 和fs
const puppeteer = require('puppeteer');
const fs = require('fs');代码首先导入两个重要的库:puppeteer,一个用于控制 Chrome 和 Chromium 等无头浏览器的多功能工具;以及 fs,一个用于处理文件系统操作的内置 NodeJS 模块。 Puppeteer 可让您自动执行各种基于网络的任务,包括渲染 HTML、截图和生成 PDF 文件。
定义 exportWebsiteAsPdf 函数
async function exportWebsiteAsPdf(html, outputPath) {
// Create a browser instance
const browser = await puppeteer.launch({
headless: true // Launches the browser in headless mode
});
// Create a new page
const page = await browser.newPage();
// Set the HTML content for the page, waiting for DOM content to load
await page.setContent(html, { waitUntil: 'domcontentloaded' });
// To reflect CSS used for screens instead of print
await page.emulateMediaType('screen');
// Download the PDF
const PDF = await page.pdf({
path: outputPath,
margin: { top: '100px', right: '50px', bottom: '100px', left: '50px' },
printBackground: true,
format: 'A4',
});
// Close the browser instance
await browser.close();
return PDF;
}exportWebsiteAsPdf 函数是我们代码片段的核心。 此异步函数接受一个字符串(html)和一个字符串(outputPath)作为输入参数,并返回一个 PDF 文件。该函数执行以下步骤:
1.使用 Puppeteer 启动一个新的无头浏览器实例。 2.创建新的浏览器页面。
- 将提供的
html字符串设置为页面内容,等待 DOM 内容加载。 4.模拟 "屏幕 "媒体类型,应用屏幕使用的 CSS,而不是打印特定的样式。 5.根据加载的 HTML 内容生成 PDF 文件,指定页边距、背景打印和格式(A4)。 6.关闭浏览器实例。 7.返回创建的 PDF 文件。
使用 exportWebsiteAsPdf 函数
// Usage example
// Get HTML content from HTML file
const html = fs.readFileSync('test.html', 'utf-8');
// Convert the HTML content into a PDF and save it to the specified path
exportWebsiteAsPdf(html, 'result.pdf').then(() => {
console.log('PDF created successfully.');
}).catch((error) => {
console.error('Error creating PDF:', error);
});代码的最后一部分说明了如何使用 exportWebsiteAsPdf 函数。 我们将执行以下步骤:
- 使用
fs模块的readFileSync方法从 HTML 文件中读取 HTML 内容。 - 使用加载的
html字符串和所需的outputPath调用exportWebsiteAsPdf函数。 - 使用
.then块来处理成功创建 PDF,并将成功消息记录到控制台。 - 使用
.catch块来管理 HTML 到 PDF 转换过程中发生的任何错误,并将错误消息记录到控制台。
本代码片段提供了一个综合示例,说明如何使用 NodeJS 和 Puppeteer 将 HTML 模板转换为 PDF 文件。 通过实施该解决方案,您可以高效地生成高质量的 PDF,满足各种应用程序和用户的需求。
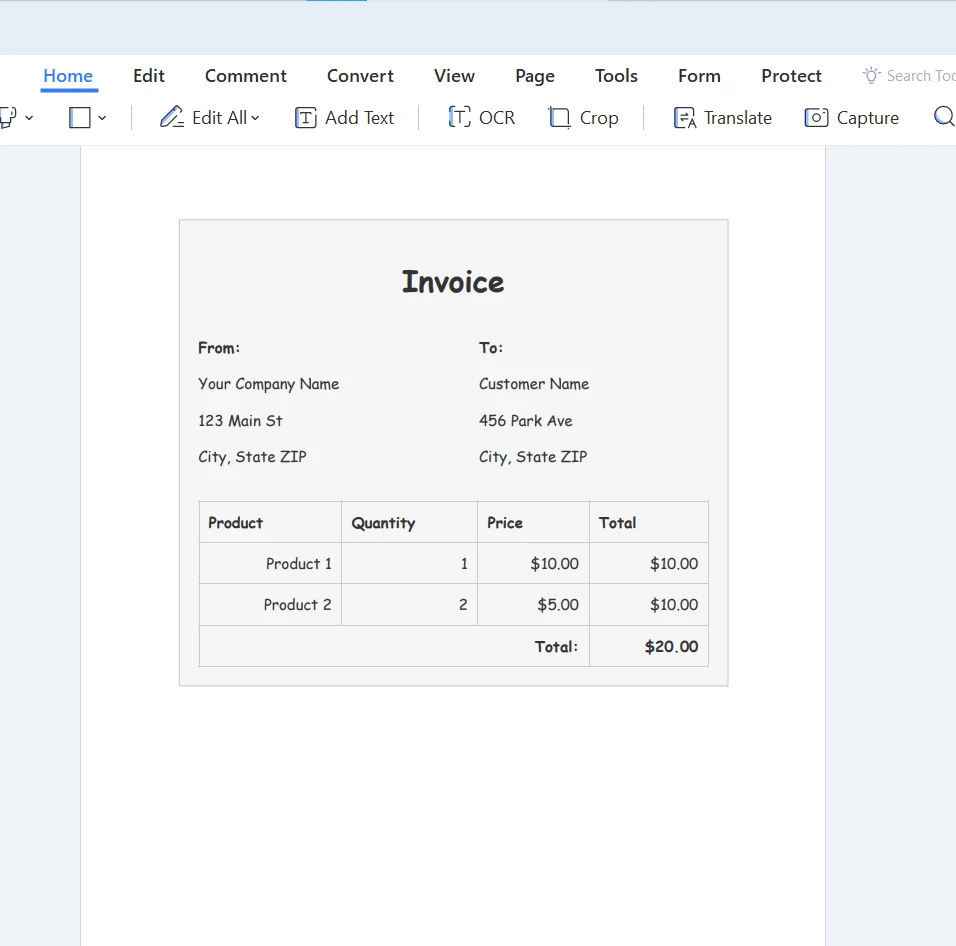
将 URL 转换为 PDF 文件
除了转换 HTML 模板,Puppeteer 还允许您将 URL 直接转换为 PDF 文件。
导入 Puppeteer
const puppeteer = require('puppeteer');代码首先要导入 Puppeteer 库,它是控制 Chrome 和 Chromium 等无头浏览器的强大工具。 Puppeteer 允许您自动执行各种基于 Web 的任务,包括渲染 HTML 代码、捕获屏幕截图,以及在我们的案例中生成 PDF 文件。
定义 exportWebsiteAsPdf 函数
async function exportWebsiteAsPdf(websiteUrl, outputPath) {
// Create a browser instance
const browser = await puppeteer.launch({
headless: true // Launches the browser in headless mode
});
// Create a new page
const page = await browser.newPage();
// Open the URL in the current page
await page.goto(websiteUrl, { waitUntil: 'networkidle0' });
// To reflect CSS used for screens instead of print
await page.emulateMediaType('screen');
// Download the PDF
const PDF = await page.pdf({
path: outputPath,
margin: { top: '100px', right: '50px', bottom: '100px', left: '50px' },
printBackground: true,
format: 'A4',
});
// Close the browser instance
await browser.close();
return PDF;
}exportWebsiteAsPdf 函数是我们代码片段的核心。 此异步函数接受一个 websiteUrl 和一个 outputPath 作为输入参数,并返回一个 PDF 文件。该函数执行以下步骤:
1.使用 Puppeteer 启动一个新的无头浏览器实例。 2.创建新的浏览器页面。
- 导航到提供的
websiteUrl,并使用设置为waitUntil的选项等待网络空闲。 4.模拟 "屏幕 "媒体类型,确保应用屏幕使用的 CSS,而不是打印特定的样式。 5.将加载的网页转换为具有指定页边、背景打印和格式(A4)的 PDF 文件。 6.关闭浏览器实例。 7.返回生成的 PDF 文件。
使用 exportWebsiteAsPdf 函数
// Usage example
// Convert the URL content into a PDF and save it to the specified path
exportWebsiteAsPdf('https://ironpdf.com/', 'result.pdf').then(() => {
console.log('PDF created successfully.');
}).catch((error) => {
console.error('Error creating PDF:', error);
});代码的最后一部分演示了如何使用 exportWebsiteAsPdf 函数。 我们执行以下步骤:
- 使用所需的
websiteUrl和outputPath调用exportWebsiteAsPdf函数。 - 使用
then块来处理成功创建 PDF。 在该代码块中,我们将向控制台记录一条成功信息。 - 使用
catch块来处理网站转换为 PDF 过程中发生的任何错误。 如果出现错误,我们会将错误信息记录到控制台。
将此代码片段集成到您的项目中,您就可以使用 NodeJS 和 Puppeteer 轻松地将 URL 转换为高质量的 PDF 文件。
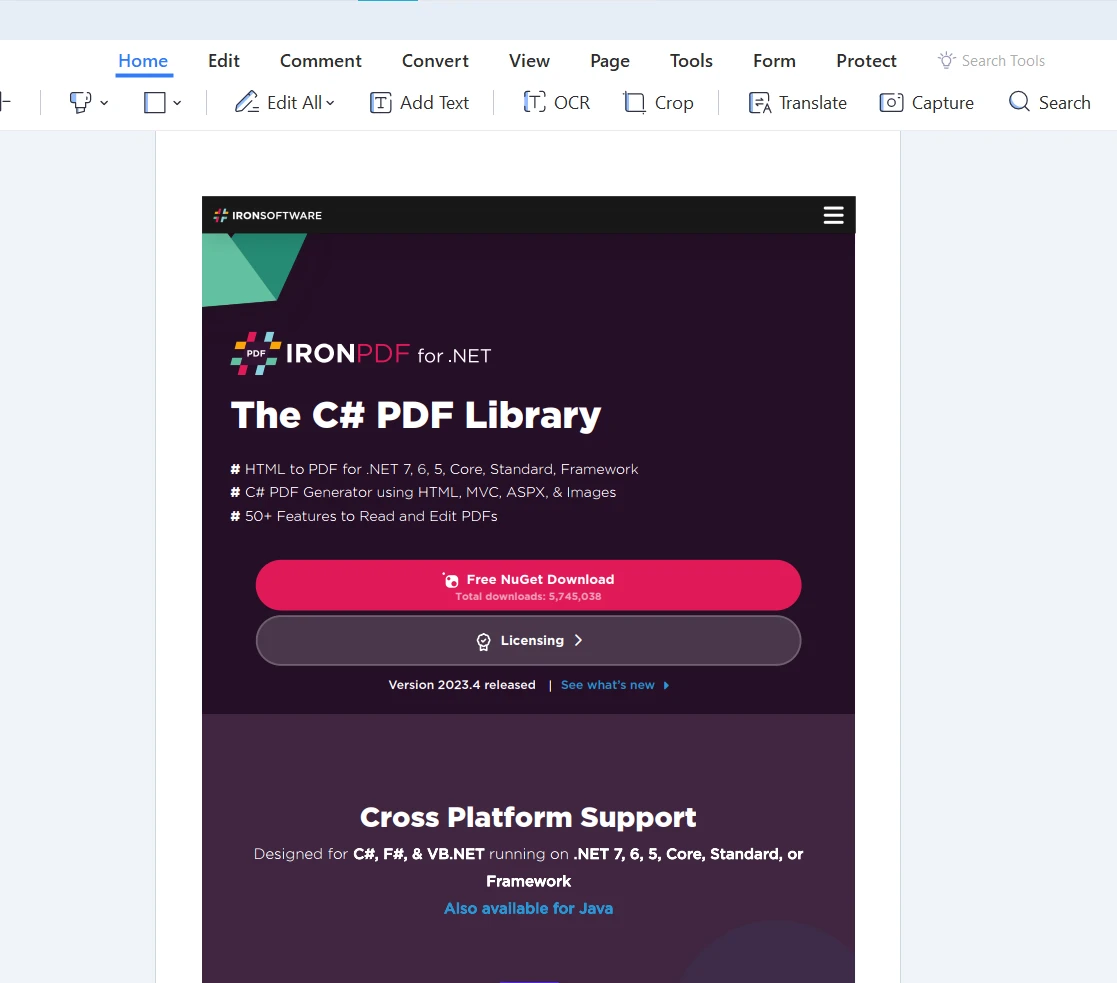
适用于 C# 开发人员的最佳 HTML To PDF 库
探索 IronPDF 是一个流行的 .NET 库,用于生成、编辑和提取 PDF 文件中的内容。 它为从 HTML、文本、图像和现有 PDF 文档创建 PDF 提供了简单高效的解决方案。 IronPDF 支持 .NET Core、.NET Framework 和 .NET 5.0+ 项目,是各种应用的多功能选择。
IronPDF 的主要功能
使用 IronPDF 将 HTML 转换为 PDF: IronPDF 允许您将 HTML 内容(包括 CSS)转换为 PDF 文件。 该功能可让您从网页或 HTML 模板创建像素完美的 PDF 文档。
URL 渲染: IronPDF 可以使用 URL 直接从服务器获取网页并将其转换为 PDF 文件,从而轻松地存档网页内容或从动态网页生成报告。
文本、图像和 PDF 合并: IronPDF 允许您将文本、图像和现有 PDF 文件合并到一个 PDF 文档中。 这一功能对于创建具有多个内容来源的复杂文档尤其有用。
PDF 操作: IronPDF 提供编辑现有 PDF 文件的工具,例如添加或删除页面、修改元数据,甚至从 PDF 文档中提取文本和图像。
结论
总之,生成和处理 PDF 文件是许多应用程序的共同要求,因此拥有合适的工具至关重要。 本文提供的解决方案,如使用 NodeJS 的 Puppeteer 或使用 .NET 的 IronPDF,提供了将 HTML 内容和 URL 转换为专业、高质量 PDF 文档的强大而高效的方法。
其中,IronPDF 凭借其丰富的功能集脱颖而出,成为 .NET 开发人员的首选。 IronPDF 提供免费试用版,允许您探索其功能。
用户还可以从 Iron Suite 软件包中获益,该软件包由五个专业 .NET 库组成,包括 IronXL、IronPDF、IronOCR 等。














